This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
When it comes to data, there are two main types: datalakes and data warehouses. What is a datalake? An enormous amount of raw data is stored in its original format in a datalake until it is required for analytics applications. Which one is right for your business?
With this full-fledged solution, you don’t have to spend all your time and effort combining different services or duplicating data. Overview of One Lake Fabric features a lake-centric architecture, with a central repository known as OneLake. Now, we can save the data as delta tables to use later for sales analytics.
It’s an integral part of data analytics and plays a crucial role in datascience. By utilizing algorithms and statistical models, data mining transforms raw data into actionable insights. Each stage is crucial for deriving meaningful insights from data.
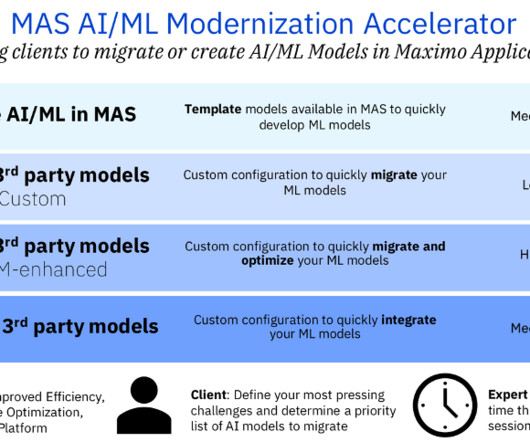
All data scientists could leverage our patterns during an engagement. These patterns ensure consistency, efficiency, and collaboration among datascience teams, making the MAS AI/ML modernization process smoother and scalable. We are leveraging Air Compressors data, but the solutions are generalizable.
Datapreparation SageMaker Ground Truth employs a human workforce made up of Northpower volunteers to annotate a set of 10,000 images. The model was then fine-tuned with training data from the datapreparation stage. The sunburst graph below is a visualization of this classification.
You can streamline the process of feature engineering and datapreparation with SageMaker Data Wrangler and finish each stage of the datapreparation workflow (including data selection, purification, exploration, visualization, and processing at scale) within a single visual interface.
These teams are as follows: Advanced analytics team (datalake and data mesh) – Data engineers are responsible for preparing and ingesting data from multiple sources, building ETL (extract, transform, and load) pipelines to curate and catalog the data, and prepare the necessary historical data for the ML use cases.
Manager DataScience at Marubeni Power International. Data collection and ingestion The data collection and ingestion layer connects to all upstream data sources and loads the data into the datalake. Datapreparation As with most ML use cases, datapreparation plays a critical role.
Businesses require Data Scientists to perform Data Mining processes and invoke valuable data insights using different software and tools. What is Data Mining and how is it related to DataScience ? What is Data Mining? Further, data transformation is also a process ensuring consistent data sets.
Increased operational efficiency benefits Reduced datapreparation time : OLAP datapreparation capabilities streamline data analysis processes, saving time and resources. IBM watsonx.data is the next generation OLAP system that can help you make the most of your data.
ODSC West 2024 showcased a wide range of talks and workshops from leading datascience, AI, and machine learning experts. This blog highlights some of the most impactful AI slides from the world’s best datascience instructors, focusing on cutting-edge advancements in AI, data modeling, and deployment strategies.
No-code/low-code experience using a diagram view in the datapreparation layer similar to Dataflows. Building business-focussed semantic layers in the cloud (the Power BI Service) with data modeling capabilities, such as managing relationships, creating measures, defining incremental refresh, and creating and managing RLS.
The service streamlines ML development and production workflows (MLOps) across BMW by providing a cost-efficient and scalable development environment that facilitates seamless collaboration between datascience and engineering teams worldwide. This results in faster experimentation and shorter idea validation cycles.
See also Thoughtworks’s guide to Evaluating MLOps Platforms End-to-end MLOps platforms End-to-end MLOps platforms provide a unified ecosystem that streamlines the entire ML workflow, from datapreparation and model development to deployment and monitoring. Check out the Metaflow Docs. neptune.ai
Summary: This blog provides a comprehensive roadmap for aspiring Azure Data Scientists, outlining the essential skills, certifications, and steps to build a successful career in DataScience using Microsoft Azure. Storage Solutions: Secure and scalable storage options like Azure Blob Storage and Azure DataLake Storage.
