
Data Preparation with SQL Cheatsheet
KDnuggets
JUNE 27, 2022
If your raw data is in a SQL-based data lake, why spend the time and money to export the data into a new platform for data prep?

KDnuggets
JUNE 27, 2022
If your raw data is in a SQL-based data lake, why spend the time and money to export the data into a new platform for data prep?

Data Science Dojo
JANUARY 12, 2023
When it comes to data, there are two main types: data lakes and data warehouses. What is a data lake? An enormous amount of raw data is stored in its original format in a data lake until it is required for analytics applications. Which one is right for your business?
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.

Dataconomy
MARCH 4, 2025
The data mining process The data mining process is structured into four primary stages: data gathering, data preparation, data mining, and data analysis and interpretation. Each stage is crucial for deriving meaningful insights from data.

Data Science Dojo
SEPTEMBER 11, 2024
With this full-fledged solution, you don’t have to spend all your time and effort combining different services or duplicating data. Overview of One Lake Fabric features a lake-centric architecture, with a central repository known as OneLake.

DagsHub
FEBRUARY 29, 2024
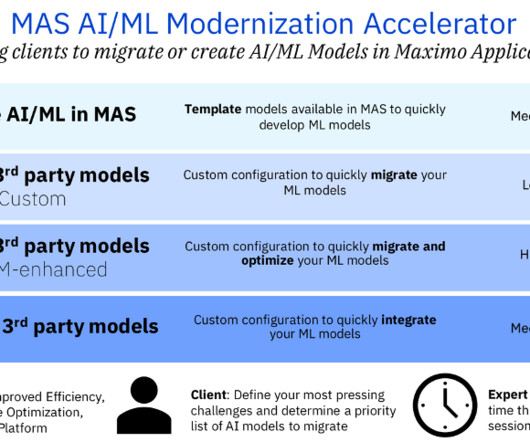
Data, is therefore, essential to the quality and performance of machine learning models. This makes data preparation for machine learning all the more critical, so that the models generate reliable and accurate predictions and drive business value for the organization. Why do you need Data Preparation for Machine Learning?

AWS Machine Learning Blog
SEPTEMBER 27, 2024
Data preparation SageMaker Ground Truth employs a human workforce made up of Northpower volunteers to annotate a set of 10,000 images. The model was then fine-tuned with training data from the data preparation stage. The sunburst graph below is a visualization of this classification.

DECEMBER 11, 2024
Many of these applications are complex to build because they require collaboration across teams and the integration of data, tools, and services. Data engineers use data warehouses, data lakes, and analytics tools to load, transform, clean, and aggregate data. Big Data Architect.

Expert insights. Personalized for you.








































Let's personalize your content