This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
When it comes to data, there are two main types: datalakes and data warehouses. What is a datalake? An enormous amount of raw data is stored in its original format in a datalake until it is required for analytics applications. Which one is right for your business?
In the ever-evolving world of big data, managing vast amounts of information efficiently has become a critical challenge for businesses across the globe. As datalakes gain prominence as a preferred solution for storing and processing enormous datasets, the need for effective data version control mechanisms becomes increasingly evident.
Most datascientists are familiar with the concept of time series data and work with it often. The time series database (TSDB) , however, is still an underutilized tool in the data science community. Typically, time series analysis is performed either on CSV files or datalakes.
Our goal was to improve the user experience of an existing application used to explore the counters and insights data. The data is stored in a datalake and retrieved by SQL using Amazon Athena. The following figure shows a search query that was translated to SQL and run. The challenge is to assure quality.
Many of these applications are complex to build because they require collaboration across teams and the integration of data, tools, and services. Data engineers use data warehouses, datalakes, and analytics tools to load, transform, clean, and aggregate data. option("multiLine", "true").option("header",
With this full-fledged solution, you don’t have to spend all your time and effort combining different services or duplicating data. Overview of One Lake Fabric features a lake-centric architecture, with a central repository known as OneLake. Now, we can save the data as delta tables to use later for sales analytics.
Data exploration and model development were conducted using well-known machine learning (ML) tools such as Jupyter or Apache Zeppelin notebooks. Apache Hive was used to provide a tabular interface to data stored in HDFS, and to integrate with Apache Spark SQL. This also led to a backlog of data that needed to be ingested.
Discover the nuanced dissimilarities between DataLakes and Data Warehouses. Data management in the digital age has become a crucial aspect of businesses, and two prominent concepts in this realm are DataLakes and Data Warehouses. It acts as a repository for storing all the data.
With the amount of data companies are using growing to unprecedented levels, organizations are grappling with the challenge of efficiently managing and deriving insights from these vast volumes of structured and unstructured data. What is a DataLake? Consistency of data throughout the datalake.
Swami Sivasubramanian, Vice President of AWS Data and Machine Learning Watch Swami Sivasubramanian, Vice President of Data and AI at AWS, to discover how you can use your company data to build differentiated generative AI applications and accelerate productivity for employees across your organization.
Azure Synapse Analytics can be seen as a merge of Azure SQLData Warehouse and Azure DataLake. Synapse allows one to use SQL to query petabytes of data, both relational and non-relational, with amazing speed. I have not gotten a chance to try it out yet, so I am not sure its usecase for data science yet.
Data management problems can also lead to data silos; disparate collections of databases that don’t communicate with each other, leading to flawed analysis based on incomplete or incorrect datasets. One way to address this is to implement a datalake: a large and complex database of diverse datasets all stored in their original format.
Summary: This blog provides a comprehensive roadmap for aspiring Azure DataScientists, outlining the essential skills, certifications, and steps to build a successful career in Data Science using Microsoft Azure. This roadmap aims to guide aspiring Azure DataScientists through the essential steps to build a successful career.
The role of a datascientist is in demand and 2023 will be no exception. To get a better grip on those changes we reviewed over 25,000 datascientist job descriptions from that past year to find out what employers are looking for in 2023. Data Science Of course, a datascientist should know data science!
Versioning also ensures a safer experimentation environment, where datascientists can test new models or hypotheses on historical data snapshots without impacting live data. Note : Cloud Data warehouses like Snowflake and Big Query already have a default time travel feature. FAQs What is a Data Lakehouse?
DagsHub DagsHub is a centralized Github-based platform that allows Machine Learning and Data Science teams to build, manage and collaborate on their projects. In addition to versioning code, teams can also version data, models, experiments and more. It versions tables instead of files and has a SQL query interface for those tables.
Jason McVay is a datascientist at Indigo Ag, an agriculture-tech company headquartered in Massachusetts. In this essay, Jason reflects on the value of thinking spatially about data, showing how his experience as a graduate student influences his role as a datascientist today. Spatial isn’t special.
Snowpark is the set of libraries and runtimes in Snowflake that securely deploy and process non-SQL code, including Python , Java, and Scala. As a declarative language, SQL is very powerful in allowing users from all backgrounds to ask questions about data. What is Snowflake’s Snowpark? Why Does Snowpark Matter?
Solution overview Amazon SageMaker is a fully managed service that helps developers and datascientists build, train, and deploy machine learning (ML) models. Processing these images and scanned documents is not a cost- or time-efficient task for humans, and requires highly performant infrastructure that can reduce the time to value.
A data lakehouse contains an organization’s data in a unstructured, structured, semi-structured form, which can be stored indefinitely for immediate or future use. This data is used by datascientists and engineers who study data to gain business insights.
Every day, millions of riders use the Uber app, unwittingly contributing to a complex web of data-driven decisions. This blog takes you on a journey into the world of Uber’s analytics and the critical role that Presto, the open source SQL query engine, plays in driving their success. What is Presto?
You can streamline the process of feature engineering and data preparation with SageMaker Data Wrangler and finish each stage of the data preparation workflow (including data selection, purification, exploration, visualization, and processing at scale) within a single visual interface.
Overview: Data science vs data analytics Think of data science as the overarching umbrella that covers a wide range of tasks performed to find patterns in large datasets, structure data for use, train machine learning models and develop artificial intelligence (AI) applications.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
Its goal is to help with a quick analysis of target characteristics, training vs testing data, and other such data characterization tasks. Apache Superset GitHub | Website Apache Superset is a must-try project for any ML engineer, datascientist, or data analyst.
