This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In the ever-evolving world of big data, managing vast amounts of information efficiently has become a critical challenge for businesses across the globe. Understanding DataLakes A datalake is a centralized repository that stores structured, semi-structured, and unstructured data in its raw format.
With the amount of data companies are using growing to unprecedented levels, organizations are grappling with the challenge of efficiently managing and deriving insights from these vast volumes of structured and unstructured data. What is a DataLake? Consistency of data throughout the datalake.
As cloud computing platforms make it possible to perform advanced analytics on ever larger and more diverse data sets, new and innovative approaches have emerged for storing, preprocessing, and analyzing information. In this article, we’ll focus on a datalake vs. data warehouse.
When it was no longer a hard requirement that a physical datamodel be created upon the ingestion of data, there was a resulting drop in richness of the description and consistency of the data stored in Hadoop. You did not have to understand or prepare the data to get it into Hadoop, so people rarely did.
Cloud analytics is the art and science of mining insights from data stored in cloud-based platforms. By tapping into the power of cloud technology, organizations can efficiently analyze large datasets, uncover hidden patterns, predict future trends, and make informed decisions to drive their businesses forward.
Data and governance foundations – This function uses a data mesh architecture for setting up and operating the datalake, central feature store, and data governance foundations to enable fine-grained data access. This framework considers multiple personas and services to govern the ML lifecycle at scale.
Data auditing and compliance Almost each company face data protection regulations such as GDPR, forcing them to store certain information in order to demonstrate compliance and history of data sources. In this scenario, data versioning can help companies in both internal and external audits process.
You can streamline the process of feature engineering and data preparation with SageMaker Data Wrangler and finish each stage of the data preparation workflow (including data selection, purification, exploration, visualization, and processing at scale) within a single visual interface.
Unstructured data is information that doesn’t conform to a predefined schema or isn’t organized according to a preset datamodel. Unstructured information may have a little or a lot of structure but in ways that are unexpected or inconsistent. These services write the output to a datalake.
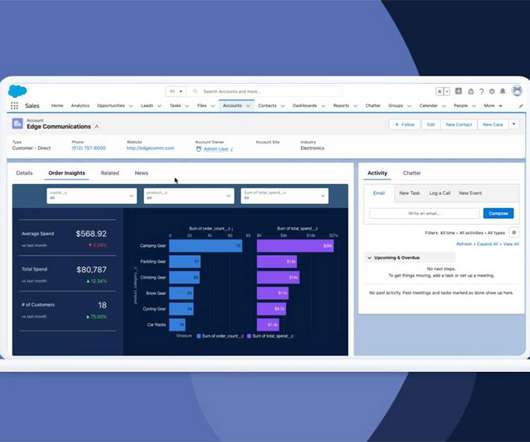
Within TCRM’s dashboard designer, you can use three object types to create visualizations: Datalake objects provide access to data ingested from various connected data sources. These allow you to build dashboards that profile, analyze, and monitor data coming into Salesforce CDP.
Within TCRM’s dashboard designer, you can use three object types to create visualizations: Datalake objects provide access to data ingested from various connected data sources. These allow you to build dashboards that profile, analyze, and monitor data coming into Salesforce CDP.
To get the data, you will need to follow the instructions in the article: Create a Data Solution on Azure Synapse Analytics with Snapshot Serengeti — Part 1 — Microsoft Community Hub, where you will load data into Azure DataLake via Azure Synapse. Lastly, upload the data from Azure Subscription.
Using Azure ML to Train a Serengeti DataModel, Fast Option Pricing with DL, and How To Connect a GPU to a Container Using Azure ML to Train a Serengeti DataModel for Animal Identification In this article, we will cover how you can train a model using Notebooks in Azure Machine Learning Studio.
The General Data Protection Regulation (GDPR) right to be forgotten, also known as the right to erasure, gives individuals the right to request the deletion of their personally identifiable information (PII) data held by organizations. Example: customer information pertaining to the email address art@venere.org.
Tableau helps strike the necessary balance to access, improve data quality, and prepare and modeldata for analytics use cases, while writing-back data to data management sources. Analytics data catalog. Review quality and structural information on data and data sources to better monitor and curate for use.
