This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
With that, the need for data scientists and machine learning (ML) engineers has grown significantly. Data scientists and ML engineers require capable tooling and sufficient compute for their work. Data scientists and ML engineers require capable tooling and sufficient compute for their work.
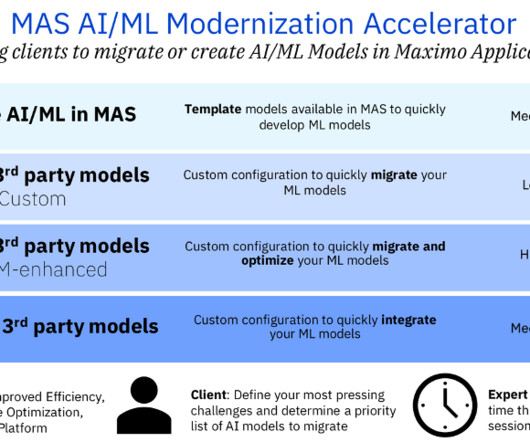
Many businesses are in different stages of their MAS AI/ML modernization journey. In this blog, we delve into 4 different “on-ramps” we created in a MAS Accelerator to offer a straightforward path to harnessing the power of AI in MAS, wherever you may be on your MAS AI/ML modernization journey.
Amazon Redshift is the most popular cloud data warehouse that is used by tens of thousands of customers to analyze exabytes of data every day. SageMaker Studio is the first fully integrated development environment (IDE) for ML. The next step is to build ML models using features selected from one or multiple feature groups.
Now all you need is some guidance on generative AI and machine learning (ML) sessions to attend at this twelfth edition of re:Invent. In addition to several exciting announcements during keynotes, most of the sessions in our track will feature generative AI in one form or another, so we can truly call our track “Generative AI and ML.”
Many of these applications are complex to build because they require collaboration across teams and the integration of data, tools, and services. Data engineers use data warehouses, datalakes, and analytics tools to load, transform, clean, and aggregate data. Choose Continue.
Amazon DataZone is a data management service that makes it quick and convenient to catalog, discover, share, and govern data stored in AWS, on-premises, and third-party sources. Enterprises can use no-code ML solutions to streamline their operations and optimize their decision-making without extensive administrative overhead.
Solution overview Amazon SageMaker is a fully managed service that helps developers and data scientists build, train, and deploy machine learning (ML) models. Datapreparation SageMaker Ground Truth employs a human workforce made up of Northpower volunteers to annotate a set of 10,000 images.
Data, is therefore, essential to the quality and performance of machine learning models. This makes datapreparation for machine learning all the more critical, so that the models generate reliable and accurate predictions and drive business value for the organization. Why do you need DataPreparation for Machine Learning?
Amazon SageMaker Data Wrangler reduces the time it takes to collect and preparedata for machine learning (ML) from weeks to minutes. SageMaker Data Wrangler supports fine-grained data access control with Lake Formation and Amazon Athena connections.
Train a recommendation model in SageMaker Studio using training data that was prepared using SageMaker Data Wrangler. The real-time inference call data is first passed to the SageMaker Data Wrangler container in the inference pipeline, where it is preprocessed and passed to the trained model for product recommendation.
ML operationalization summary As defined in the post MLOps foundation roadmap for enterprises with Amazon SageMaker , ML and operations (MLOps) is the combination of people, processes, and technology to productionize machine learning (ML) solutions efficiently.
MPII is using a machine learning (ML) bid optimization engine to inform upstream decision-making processes in power asset management and trading. This solution helps market analysts design and perform data-driven bidding strategies optimized for power asset profitability. Data comes from disparate sources in a number of formats.
Alignment to other tools in the organization’s tech stack Consider how well the MLOps tool integrates with your existing tools and workflows, such as data sources, data engineering platforms, code repositories, CI/CD pipelines, monitoring systems, etc. and Pandas or Apache Spark DataFrames.
Flywheel creates a datalake (in Amazon S3) in your account where all the training and test data for all versions of the model are managed and stored. Periodically, the new labeled data (to retrain the model) can be made available to flywheel by creating datasets. One for the datalake for Comprehend flywheel.
