This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
It offers full BI-Stack Automation, from source to data warehouse through to frontend. It supports a holistic datamodel, allowing for rapid prototyping of various models. It also supports a wide range of data warehouses, analytical databases, datalakes, frontends, and pipelines/ETL.
DataLakes are among the most complex and sophisticated data storage and processing facilities we have available to us today as human beings. Analytics Magazine notes that datalakes are among the most useful tools that an enterprise may have at its disposal when aiming to compete with competitors via innovation.
In the ever-evolving world of big data, managing vast amounts of information efficiently has become a critical challenge for businesses across the globe. As datalakes gain prominence as a preferred solution for storing and processing enormous datasets, the need for effective data version control mechanisms becomes increasingly evident.
With the amount of data companies are using growing to unprecedented levels, organizations are grappling with the challenge of efficiently managing and deriving insights from these vast volumes of structured and unstructured data. What is a DataLake? Consistency of data throughout the datalake.
Data warehouse vs. datalake, each has their own unique advantages and disadvantages; it’s helpful to understand their similarities and differences. In this article, we’ll focus on a datalake vs. data warehouse. It is often used as a foundation for enterprise datalakes.
DagsHub DagsHub is a centralized Github-based platform that allows Machine Learning and Data Science teams to build, manage and collaborate on their projects. In addition to versioning code, teams can also version data, models, experiments and more. However, these tools have functional gaps for more advanced data workflows.
Certified data sources carefully chosen by site administrators and project leaders. Recommended data sources personally certified and/or automatically selected based on organizational usage patterns. Recommended database tables that are used frequently in data sources and workbooks published to your Tableau server.
Certified data sources carefully chosen by site administrators and project leaders. Recommended data sources personally certified and/or automatically selected based on organizational usage patterns. Recommended database tables that are used frequently in data sources and workbooks published to your Tableau server.
Unstructured data is information that doesn’t conform to a predefined schema or isn’t organized according to a preset datamodel. Text, images, audio, and videos are common examples of unstructured data. Understanding the data, categorizing it, storing it, and extracting insights from it can be challenging.
You can streamline the process of feature engineering and data preparation with SageMaker Data Wrangler and finish each stage of the data preparation workflow (including data selection, purification, exploration, visualization, and processing at scale) within a single visual interface.
Salesforce CDP creates holistic customer views by pulling data from internal and external databases and building unified customer profiles. Within TCRM’s dashboard designer, you can use three object types to create visualizations: Datalake objects provide access to data ingested from various connected data sources.
Salesforce CDP creates holistic customer views by pulling data from internal and external databases and building unified customer profiles. Within TCRM’s dashboard designer, you can use three object types to create visualizations: Datalake objects provide access to data ingested from various connected data sources.
Key features of cloud analytics solutions include: Datamodels , Processing applications, and Analytics models. Datamodels help visualize and organize data, processing applications handle large datasets efficiently, and analytics models aid in understanding complex data sets, laying the foundation for business intelligence.
Real-time Analytics & Built-in Machine Learning Models with a Single Database Akmal Chaudhri, Senior Technical Evangelist at SingleStore, explores the importance of delivering real-time experiences in today’s big data industry and how datamodels and algorithms rely on powerful and versatile data infrastructure.
It consolidates data from various systems, such as transactional databases, CRM platforms, and external data sources, enabling organizations to perform complex queries and derive insights. architecture for both structured and unstructured data.
Summary: The fundamentals of Data Engineering encompass essential practices like datamodelling, warehousing, pipelines, and integration. Understanding these concepts enables professionals to build robust systems that facilitate effective data management and insightful analysis. What is Data Engineering?
ODSC West 2024 showcased a wide range of talks and workshops from leading data science, AI, and machine learning experts. This blog highlights some of the most impactful AI slides from the world’s best data science instructors, focusing on cutting-edge advancements in AI, datamodeling, and deployment strategies.
Sources The sources involved could influence or determine the options available for the data ingestion tool(s). These could include other databases, datalakes, SaaS applications (e.g. Salesforce), Access databases, SharePoint, or Excel spreadsheets. Data flows from the current data platform to the destination.
And you should have experience working with big data platforms such as Hadoop or Apache Spark. Additionally, data science requires experience in SQL database coding and an ability to work with unstructured data of various types, such as video, audio, pictures and text.
This article is an excerpt from the book Expert DataModeling with Power BI, Third Edition by Soheil Bakhshi, a completely updated and revised edition of the bestselling guide to Power BI and datamodeling. in an enterprise data warehouse. What is a Datamart? A replacement for datasets.
They encompass all the origins from which data is collected, including: Internal Data Sources: These include databases, enterprise resource planning (ERP) systems, customer relationship management (CRM) systems, and flat files within an organization. Data can be structured (e.g., databases), semi-structured (e.g.,
In this article, we’ll explore how AI can transform unstructured data into actionable intelligence, empowering you to make informed decisions, enhance customer experiences, and stay ahead of the competition. What is Unstructured Data? Vector Databases With unprecedented data being generated, we must store and retrieve it efficiently.
Model versioning, lineage, and packaging : Can you version and reproduce models and experiments? Can you see the complete model lineage with data/models/experiments used downstream? Dolt Dolt is an open-source relational database system built on Git. Is it fast and reliable enough for your workflow?