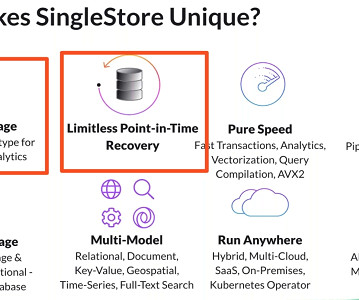
Real-time Analytics & Built-in Machine Learning Models with a Single Database Akmal Chaudhri, Senior Technical Evangelist at SingleStore, explores the importance of delivering real-time experiences in today’s big data industry and how datamodels and algorithms rely on powerful and versatile data infrastructure.
Tableau helps strike the necessary balance to access, improve data quality, and prepare and modeldata for analytics use cases, while writing-back data to data management sources. Analytics data catalog. Review quality and structural information on data and data sources to better monitor and curate for use.
Summary: Understanding Business Intelligence Architecture is essential for organizations seeking to harness data effectively. This framework includes components like data sources, integration, storage, analysis, visualization, and information delivery. DataLakes: These store raw, unprocessed data in its original format.
Thats why we use advanced technology and data analytics to streamline every step of the homeownership experience, from application to closing. Apache HBase was employed to offer real-time key-based access to data. HBase is employed to offer real-time key-based access to data.
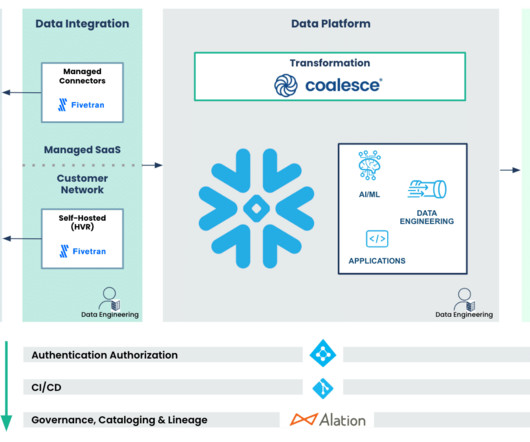
Those data architectures were brittle, complex, and time intensive to build and maintain, requiring data duplication and bloated data warehouse investments. As a result, making informed business decisions was frustrating and time consuming. . Built-in connectors bring in data from every single channel.
Those data architectures were brittle, complex, and time intensive to build and maintain, requiring data duplication and bloated data warehouse investments. As a result, making informed business decisions was frustrating and time consuming. . Built-in connectors bring in data from every single channel.
To pursue a data science career, you need a deep understanding and expansive knowledge of machine learning and AI. js and Tableau Data science, data analytics and IBM Practicing data science isn’t without its challenges. Watsonx comprises of three powerful components: the watsonx.ai
Summary: The fundamentals of Data Engineering encompass essential practices like datamodelling, warehousing, pipelines, and integration. Understanding these concepts enables professionals to build robust systems that facilitate effective data management and insightful analysis. What is Data Engineering?
Take an Inventory Taking an inventory is an important step for the following reasons; It informs the scope of a Snowflake migration. It’s useful in describing the activity and size of the data. Sources The sources involved could influence or determine the options available for the data ingestion tool(s).
By maintaining historical data from disparate locations, a data warehouse creates a foundation for trend analysis and strategic decision-making. How to Choose a Data Warehouse for Your Big Data Choosing a data warehouse for big data storage necessitates a thorough assessment of your unique requirements.
In this article, we’ll explore how AI can transform unstructured data into actionable intelligence, empowering you to make informed decisions, enhance customer experiences, and stay ahead of the competition. What is Unstructured Data? We only have the video without any information.
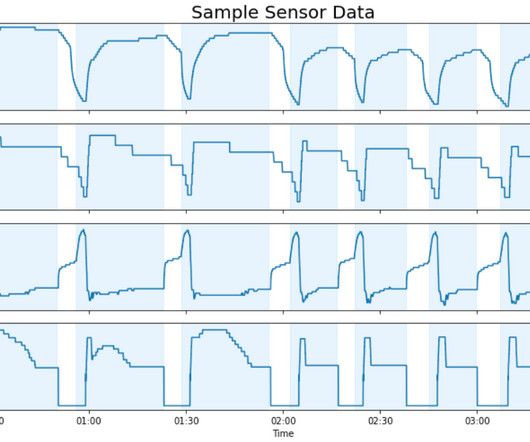
In LnW Connect, an encryption process was designed to provide a secure and reliable mechanism for the data to be brought into an AWS datalake for predictive modeling. All the names in the table are anonymized to protect customer information.) Increasing the number of bins preserves more temporal information.
data, models…). reports, dashboards, charts, data…). In our industry, we tend to celebrate the hero data scientist or lone analyst, but what makes a data-driven organization successful are shared insights. It may be more surprising that Collaboration was a key theme for BI end users.
