This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
With the amount of data companies are using growing to unprecedented levels, organizations are grappling with the challenge of efficiently managing and deriving insights from these vast volumes of structured and unstructured data. What is a DataLake? Consistency of data throughout the datalake.
When it was no longer a hard requirement that a physical datamodel be created upon the ingestion of data, there was a resulting drop in richness of the description and consistency of the data stored in Hadoop. You did not have to understand or prepare the data to get it into Hadoop, so people rarely did.
Key features of cloud analytics solutions include: Datamodels , Processing applications, and Analytics models. Datamodels help visualize and organize data, processing applications handle large datasets efficiently, and analytics models aid in understanding complex data sets, laying the foundation for business intelligence.
You can find instructions on how to do this in the AWS documentation for your chosen SDK. AWS credentials – Configure your AWS credentials in your development environment to authenticate with AWS services. We walk through a Python example in this post.
DagsHub DagsHub is a centralized Github-based platform that allows Machine Learning and Data Science teams to build, manage and collaborate on their projects. In addition to versioning code, teams can also version data, models, experiments and more. This can also make the learning process challenging.
Unstructured data is information that doesn’t conform to a predefined schema or isn’t organized according to a preset datamodel. Text, images, audio, and videos are common examples of unstructured data. The steps of the workflow are as follows: Integrated AI services extract data from the unstructured data.
It includes processes that trace and document the origin of data, models and associated metadata and pipelines for audits. How to scale AL and ML with built-in governance A fit-for-purpose data store built on an open lakehouse architecture allows you to scale AI and ML while providing built-in governance tools.
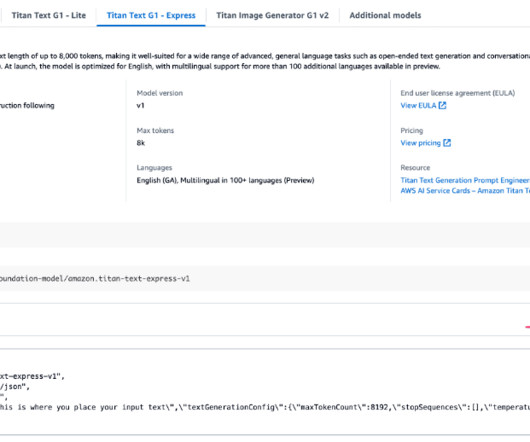
Challenges and considerations with RAG architectures Typical RAG architecture at a high level involves three stages: Source data pre-processing Generating embeddings using an embedding LLM Storing the embeddings in a vector store. Vector embeddings include the numeric representations of text data within your documents.
To combine the collected data, you can integrate different data producers into a datalake as a repository. A central repository for unstructured data is beneficial for tasks like analytics and data virtualization. Data Cleaning The next step is to clean the data after ingesting it into the datalake.
A common problem solved by phData is the migration from an existing data platform to the Snowflake Data Cloud , in the best possible manner. Sources The sources involved could influence or determine the options available for the data ingestion tool(s). These could include other databases, datalakes, SaaS applications (e.g.
User support arrangements Consider the availability and quality of support from the provider or vendor, including documentation, tutorials, forums, customer service, etc. Check out the Kubeflow documentation. Metaflow Metaflow helps data scientists and machine learning engineers build, manage, and deploy data science projects.
The traditional data science workflow , as defined by Joe Blitzstein and Hanspeter Pfister of Harvard University, contains 5 key steps: Ask a question. Get the data. Explore the data. Model the data. A data catalog can assist directly with every step, but model development.
External Data Sources: These can be market research data, social media feeds, or third-party databases that provide additional insights. Data can be structured (e.g., documents and images). The diversity of data sources allows organizations to create a comprehensive view of their operations and market conditions.
In this article, we’ll explore how AI can transform unstructured data into actionable intelligence, empowering you to make informed decisions, enhance customer experiences, and stay ahead of the competition. What is Unstructured Data? These AI models use multimedia data to understand and improve more complicated information.
Cloudera Cloudera is a cloud-based platform that provides businesses with the tools they need to manage and analyze data. They offer a variety of services, including data warehousing, datalakes, and machine learning. ArangoDB ArangoDB is a company that provides a database platform for graph and documentdata.
Attach a Common DataModel Folder (preview) When you create a Dataflow from a CDM folder, you can establish a connection to a table authored in the Common DataModel (CDM) format by another application. With the import option, users can create a new version of the Dataflow while the original Dataflow remains unchanged.
Thus, the solution allows for scaling data workloads independently from one another and seamlessly handling data warehousing, datalakes , data sharing, and engineering. Therefore, you’ll be empowered to truncate and reprocess data if bugs are detected and provide an excellent raw data source for data scientists.
How do you get executives to understand the value of data governance? First, document your successes of good data, and how it happened. Share stories of data in good times and in bad (pictures help!). We’re planning data governance that’s primarily focused on compliance, data privacy, and protection.
A typical machine learning pipeline with various stages highlighted | Source: Author Common types of machine learning pipelines In line with the stages of the ML workflow (data, model, and production), an ML pipeline comprises three different pipelines that solve different workflow stages. They include: 1 Data (or input) pipeline.
Use cases for vector databases for RAG In the context of RAG architectures, the external knowledge can come from relational databases, search and document stores, or other data stores. A RAG workflow with knowledge bases has two main steps: data preprocessing and runtime execution. All these steps are managed by Amazon Bedrock.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


























Let's personalize your content