This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
When it comes to data, there are two main types: datalakes and data warehouses. What is a datalake? An enormous amount of raw data is stored in its original format in a datalake until it is required for analytics applications. Which one is right for your business?
This post is part of an ongoing series about governing the machinelearning (ML) lifecycle at scale. This post dives deep into how to set up data governance at scale using Amazon DataZone for the data mesh. Data governance account – This account hosts the central data governance services provided by Amazon DataZone.
A datalake becomes a data swamp in the absence of comprehensive dataquality validation and does not offer a clear link to value creation. Organizations are rapidly adopting the cloud datalake as the datalake of choice, and the need for validating data in real time has become critical.
Amazon DataZone is a data management service that makes it quick and convenient to catalog, discover, share, and govern data stored in AWS, on-premises, and third-party sources. The datalake environment is required to configure an AWS Glue database table, which is used to publish an asset in the Amazon DataZone catalog.
These tools provide data engineers with the necessary capabilities to efficiently extract, transform, and load (ETL) data, build data pipelines, and prepare data for analysis and consumption by other applications. Essential data engineering tools for 2023 Top 10 data engineering tools to watch out for in 2023 1.
How to evaluate MLOps tools and platforms Like every software solution, evaluating MLOps (MachineLearning Operations) tools and platforms can be a complex task as it requires consideration of varying factors. Pay-as-you-go pricing makes it easy to scale when needed.
Discover the nuanced dissimilarities between DataLakes and Data Warehouses. Data management in the digital age has become a crucial aspect of businesses, and two prominent concepts in this realm are DataLakes and Data Warehouses. It acts as a repository for storing all the data.
With the amount of data companies are using growing to unprecedented levels, organizations are grappling with the challenge of efficiently managing and deriving insights from these vast volumes of structured and unstructured data. What is a DataLake? Consistency of data throughout the datalake.
Amazon AppFlow was used to facilitate the smooth and secure transfer of data from various sources into ODAP. Additionally, Amazon Simple Storage Service (Amazon S3) served as the central datalake, providing a scalable and cost-effective storage solution for the diverse data types collected from different systems.
This data is then integrated into centralized databases for further processing and analysis. Data Cleaning and Preprocessing IoT data can be noisy, incomplete, and inconsistent. Data engineers employ data cleaning and preprocessing techniques to ensure dataquality, making it ready for analysis and decision-making.
He specializes in large language models, cloud infrastructure, and scalable data systems, focusing on building intelligent solutions that enhance automation and data accessibility across Amazons operations. He specializes in building scalable machinelearning infrastructure, distributed systems, and containerization technologies.
Moving across the typical machinelearning lifecycle can be a nightmare. From gathering and processing data to building models through experiments, deploying the best ones, and managing them at scale for continuous value in production—it’s a lot. How to understand your users (data scientists, ML engineers, etc.).
Cloud-based business intelligence (BI): Cloud-based BI tools enable organizations to access and analyze data from cloud-based sources and on-premises databases. Machinelearning and AI analytics: Machinelearning and AI analytics leverage advanced algorithms to automate the analysis of data, discover hidden patterns, and make predictions.
If data is the new oil, then high-qualitydata is the new black gold. Just like with oil, if you don’t have good dataquality, you will not get very far. So, what can you do to ensure your data is up to par and […]. You might not even make it out of the starting gate.
Data Science extracts insights and builds predictive models from processed data. Big Data technologies include Hadoop, Spark, and NoSQL databases. Data Science uses Python, R, and machinelearning frameworks. Both fields are interdependent for effective data-driven decision-making What is Big Data?
Introduction Machinelearning models learn patterns from data and leverage the learning, captured in the model weights, to make predictions on new, unseen data. Data, is therefore, essential to the quality and performance of machinelearning models. million per year.
Using the services built-in source connectors standardizes and simplifies the work needed to maintain dataquality and manage the overall data lifecycle.
Amazon SageMaker Data Wrangler reduces the time it takes to collect and prepare data for machinelearning (ML) from weeks to minutes. SageMaker Data Wrangler supports fine-grained data access control with Lake Formation and Amazon Athena connections.
Unstructured data makes up 80% of the world's data and is growing. Managing unstructured data is essential for the success of machinelearning (ML) projects. Without structure, data is difficult to analyze and extracting meaningful insights and patterns is challenging.
Amazon SageMaker Canvas now empowers enterprises to harness the full potential of their data by enabling support of petabyte-scale datasets. When SageMaker Data Wrangler finishes importing, you can start transforming the dataset. In the flow, choose the options menu (three dots) for the node, then choose Get data insights.
Many CIOs argue the rise of big data pushed people to use data more proactively for business decision-making. Big data got“ more leaders and people in the organization to use data, analytics, and machinelearning in their decision making,” says former CIO Isaac Sacolick. Big data can grow too big fast.
By leveraging data services and APIs, a data fabric can also pull together data from legacy systems, datalakes, data warehouses and SQL databases, providing a holistic view into business performance. Then, it applies these insights to automate and orchestrate the data lifecycle.
Powered by machinelearning (ML), Einstein Discovery provides predictions and recommendations within Tableau workflows for accelerated and smarter decision-making. You can now connect to your data in Azure SQL Database (with Azure Active Directory) and Azure DataLake Gen 2. What is Einstein Discovery?
There are many well-known libraries and platforms for data analysis such as Pandas and Tableau, in addition to analytical databases like ClickHouse, MariaDB, Apache Druid, Apache Pinot, Google BigQuery, Amazon RedShift, etc. With these data exploration tools, you can determine if your data is accurate, consistent, and reliable.
