This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In this contributed article, Coral Trivedi, Product Manager at Fivetran, discusses how enterprises can get the most value from a datalake. The article discusses automation, security, pipelines and GSPR compliance issues.
This article was published as a part of the Data Science Blogathon. Introduction A datalake is a centralized repository for storing, processing, and securing massive amounts of structured, semi-structured, and unstructured data. It can store data in its native format and process any type of data, regardless of size.
This article was published as a part of the Data Science Blogathon. Introduction Today, DataLake is most commonly used to describe an ecosystem of IT tools and processes (infrastructure as a service, software as a service, etc.) that work together to make processing and storing large volumes of data easy.
Introduction You can access your Azure DataLake Storage Gen1 directly with the RapidMiner Studio. This is the feature offered by the Azure DataLake Storage connector. The post Connecting and Reading Data From Azure DataLake appeared first on Analytics Vidhya.
By their definition, the types of data it stores and how it can be accessible to users differ. This article will discuss some of the features and applications of data warehouses, data marts, and data […]. The post Data Warehouses, Data Marts and DataLakes appeared first on Analytics Vidhya.
Data collection is critical for businesses to make informed decisions, understand customers’ […]. The post DataLake or Data Warehouse- Which is Better? We can use it to represent facts, figures, and other information that we can use to make decisions. appeared first on Analytics Vidhya.
Azure DataLake Storage is capable of storing large quantities of structured, semi-structured, and unstructured data in […]. The post Introduction to Azure DataLake Storage Gen2 appeared first on Analytics Vidhya. Introduction ADLS Gen2 The ADLS Gen2 service is built upon Azure Storage as its foundation.
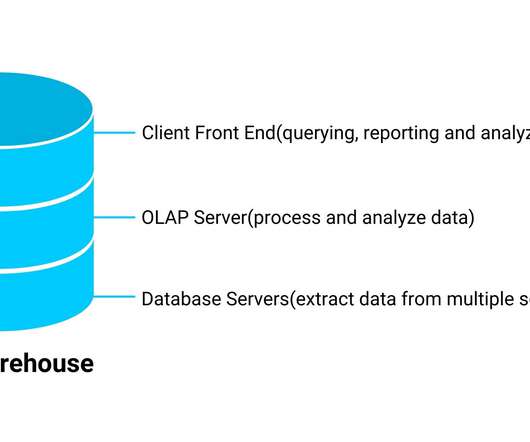
Overview Understand the meaning of datalake and data warehouse We will see what are the key differences between Data Warehouse and DataLake. The post What are the differences between DataLake and Data Warehouse? appeared first on Analytics Vidhya.
A comparative overview of data warehouses, datalakes, and data marts to help you make informed decisions on data storage solutions for your data architecture.
ArticleVideo Book This article was published as a part of the Data Science Blogathon. Introduction DataLake architecture for different use cases – Elegant. The post A Guide to Build your DataLake in AWS appeared first on Analytics Vidhya.
In this article, Ashutosh Kumar discusses the emergence of modern data solutions that have led to the development of ELT and ETL with unique features and advantages. ELT is more popular due to its ability to handle large and unstructured datasets like in datalakes.
Before seeing the practical implementation of the use case, let’s briefly introduce Azure DataLake Storage Gen2 and the Paramiko module. Introduction to Azure DataLake Storage Gen2 Azure DataLake Storage Gen2 is a data storage solution specially designed for big data […].
This article was published as a part of the Data Science Blogathon. Introduction A datalake is a central data repository that allows us to store all of our structured and unstructured data on a large scale. The post A Detailed Introduction on DataLakes and Delta Lakes appeared first on Analytics Vidhya.
Now, businesses are looking for different types of data storage to store and manage their data effectively. Organizations can collect millions of data, but if they’re lacking in storing that data, those efforts […] The post A Comprehensive Guide to DataLake vs. Data Warehouse appeared first on Analytics Vidhya.
Whereas a data warehouse will need rigid data modeling and definitions, a datalake can store different types and shapes of data. In a datalake, the schema of the data can be inferred when it’s read, providing the aforementioned flexibility.
High quality, reliable data forms the backbone for all successful data endeavors, from reporting and analytics to machine learning. Delta Lake is an open-source storage layer that solves many concerns around data. The post How to make datalakes reliable appeared first on Dataconomy.
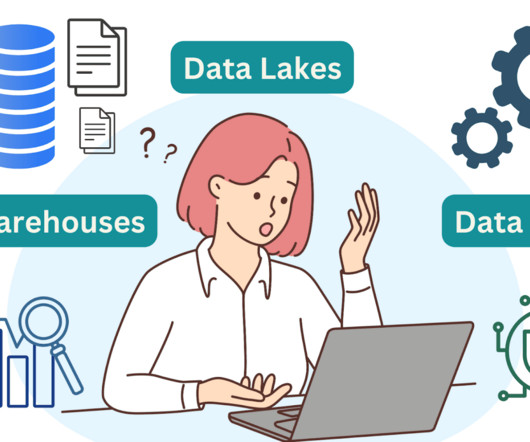
When it comes to data, there are two main types: datalakes and data warehouses. What is a datalake? An enormous amount of raw data is stored in its original format in a datalake until it is required for analytics applications. Which one is right for your business?