These days, datascientists are in high demand. Across the country, datascientists have an unemployment rate of 2% and command an average salary of nearly $100,000. For these reasons, finding and evaluating data is often time-consuming. How Data Catalogs Help DataScientists Ask Better Questions.
Amazon Redshift uses SQL to analyze structured and semi-structured data across data warehouses, operational databases, and datalakes, using AWS-designed hardware and ML to deliver the best price-performance at any scale. You can use query_string to filter your dataset by SQL and unload it to Amazon S3.
Some popular end-to-end MLOps platforms in 2023 Amazon SageMaker Amazon SageMaker provides a unified interface for data preprocessing, model training, and experimentation, allowing datascientists to collaborate and share code easily. Check out the Kubeflow documentation.
Choosing a DataLake Format: What to Actually Look For The differences between many datalake products today might not matter as much as you think. When choosing a datalake, here’s something else to consider. Datascientists and business leaders should consider these before investing.
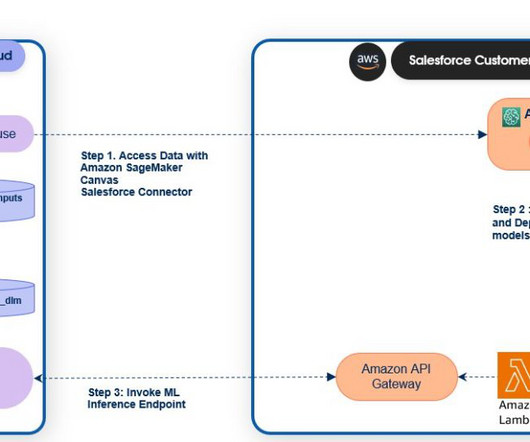
SageMaker endpoints can be registered to the Salesforce Data Cloud to activate predictions in Salesforce. Salesforce Data Cloud and Einstein Studio Salesforce Data Cloud is a data platform that provides businesses with real-time updates of their customer data from any touch point. For Callback URL , enter [link].studio.sagemaker.aws/canvas/default/lab
5 Reasons Why SQL is Still the Most Accessible Language for New DataScientists Between its ability to perform data analysis and ease-of-use, here are 5 reasons why SQL is still ideal for new datascientists to get into the field. But there’s a problem: how on earth do you hook up that GPU?
From gathering and processing data to building models through experiments, deploying the best ones, and managing them at scale for continuous value in production—it’s a lot. As the number of ML-powered apps and services grows, it gets overwhelming for datascientists and ML engineers to build and deploy models at scale.
When it comes to data complexity, it is for sure that in machine learning, we are dealing with much more complex data. First of all, machine learning engineers and datascientists often use data from different data vendors. Some data sets are being corrected by data entry specialists and manual inspectors.
This offers everyone from datascientists to advanced analysts to business users an intuitive, no-code environment that empowers quick and confident decisions guided by ethical, transparent AI. You can now connect to your data in Azure SQL Database (with Azure Active Directory) and Azure DataLake Gen 2.
When done well, data democratization empowers employees with tools that let everyone work with data, not just the datascientists. When workers get their hands on the right data, it not only gives them what they need to solve problems, but also prompts them to ask, “What else can I do with data?
Enterprises that use DataRobot on Azure get the knowledge, experience, and best practices of datascientists from DataRobot. The DataRobot AI Platform seamlessly integrates with Azure cloud services, including Azure Machine Learning, Azure DataLake Storage Gen 2 (ADLS), Azure Synapse Analytics, and Azure SQL database.
Start Learning AI With the ODSC West Data Primer Series In this six-part series as part of the ODSC West mini-bootcamp, you’ll learn everything you need to know to get started with AI, including SQL, machine learning, and even LLMs. In addition, we’ll discuss a variety of tools that form the modern LLM application development stack.
Hive is a data warehousing infrastructure built on top of Hadoop. It has the following features: It facilitates querying, summarizing, and analyzing large datasets Hadoop also provides a SQL-like language called HiveQL Hive allows users to write queries to extract valuable insights from structured and semi-structured data stored in Hadoop.
Jupyter notebooks have been one of the most controversial tools in the data science community. Nevertheless, many datascientists will agree that they can be really valuable – if used well. Data on its own is not sufficient for a cohesive story. in a pandas DataFrame) but in the company’s data warehouse (e.g.,
Data Engineering is one of the most productive job roles today because it imbibes both the skills required for software engineering and programming and advanced analytics needed by DataScientists. How to Become an Azure Data Engineer? Data Warehousing concepts and knowledge should be strong. What is Polybase?
Data engineering is a rapidly growing field, and there is a high demand for skilled data engineers. If you are a datascientist, you may be wondering if you can transition into data engineering. The good news is that there are many skills that datascientists already have that are transferable to data engineering.
This pushes into Big Data as well, as many companies now have significant amounts of data and large datalakes that need analyzing. While there’s a need for analyzing smaller datasets on your laptop, expanding into TB+ datasets requires a whole new set of skills and data analytics frameworks.
They are responsible for building and maintaining data architectures, which include databases, data warehouses, and datalakes. Their work ensures that data flows seamlessly through the organisation, making it easier for DataScientists and Analysts to access and analyse information.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content