This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the DataScience Blogathon. Introduction Data is defined as information that has been organized in a meaningful way. Data collection is critical for businesses to make informed decisions, understand customers’ […]. The post DataLake or DataWarehouse- Which is Better?
When it comes to data, there are two main types: datalakes and datawarehouses. What is a datalake? An enormous amount of raw data is stored in its original format in a datalake until it is required for analytics applications. Which one is right for your business?
This article was published as a part of the DataScience Blogathon. The post How a Delta Lake is Process with Azure Synapse Analytics appeared first on Analytics Vidhya.
The market for datawarehouses is booming. While there is a lot of discussion about the merits of datawarehouses, not enough discussion centers around datalakes. We talked about enterprise datawarehouses in the past, so let’s contrast them with datalakes. DataWarehouse.
We have solicited insights from experts at industry-leading companies, asking: "What were the main AI, DataScience, Machine Learning Developments in 2021 and what key trends do you expect in 2022?" Read their opinions here.
Continuous Integration and Continuous Delivery (CI/CD) for Data Pipelines: It is a Game-Changer with AnalyticsCreator! The need for efficient and reliable data pipelines is paramount in datascience and data engineering. It offers full BI-Stack Automation, from source to datawarehouse through to frontend.
This article was published as a part of the DataScience Blogathon. Introduction Most of you would know the different approaches for building a data and analytics platform. You would have already worked on systems that used traditional warehouses or Hadoop-based datalakes. Selecting one among […].
This article was published as a part of the DataScience Blogathon. Introduction In the modern data world, Lakehouse has become one of the most discussed topics for building a data platform.
Anderson, Talend Regional Manager, Customer Success Architect & Kent Graziano, Snowflake Senior Technical Evangelist So you want to build a DataLake? Perhaps you think a DataLake will eliminate the need for a DataWarehouse and all your business users will merely. Ok, sure let’s talk about that.
In the ever-evolving world of big data, managing vast amounts of information efficiently has become a critical challenge for businesses across the globe. As datalakes gain prominence as a preferred solution for storing and processing enormous datasets, the need for effective data version control mechanisms becomes increasingly evident.
While databases were the traditional way to store large amounts of data, a new storage method has developed that can store even more significant and varied amounts of data. These are called datalakes. What Are DataLakes? In many cases, this could mean using multiple security programs and platforms.
With this full-fledged solution, you don’t have to spend all your time and effort combining different services or duplicating data. Overview of One Lake Fabric features a lake-centric architecture, with a central repository known as OneLake. Now, we can save the data as delta tables to use later for sales analytics.
Enterprises often rely on datawarehouses and datalakes to handle big data for various purposes, from business intelligence to datascience. A new approach, called a data lakehouse, aims to …
Data engineering tools offer a range of features and functionalities, including data integration, data transformation, data quality management, workflow orchestration, and data visualization. Essential data engineering tools for 2023 Top 10 data engineering tools to watch out for in 2023 1.
Microsoft just held one of its largest conferences of the year, and a few major announcements were made which pertain to the cloud datascience world. Azure Synapse Analytics can be seen as a merge of Azure SQL DataWarehouse and Azure DataLake. Those are the big datascience announcements of the week.
Discover the nuanced dissimilarities between DataLakes and DataWarehouses. Data management in the digital age has become a crucial aspect of businesses, and two prominent concepts in this realm are DataLakes and DataWarehouses. It acts as a repository for storing all the data.
In many of the conversations we have with IT and business leaders, there is a sense of frustration about the speed of time-to-value for big data and datascience projects. We often hear that organizations have invested in datascience capabilities but are struggling to operationalize their machine learning models.
DataLakes have been around for well over a decade now, supporting the analytic operations of some of the largest world corporations. Such data volumes are not easy to move, migrate or modernize. The challenges of a monolithic datalake architecture Datalakes are, at a high level, single repositories of data at scale.
Unified data storage : Fabric’s centralized datalake, Microsoft OneLake, eliminates data silos and provides a unified storage system, simplifying data access and retrieval. OneLake is designed to store a single copy of data in a unified location, leveraging the open-source Apache Parquet format.
Though you may encounter the terms “datascience” and “data analytics” being used interchangeably in conversations or online, they refer to two distinctly different concepts. Meanwhile, data analytics is the act of examining datasets to extract value and find answers to specific questions.
With the amount of data companies are using growing to unprecedented levels, organizations are grappling with the challenge of efficiently managing and deriving insights from these vast volumes of structured and unstructured data. What is a DataLake? Consistency of data throughout the datalake.
Data has to be stored somewhere. Datawarehouses are repositories for your cleaned, processed data, but what about all that unstructured data your organization is starting to notice? What is a datalake? This can be structured, semi-structured, and even unstructured data. Where does it go?
Summary: A datawarehouse is a central information hub that stores and organizes vast amounts of data from different sources within an organization. Unlike operational databases focused on daily tasks, datawarehouses are designed for analysis, enabling historical trend exploration and informed decision-making.
Data mining refers to the systematic process of analyzing large datasets to uncover hidden patterns and relationships that inform and address business challenges. It’s an integral part of data analytics and plays a crucial role in datascience. Each stage is crucial for deriving meaningful insights from data.
