This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Customers of every size and industry are innovating on AWS by infusing machine learning (ML) into their products and services. Recent developments in generative AI models have further sped up the need of ML adoption across industries.
Unstructured data is information that doesn’t conform to a predefined schema or isn’t organized according to a preset datamodel. Text, images, audio, and videos are common examples of unstructured data. Additionally, we show how to use AWS AI/ML services for analyzing unstructured data.
Article on Azure ML by Bethany Jepchumba and Josh Ndemenge of Microsoft In this article, I will cover how you can train a model using Notebooks in Azure Machine Learning Studio. At the end of this article, you will learn how to use Pytorch pretrained DenseNet 201 model to classify different animals into 48 distinct categories.
Data exploration and model development were conducted using well-known machine learning (ML) tools such as Jupyter or Apache Zeppelin notebooks. Apache Hive was used to provide a tabular interface to data stored in HDFS, and to integrate with Apache Spark SQL. This also led to a backlog of data that needed to be ingested.
As with many burgeoning fields and disciplines, we don’t yet have a shared canonical infrastructure stack or best practices for developing and deploying data-intensive applications. What does a modern technology stack for streamlined ML processes look like? Why: Data Makes It Different. All ML projects are software projects.
Using Azure ML to Train a Serengeti DataModel, Fast Option Pricing with DL, and How To Connect a GPU to a Container Using Azure ML to Train a Serengeti DataModel for Animal Identification In this article, we will cover how you can train a model using Notebooks in Azure Machine Learning Studio.
Alignment to other tools in the organization’s tech stack Consider how well the MLOps tool integrates with your existing tools and workflows, such as data sources, data engineering platforms, code repositories, CI/CD pipelines, monitoring systems, etc. and Pandas or Apache Spark DataFrames.
DagsHub DagsHub is a centralized Github-based platform that allows Machine Learning and Data Science teams to build, manage and collaborate on their projects. In addition to versioning code, teams can also version data, models, experiments and more. DVC can efficiently handle large files and machine learning models.
Amazon SageMaker Data Wrangler reduces the time it takes to collect and prepare data for machine learning (ML) from weeks to minutes. Data is frequently kept in datalakes that can be managed by AWS Lake Formation , giving you the ability to implement fine-grained access control using a straightforward grant or revoke procedure.
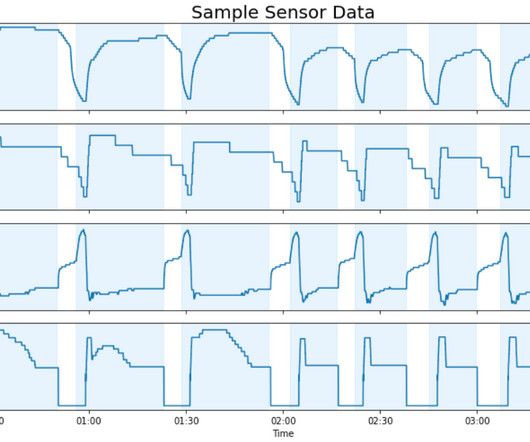
In order to improve our equipment reliability, we partnered with the Amazon Machine Learning Solutions Lab to develop a custom machine learning (ML) model capable of predicting equipment issues prior to failure. Our teams developed a framework for processing over 50 TB of historical sensor data and predicting faults with 91% precision.
Utilizing data streamed through LnW Connect, L&W aims to create better gaming experience for their end-users as well as bring more value to their casino customers. Predictive maintenance is a common ML use case for businesses with physical equipment or machinery assets.
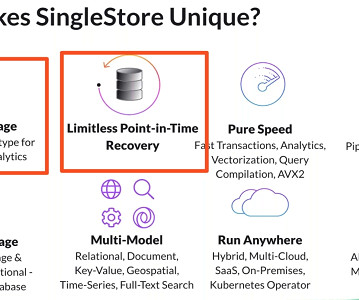
Real-time Analytics & Built-in Machine Learning Models with a Single Database Akmal Chaudhri, Senior Technical Evangelist at SingleStore, explores the importance of delivering real-time experiences in today’s big data industry and how datamodels and algorithms rely on powerful and versatile data infrastructure.
It includes processes that trace and document the origin of data, models and associated metadata and pipelines for audits. An AI governance framework ensures the ethical, responsible and transparent use of AI and machine learning (ML). ” Are foundation models trustworthy?
Managing unstructured data is essential for the success of machine learning (ML) projects. Without structure, data is difficult to analyze and extracting meaningful insights and patterns is challenging. This article will discuss managing unstructured data for AI and ML projects. What is Unstructured Data?
In this article, we’ll explore how AI can transform unstructured data into actionable intelligence, empowering you to make informed decisions, enhance customer experiences, and stay ahead of the competition. What is Unstructured Data? Word2Vec , GloVe , and BERT are good sources of embedding generation for textual data.
He has been helping the customers over the last 20 years in building the enterprise data strategies, advising customers on Generative AI, cloud implementations, migrations, reference architecture creation, datamodeling best practices, datalake/warehouses architectures.
Self-Service Analytics User-friendly interfaces and self-service analytics tools empower business users to explore data independently without relying on IT departments. Best Practices for Maximizing Data Warehouse Functionality A data warehouse, brimming with historical data, holds immense potential for unlocking valuable insights.
Difficulty in moving non-SAP data into SAP for analytics which encourages data silos and shadow IT practices as business users search for ways to extract the data (which has data governance implications). Additionally, change data markers are not available for many of these tables.
Attach a Common DataModel Folder (preview) When you create a Dataflow from a CDM folder, you can establish a connection to a table authored in the Common DataModel (CDM) format by another application. With the import option, users can create a new version of the Dataflow while the original Dataflow remains unchanged.
Thus, the solution allows for scaling data workloads independently from one another and seamlessly handling data warehousing, datalakes , data sharing, and engineering. Machine Learning Integration Opportunities Organizations harness machine learning (ML) algorithms to make forecasts on the data.
Understand the fundamentals of data engineering: To become an Azure Data Engineer, you must first understand the concepts and principles of data engineering. Knowledge of datamodeling, warehousing, integration, pipelines, and transformation is required. Data Warehousing concepts and knowledge should be strong.
If you will ask data professionals about what is the most challenging part of their day to day work, you will likely discover their concerns around managing different aspects of data before they get to graduate to the datamodeling stage. You can learn more about the benefits of having a data pipeline in place here.
One of the most prevalent complaints we hear from ML engineers in the community is how costly and error-prone it is to manually go through the ML workflow of building and deploying models. Building end-to-end machine learning pipelines lets ML engineers build once, rerun, and reuse many times.
Introduction: The Customer DataModeling Dilemma You know, that thing we’ve been doing for years, trying to capture the essence of our customers in neat little profile boxes? For years, we’ve been obsessed with creating these grand, top-down customer datamodels. Yeah, that one.
This makes it a popular option for a vector database when using Amazon Bedrock Knowledge Bases, because it makes it straightforward to build modern machine learning (ML) augmented search experiences and generative AI applications without having to manage the underlying vector database infrastructure. Data Architect, DataLake at AWS.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






























Let's personalize your content