As organisations grapple with this vast amount of information, understanding the main components of Big Data becomes essential for leveraging its potential effectively. Key Takeaways Big Data originates from diverse sources, including IoT and social media. Datalakes and cloud storage provide scalable solutions for large datasets.
Role of Data Engineers in the Data Ecosystem Data Engineers play a crucial role in the data ecosystem by bridging the gap between raw data and actionable insights. They are responsible for building and maintaining data architectures, which include databases, data warehouses, and datalakes.
As organisations grapple with this vast amount of information, understanding the main components of Big Data becomes essential for leveraging its potential effectively. Key Takeaways Big Data originates from diverse sources, including IoT and social media. Datalakes and cloud storage provide scalable solutions for large datasets.
Data engineers play a crucial role in managing and processing big data Ensuring dataquality and integrity Dataquality and integrity are essential for accurate data analysis. Data engineers are responsible for ensuring that the data collected is accurate, consistent, and reliable.
Summary: Data transformation tools streamline data processing by automating the conversion of raw data into usable formats. These tools enhance efficiency, improve dataquality, and support Advanced Analytics like MachineLearning. Why Are Data Transformation Tools Important?
Therefore, when the Principal team started tackling this project, they knew that ensuring the highest standard of data security such as regulatory compliance, data privacy, and dataquality would be a non-negotiable, key requirement.
Curtis will explore how Cleanlab automatically detects and corrects errors across various datasets, ultimately improving the overall performance of machinelearning models. Delphina Demo: AI-powered Data Scientist Jeremy Hermann | Co-founder at Delphina | Delphina.Ai
The group kicked off the session by exchanging ideas about what it means to have a modern data architecture. Atif Salam noted that as recently as a year ago, the primary focus in many organizations was on ingesting data and building datalakes.
Figure 1 illustrates the typical metadata subjects contained in a data catalog. Figure 1 – Data Catalog Metadata Subjects. Datasets are the files and tables that data workers need to find and access. They may reside in a datalake, warehouse, master data repository, or any other shared data resource.
Summary: Data ingestion is the process of collecting, importing, and processing data from diverse sources into a centralised system for analysis. This crucial step enhances dataquality, enables real-time insights, and supports informed decision-making. DataLakes allow for flexible analysis.
This makes it easier to compare and contrast information and provides organizations with a unified view of their data. MachineLearningData pipelines feed all the necessary data into machinelearning algorithms, thereby making this branch of Artificial Intelligence (AI) possible.
Big data analytics, IoT, AI, and machinelearning are revolutionizing the way businesses create value and competitive advantage. The cloud is especially well-suited to large-scale storage and big data analytics, due in part to its capacity to handle intensive computing requirements at scale.
DataLake vs. Data Warehouse Distinguishing between these two storage paradigms and understanding their use cases. Students should learn how datalake s can store raw data in its native format, while data warehouses are optimised for structured data.
Ensures consistent, high-qualitydata is readily available to foster innovation and enable you to drive competitive advantage in your markets through advanced analytics and machinelearning. You must be able to continuously catalog, profile, and identify the most frequently used data. Increase metadata maturity.
For example, data catalogs have evolved to deliver governance capabilities like managing dataquality and data privacy and compliance. It uses metadata and data management tools to organize all data assets within your organization. After all, Alex may not be aware of all the data available to her.
Across the country, data scientists have an unemployment rate of 2% and command an average salary of nearly $100,000. As they attempt to put machinelearning models into production, data science teams encounter many of the same hurdles that plagued data analytics teams in years past: Finding trusted, valuable data is time-consuming.
Institute of Analytics The Institute of Analytics is a non-profit organization that provides data science and analytics courses, workshops, certifications, research, and development. The courses and workshops cover a wide range of topics, from basic data science concepts to advanced machinelearning techniques.
Think of it as building plumbing for data to flow smoothly throughout the organization. EVENT — ODSC East 2024 In-Person and Virtual Conference April 23rd to 25th, 2024 Join us for a deep dive into the latest data science and AI trends, tools, and techniques, from LLMs to data analytics and from machinelearning to responsible AI.
The product concept back then went something like: In a world where enterprises have numerous sources of data, let’s make a thing that helps people find the best data asset to answer their question based on what other users were using. And to determine “best,” we’d ingest log files and leverage machinelearning.
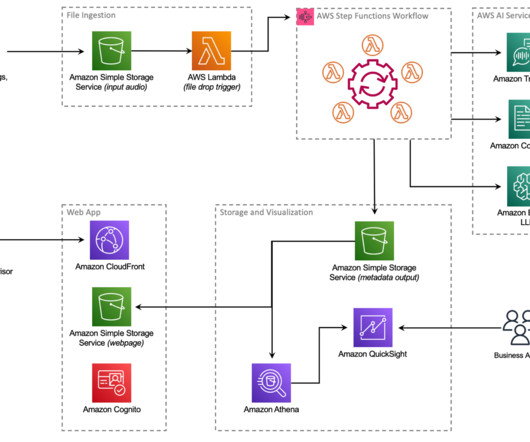
You’ll also learn about the latest tools in NLP, machinelearning, MLOps, and more during the Solution Talks. In this Showcase Talk, you’ll learn how to turn audio into high-fidelity text with NLP and derive actionable, valuable insights. Check them out below. Check them out for free!
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content