Executive Partner at Ethos Capital, touches on why data curation needs to be a priority. He discusses why datalakes ultimately end up being a burden and addresses the misconception that once data is stored, it is inherently useful along with the differences between curation and governance.
Image Source: GitHub Table of Contents What is Data Engineering? Components of Data Engineering Object Storage Object Storage MinIO Install Object Storage MinIO DataLake with Buckets Demo DataLake Management Conclusion References What is Data Engineering?
Introduction A datalake is a centralized and scalable repository storing structured and unstructured data. The need for a datalake arises from the growing volume, variety, and velocity of data companies need to manage and analyze.
Since data has been called the “oil” of the new economy, it’s easy to assume that more is better. You can never have too much oil, so the same goes for data too, right? Hence there has been a lot of hype about datalakes over the past few years.
We thank Vishnu Vettrivel, Founder, and Alex Thomas, Principal Data Scientist, for their contributions. This is a collaborative post from Databricks and wisecube.ai.
Introduction We are all pretty much familiar with the common modern cloud data warehouse model, which essentially provides a platform comprising a datalake (based on a cloud storage account such as Azure DataLake Storage Gen2) AND a data warehouse compute engine […].
Introduction Delta Lake is an open-source storage layer that brings datalakes to the world of Apache Spark. Delta Lakes provides an ACID transaction–compliant and cloud–native platform on top of cloud object stores such as Amazon S3, Microsoft Azure Storage, and Google Cloud Storage.
While there is a lot of discussion about the merits of data warehouses, not enough discussion centers around datalakes. We talked about enterprise data warehouses in the past, so let’s contrast them with datalakes. Both data warehouses and datalakes are used when storing big data.
Datalakes and data warehouses are probably the two most widely used structures for storing data. Data Warehouses and DataLakes in a Nutshell. A data warehouse is used as a central storage space for large amounts of structured data coming from various sources. Data Type and Processing.
Introduction Most of you would know the different approaches for building a data and analytics platform. You would have already worked on systems that used traditional warehouses or Hadoop-based datalakes. The post Warehouse, Lake or a Lakehouse – What’s Right for you? Selecting one among […].
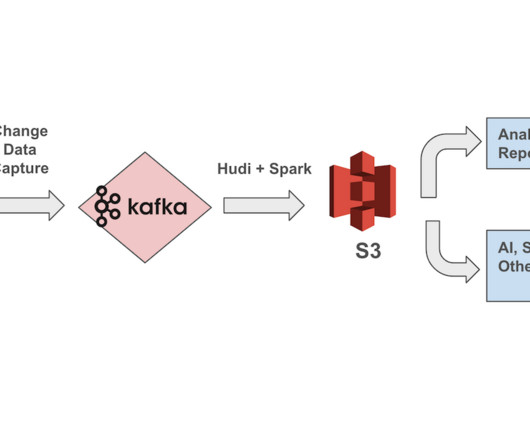
Be sure to check out his talk, “ Apache Kafka for Real-Time Machine Learning Without a DataLake ,” there! The combination of data streaming and machine learning (ML) enables you to build one scalable, reliable, but also simple infrastructure for all machine learning tasks using the Apache Kafka ecosystem.
Introduction In the modern data world, Lakehouse has become one of the most discussed topics for building a data platform. Enterprises have slowly started adopting Lakehouses for their data ecosystems as they offer cost efficiencies of datalakes and the performance of warehouses. […].
Perhaps one of the biggest perks is scalability, which simply means that with good datalake ingestion a small business can begin to handle bigger data numbers. The reality is businesses that are collecting data will likely be doing so on several levels. Proper Scalability. Uses Powerful Algorithms.
As organizations are maturing their data infrastructure and accumulating more data than ever before in their datalakes, Open and Reliable table formats.
For example, in the bank marketing use case, the management account would be responsible for setting up the organizational structure for the bank’s data and analytics teams, provisioning separate accounts for data governance, datalakes, and data science teams, and maintaining compliance with relevant financial regulations.
Azure DataLake Storage Gen2 is based on Azure Blob storage and offers a suite of big data analytics features. If you don’t understand the concept, you might want to check out our previous article on the difference between datalakes and data warehouses. Determine your preparedness.
While databases were the traditional way to store large amounts of data, a new storage method has developed that can store even more significant and varied amounts of data. These are called datalakes. What Are DataLakes? In many cases, this could mean using multiple security programs and platforms.
Introduction Enterprises here and now catalyze vast quantities of data, which can be a high-end source of business intelligence and insight when used appropriately. Delta Lake allows businesses to access and break new data down in real time.
However, the sheer volume, variety, and velocity of data can overwhelm traditional data management solutions. Enter the datalake – a centralized repository designed to store all types of data, whether structured, semi-structured, or unstructured.
While datalakes and data warehouses are both important Data Management tools, they serve very different purposes. If you’re trying to determine whether you need a datalake, a data warehouse, or possibly even both, you’ll want to understand the functionality of each tool and their differences.
Dremio, the unified lakehouse platform for self-service analytics and AI, announced a breakthrough in datalake analytics performance capabilities, extending its leadership in self-optimizing, autonomous Iceberg data management.
Recently we’ve seen lots of posts about a variety of different file formats for datalakes. There’s Delta Lake, Hudi, Iceberg, and QBeast, to name a few. It can be tough to keep track of all these datalake formats — let alone figure out why (or if!) And I’m curious to see if you’ll agree.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content