In most cases data catalogs are used in three distinct ways. Data Catalogs for DataScience & Engineering – Data catalogs that are primarily used for datascience and engineering are typically used by very experienced data practitioners. Key Features of a Data Catalog.
By supporting open-source frameworks and tools for code-based, automated and visual datascience capabilities — all in a secure, trusted studio environment — we’re already seeing excitement from companies ready to use both foundation models and machine learning to accomplish key tasks.
It offers its users advanced machine learning, data management , and generative AI capabilities to train, validate, tune and deploy AI systems across the business with speed, trusted data, and governance. It helps facilitate the entire data and AI lifecycle, from datapreparation to model development, deployment and monitoring.
Amazon Redshift uses SQL to analyze structured and semi-structured data across data warehouses, operational databases, and datalakes, using AWS-designed hardware and ML to deliver the best price-performance at any scale. If you want to do the process in a low-code/no-code way, you can follow option C.
In LnW Connect, an encryption process was designed to provide a secure and reliable mechanism for the data to be brought into an AWS datalake for predictive modeling. Data preprocessing and feature engineering In this section, we discuss our methods for datapreparation and feature engineering.
Role of Data Engineers in the Data Ecosystem Data Engineers play a crucial role in the data ecosystem by bridging the gap between raw data and actionable insights. They are responsible for building and maintaining data architectures, which include databases, data warehouses, and datalakes.
Data Engineering plays a critical role in enabling organizations to efficiently collect, store, process, and analyze large volumes of data. It is a field of expertise within the broader domain of data management and DataScience. Best Data Engineering Books for Beginners 1.
Train a recommendation model in SageMaker Studio using training data that was prepared using SageMaker Data Wrangler. The real-time inference call data is first passed to the SageMaker Data Wrangler container in the inference pipeline, where it is preprocessed and passed to the trained model for product recommendation.
Alteryx provides organizations with an opportunity to automate access to data, analytics , datascience, and process automation all in one, end-to-end platform. Its capabilities can be split into the following topics: automating inputs & outputs, datapreparation, data enrichment, and datascience.
Jupyter notebooks have been one of the most controversial tools in the datascience community. Nevertheless, many data scientists will agree that they can be really valuable – if used well. I’ll show you best practices for using Jupyter Notebooks for exploratory data analysis.
What’s really important in the before part is having production-grade machine learning data pipelines that can feed your model training and inference processes. And that’s really key for taking datascience experiments into production. And so that’s where we got started as a cloud data warehouse.
What’s really important in the before part is having production-grade machine learning data pipelines that can feed your model training and inference processes. And that’s really key for taking datascience experiments into production. And so that’s where we got started as a cloud data warehouse.
Informatica’s AI-powered automation helps streamline data pipelines and improve operational efficiency. Common use cases include integrating data across hybrid cloud environments, managing datalakes, and enabling real-time analytics for Business Intelligence platforms.
If you answer “yes” to any of these questions, you will need cloud storage, such as Amazon AWS’s S3, Azure DataLake Storage or GCP’s Google Storage. Knowing this, you want to have dataprepared in a way to optimize your load. It might be tempting to have massive files and let the system sort it out. How Can phData Help?
The pipelines are interoperable to build a working system: Data (input) pipeline (data acquisition and feature management steps) This pipeline transports raw data from one location to another. Model/training pipeline This pipeline trains one or more models on the training data with preset hyperparameters. Kale v0.7.0.
This highlights the two companies’ shared vision on self-service data discovery with an emphasis on collaboration and data governance. 2) When data becomes information, many (incremental) use cases surface. He is creating information services for his clients, an emerging use case for SSDP.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





































Let's personalize your content