How to leverage Generative AI to manage unstructured data Benefits of applying proper unstructured data management processes to your AI/ML project. What is Unstructured Data? One thing is clear : unstructured data doesn’t mean it lacks information.
This article is an excerpt from the book Expert DataModeling with Power BI, Third Edition by Soheil Bakhshi, a completely updated and revised edition of the bestselling guide to Power BI and datamodeling. Then we have some other ETL processes to constantly land the past 5 years of data into the Datamarts.
Summary: A data warehouse is a central information hub that stores and organizes vast amounts of data from different sources within an organization. Unlike operational databases focused on daily tasks, data warehouses are designed for analysis, enabling historical trend exploration and informed decision-making.
The traditional data science workflow , as defined by Joe Blitzstein and Hanspeter Pfister of Harvard University, contains 5 key steps: Ask a question. Get the data. Explore the data. Model the data. A data catalog can assist directly with every step, but model development.
The cloud is especially well-suited to large-scale storage and big data analytics, due in part to its capacity to handle intensive computing requirements at scale. BI platforms and data warehouses have been replaced by modern datalakes and cloud analytics solutions. Secure data exchange takes on much greater importance.
This dramatically reduced the size of our dataset from over 8 million data points per day per unit down to roughly 1,200. Crucially, this approach preserves predictive information about unit behavior with a much smaller data footprint. The output of the AWS Glue job is a summary of unit behavior for each cycle.
It includes processes that trace and document the origin of data, models and associated metadata and pipelines for audits. Most of today’s largest foundation models, including the large language model (LLM) powering ChatGPT, have been trained on information culled from the internet.
A collection of facts from which inferences can be made is called data. It is the basis on which factual information is derived, providing relevant results to the end users. Data is the cornerstone of contemporary society and is crucial to many facets of people’s lives.
In an earlier blog, I defined a data catalog as “a collection of metadata, combined with data management and search tools, that helps analysts and other data users to find the data that they need, serves as an inventory of available data, and provides information to evaluate fitness data for intended uses.”.
We need robust versioning for data, models, code, and preferably even the internal state of applications—think Git on steroids to answer inevitable questions: What changed? ML use cases rarely dictate the master data management solution, so the ML stack needs to integrate with existing data warehouses.
Today, companies are facing a continual need to store tremendous volumes of data. The demand for information repositories enabling business intelligence and analytics is growing exponentially, giving birth to cloud solutions. The tool’s high storage capacity is perfect for keeping large information volumes.
Those data architectures were brittle, complex, and time intensive to build and maintain, requiring data duplication and bloated data warehouse investments. As a result, making informed business decisions was frustrating and time consuming. Salesforce Data Cloud for Tableau solves those challenges.
Built for integration, scalability, governance, and industry-leading security, Snowflake optimizes how you can leverage your organization’s data, providing the following benefits: Built to Be a Source of Truth Snowflake is built to simplify data integration wherever it lives and whatever form it takes.
This announcement is interesting and causes some of us in the tech industry to step back and consider many of the factors involved in providing data technology […]. The post Where Is the Data Technology Industry Headed? Click here to learn more about Heine Krog Iversen.
However, most enterprises are hampered by data strategies that leave teams flat-footed when […]. The post Why the Next Generation of Data Management Begins with Data Fabrics appeared first on DATAVERSITY. Click to learn more about author Kendall Clark. The mandate for IT to deliver business value has never been stronger.
Model versioning, lineage, and packaging : Can you version and reproduce models and experiments? Can you see the complete model lineage with data/models/experiments used downstream? Comparing and visualizing experiments and models : what visualizations are supported, and does it have parallel coordinate plots?
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content