Utilizing data streamed through LnW Connect, L&W aims to create better gaming experience for their end-users as well as bring more value to their casino customers. Predictive maintenance is a common ML use case for businesses with physical equipment or machinery assets.
Despite the challenges, Afri-SET, with limited resources, envisions a comprehensive data management solution for stakeholders seeking sensor hosting on their platform, aiming to deliver accurate data from low-cost sensors. With AWS Glue custom connectors, it’s effortless to transfer data between Amazon S3 and other applications.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
Try Db2 Warehouse SaaS on AWS for free Netezza SaaS on AWS IBM® Netezza® Performance Server is a cloud-native data warehouse designed to operationalize deep analytics, data mining and BI by unifying, accessing and scaling all types of data across the hybrid cloud. Netezza
After some impressive advances over the past decade, largely thanks to the techniques of Machine Learning (ML) and Deep Learning , the technology seems to have taken a sudden leap forward. It helps facilitate the entire data and AI lifecycle, from datapreparation to model development, deployment and monitoring.
There are many other features and functions , but to verify that a data catalog functions as platform, look for these five features: Intelligence – A data catalog should leverage AI/ML-driven pattern detection, including popularity, pattern matching, and provenance/impact analysis. Key Features of a Data Catalog.
Key Takeaways Data Fabric is a modern data architecture that facilitates seamless data access, sharing, and management across an organization. Data management recommendations and data products emerge dynamically from the fabric through automation, activation, and AI/ML analysis of metadata.
Dataflows represent a cloud-based technology designed for datapreparation and transformation purposes. Dataflows have different connectors to retrieve data, including databases, Excel files, APIs, and other similar sources, along with data manipulations that are performed using Online Power Query Editor.
is our enterprise-ready next-generation studio for AI builders, bringing together traditional machine learning (ML) and new generative AI capabilities powered by foundation models. Automated development: Automates datapreparation, model development, feature engineering and hyperparameter optimization using AutoAI.
Datapreparation Before creating a knowledge base using Knowledge Bases for Amazon Bedrock, it’s essential to prepare the data to augment the FM in a RAG implementation. Krishna Prasad is a Senior Solutions Architect in Strategic Accounts Solutions Architecture team at AWS.
I am Ali Arsanjani, and I lead partner engineering for Google Cloud, specializing in the area of AI-ML, and I’m very happy to be here today with everyone. Then we’re going to talk about adapting foundation models for the enterprise and how that affects the ML lifecycle, and what we need to potentially add to the lifecycle.
I am Ali Arsanjani, and I lead partner engineering for Google Cloud, specializing in the area of AI-ML, and I’m very happy to be here today with everyone. Then we’re going to talk about adapting foundation models for the enterprise and how that affects the ML lifecycle, and what we need to potentially add to the lifecycle.
Alteryx provides organizations with an opportunity to automate access to data, analytics , data science, and process automation all in one, end-to-end platform. Its capabilities can be split into the following topics: automating inputs & outputs, datapreparation, data enrichment, and data science.
Nevertheless, many data scientists will agree that they can be really valuable – if used well. And that’s what we’re going to focus on in this article, which is the second in my series on Software Patterns for Data Science & ML Engineering. in a pandas DataFrame) but in the company’s data warehouse (e.g.,
One of the most prevalent complaints we hear from ML engineers in the community is how costly and error-prone it is to manually go through the ML workflow of building and deploying models. Building end-to-end machine learning pipelines lets ML engineers build once, rerun, and reuse many times. If all goes well, of course ?
The goal of this post is to empower AI and machine learning (ML) engineers, data scientists, solutions architects, security teams, and other stakeholders to have a common mental model and framework to apply security best practices, allowing AI/ML teams to move fast without trading off security for speed.
Starting today, you can interactively prepare large datasets, create end-to-end data flows, and invoke automated machine learning (AutoML) experiments on petabytes of data—a substantial leap from the previous 5 GB limit. Organizations often struggle to extract meaningful insights and value from their ever-growing volume of data.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content