This data mesh strategy combined with the end consumers of your data cloud enables your business to scale effectively, securely, and reliably without sacrificing speed-to-market. What is a Cloud DataWarehouse? For example, most datawarehouse workloads peak during certain times, say during business hours.
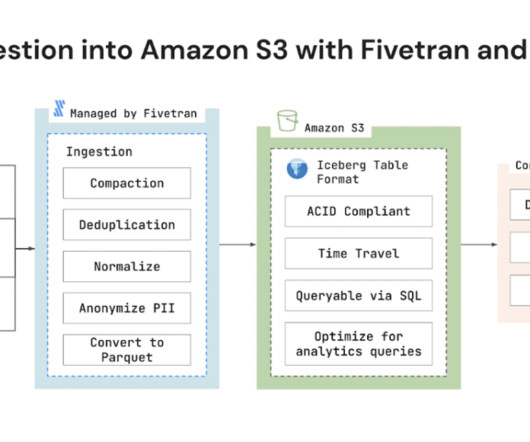
Fivetran today announced support for Amazon Simple Storage Service (Amazon S3) with Apache Iceberg datalake format. Amazon S3 is an object storage service from Amazon Web Services (AWS) that offers industry-leading scalability, data availability, security, and performance.
The abilities of an organization towards capturing, storing, and analyzing data; searching, sharing, transferring, visualizing, querying, and updating data; and meeting compliance and regulations are mandatory for any sustainable organization. For example, most datawarehouses […].
Learn about cutting-edge developments in AI and datascience from the experts who know them best on ODSC’s Ai X Podcast. James has been at the forefront of data architecture at Microsoft for the better part of the last nine years. James Serra discusses data lakehouses, which merge datalakes and datawarehouses.
A data lakehouse architecture combines the performance of datawarehouses with the flexibility of datalakes, to address the challenges of today’s complex data landscape and scale AI.
In many of the conversations we have with IT and business leaders, there is a sense of frustration about the speed of time-to-value for big data and datascience projects. We often hear that organizations have invested in datascience capabilities but are struggling to operationalize their machine learning models.
Amazon AppFlow was used to facilitate the smooth and secure transfer of data from various sources into ODAP. Additionally, Amazon Simple Storage Service (Amazon S3) served as the central datalake, providing a scalable and cost-effective storage solution for the diverse data types collected from different systems.
Apache Doris can better meet the scenarios of report analysis, ad-hoc query, unified datawarehouse, DataLake Query Acceleration, etc. How to learn more about data exploration tools and uses There are plenty of data exploration tools available and countless ways to use them.
These professionals will work with their colleagues to ensure that data is accessible, with proper access. So let’s go through each step one by one, and help you build a roadmap toward becoming a data engineer. Identify your existing datascience strengths. Stay on top of data engineering trends. Get more training!
One of the most common formats for storing large amounts of data is Apache Parquet due to its compact and highly efficient format. This means that business analysts who want to extract insights from the large volumes of data in their datawarehouse must frequently use data stored in Parquet.
With watsonx.data , businesses can quickly connect to data, get trusted insights and reduce datawarehouse costs. A data store built on open lakehouse architecture, it runs both on premises and across multi-cloud environments. Savings may vary depending on configurations, workloads and vendors.
A data leader from the manufacturing industry mentioned their need for a data mesh, but was still wrestling with a number of manual data management processes and needed to first focus on organizing their data into a local datawarehouse or datalake.
Uber understood that digital superiority required the capture of all their transactional data, not just a sampling. They stood up a file-based datalake alongside their analytical database. Because much of the work done on their datalake is exploratory in nature, many users want to execute untested queries on petabytes of data.
Amazon Redshift is the most popular cloud datawarehouse that is used by tens of thousands of customers to analyze exabytes of data every day. AWS Glue is a serverless data integration service that makes it easy to discover, prepare, and combine data for analytics, ML, and application development.
Similarly, it would be pointless to pretend that a data-intensive application resembles a run-off-the-mill microservice which can be built with the usual software toolchain consisting of, say, GitHub, Docker, and Kubernetes. Adapted from the book Effective DataScience Infrastructure. DataScience Layers.
They all agree that a Datamart is a subject-oriented subset of a datawarehouse focusing on a particular business unit, department, subject area, or business functionality. The Datamart’s data is usually stored in databases containing a moving frame required for data analysis, not the full history of data.
Building and maintaining data pipelines Data integration is the process of combining data from multiple sources into a single, consistent view. This involves extracting data from various sources, transforming it into a usable format, and loading it into datawarehouses or other storage systems.
And where data was available, the ability to access and interpret it proved problematic. Big data can grow too big fast. Left unchecked, datalakes became data swamps. Some datalake implementations required expensive ‘cleansing pumps’ to make them navigable again. Where Should Big Data Go from Here?
Delphina Demo: AI-powered Data Scientist Jeremy Hermann | Co-founder at Delphina | Delphina.Ai In this demo, you’ll see how Delphina’s AI-powered “junior” data scientist can transform the datascience workflow, automating labor-intensive tasks like data discovery, transformation, and model building.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content