There are 5 stages in unstructured data management: Data collection Data integration Data cleaning Data annotation and labeling Data preprocessing Data Collection The first stage in the unstructured data management workflow is data collection. mp4,webm, etc.), and audio files (.wav,mp3,acc,
The first generation of data architectures represented by enterprise data warehouse and business intelligence platforms were characterized by thousands of ETL jobs, tables, and reports that only a small group of specialized data engineers understood, resulting in an under-realized positive impact on the business.
Challenges associated with these stages involve not knowing all touchpoints where data is persisted, maintaining a data pre-processing pipeline for document chunking, choosing a chunking strategy, vector database, and indexing strategy, generating embeddings, and any manual steps to purge data from vector stores and keep it in sync with source data.
We need robust versioning for data, models, code, and preferably even the internal state of applications—think Git on steroids to answer inevitable questions: What changed? ML use cases rarely dictate the master data management solution, so the ML stack needs to integrate with existing data warehouses.
This session provides a gentle introduction to vector databases. You’ll start by demystifying what vector databases are, with clear definitions, simple explanations, and real-world examples of popular vector databases.
Built for integration, scalability, governance, and industry-leading security, Snowflake optimizes how you can leverage your organization’s data, providing the following benefits: Built to Be a Source of Truth Snowflake is built to simplify data integration wherever it lives and whatever form it takes.
Understand the fundamentals of data engineering: To become an Azure Data Engineer, you must first understand the concepts and principles of data engineering. Knowledge of datamodeling, warehousing, integration, pipelines, and transformation is required. Data Warehousing concepts and knowledge should be strong.
Summary: A data warehouse is a central information hub that stores and organizes vast amounts of data from different sources within an organization. Unlike operational databases focused on daily tasks, data warehouses are designed for analysis, enabling historical trend exploration and informed decision-making.
Schema Integration Schema integration deals with reconciling data stored in different database schemas or structures. It involves mapping and transforming data elements to align with a unified schema. It ensures that the integrated data is available for analysis and reporting. Wrapping It Up !!!
It includes processes that trace and document the origin of data, models and associated metadata and pipelines for audits. This type of next-generation data store combines a datalake’s flexibility with a data warehouse’s performance and lets you scale AI workloads no matter where they reside.
Thus, the solution allows for scaling data workloads independently from one another and seamlessly handling data warehousing, datalakes , data sharing, and engineering. Snowflake Database Pros Extensive Storage Opportunities Snowflake provides affordability, scalability, and a user-friendly interface.
Just as you need data about finances for effective financial management, you need data about data (metadata) for effective data management. You can’t manage data without metadata. But data catalogs do much more. Figure 1 shows a logical datamodel that represents typical metadata content of a data catalog.
Dataflows represent a cloud-based technology designed for data preparation and transformation purposes. Dataflows have different connectors to retrieve data, including databases, Excel files, APIs, and other similar sources, along with data manipulations that are performed using Online Power Query Editor.
Must Read Blogs: Exploring the Power of Data Warehouse Functionality. DataLakes Vs. Data Warehouse: Its significance and relevance in the data world. Exploring Differences: Database vs Data Warehouse. Its clear structure and ease of use facilitate efficient data analysis and reporting.
Cloudera Cloudera is a cloud-based platform that provides businesses with the tools they need to manage and analyze data. They offer a variety of services, including data warehousing, datalakes, and machine learning. ArangoDB ArangoDB is a company that provides a database platform for graph and document data.
If you will ask data professionals about what is the most challenging part of their day to day work, you will likely discover their concerns around managing different aspects of data before they get to graduate to the datamodeling stage. Relational database connectors are available. Talend Free to use.
Introduction: The Customer DataModeling Dilemma You know, that thing we’ve been doing for years, trying to capture the essence of our customers in neat little profile boxes? For years, we’ve been obsessed with creating these grand, top-down customer datamodels. Yeah, that one.
This post dives deep into Amazon Bedrock Knowledge Bases , which helps with the storage and retrieval of data in vector databases for RAG-based workflows, with the objective to improve large language model (LLM) responses for inference involving an organization’s datasets. The LLM response is passed back to the agent.
A generative AI foundation can provide primitives such as models, vector databases, and guardrails as a service and higher-level services for defining AI workflows, agents and multi-agents, tools, and also a catalog to encourage reuse. Data quality is ownership of the consuming applications or data producers.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



























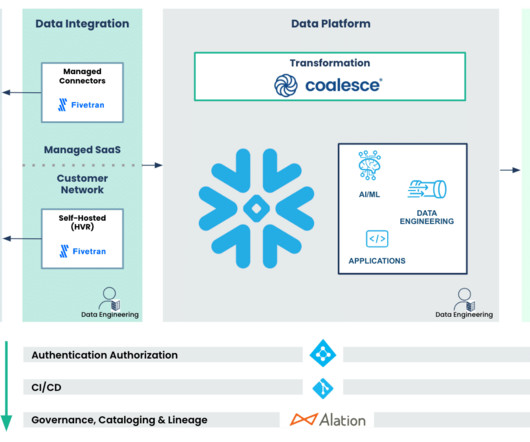



















Let's personalize your content