This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
For example, in the bank marketing use case, the management account would be responsible for setting up the organizational structure for the bank’s data and analytics teams, provisioning separate accounts for data governance, datalakes, and data science teams, and maintaining compliance with relevant financial regulations.
They must connect not only systems, data, and applications to each other, but also to their […]. The post Establishing Connections and Putting an End to DataSilos appeared first on DATAVERSITY.
However, simply acquiring all available data and storing it in datalakes does not guarantee success. The true meaning of data activation For the past few decades, organizations worldwide have collected all sorts of data and stored it in massive datalakes.
Unified data storage : Fabric’s centralized datalake, Microsoft OneLake, eliminates datasilos and provides a unified storage system, simplifying data access and retrieval. OneLake is designed to store a single copy of data in a unified location, leveraging the open-source Apache Parquet format.
Data is one of the most critical assets of many organizations. Theyre constantly seeking ways to use their vast amounts of information to gain competitive advantages. Amazon AppFlow was used to facilitate the smooth and secure transfer of data from various sources into ODAP.
Discover the nuanced dissimilarities between DataLakes and Data Warehouses. Data management in the digital age has become a crucial aspect of businesses, and two prominent concepts in this realm are DataLakes and Data Warehouses. It acts as a repository for storing all the data.
To make your data management processes easier, here’s a primer on datalakes, and our picks for a few datalake vendors worth considering. What is a datalake? First, a datalake is a centralized repository that allows users or an organization to store and analyze large volumes of data.
Within the Data Management industry, it’s becoming clear that the old model of rounding up massive amounts of data, dumping it into a datalake, and building an API to extract needed information isn’t working. Click to learn more about author Brian Platz.
The primary objective of this idea is to democratize data and make it transparent by breaking down datasilos that cause friction when solving business problems. What Components Make up the Snowflake Data Cloud? What is a DataLake? What is the Difference Between a DataLake and a Data Warehouse?
What if the problem isn’t in the volume of data, but rather where it is located—and how hard it is to gather? Nine out of 10 IT leaders report that these disconnects, or datasilos, create significant business challenges.* Analytics data catalog. Data integration. Loss of visibility after data leaves EDW.
What if the problem isn’t in the volume of data, but rather where it is located—and how hard it is to gather? Nine out of 10 IT leaders report that these disconnects, or datasilos, create significant business challenges.* Analytics data catalog. Data integration. Loss of visibility after data leaves EDW.
Ventana found that the most time-consuming part of an organization’s analytic efforts is accessing and preparing data; this is the case for more than one-half (55%) of respondents. 1 Data catalogs can significantly reduce this burden by making it easier for analysts to find and access relevant information.
In another decade, the internet and mobile started the generate data of unforeseen volume, variety and velocity. It required a different data platform solution. Hence, DataLake emerged, which handles unstructured and structured data with huge volume. All phases of the data-information lifecycle.
While this industry has used data and analytics for a long time, many large travel organizations still struggle with datasilos , which prevent them from gaining the most value from their data. What is big data in the travel and tourism industry? What is big data in the travel and tourism industry?
Without access to all critical and relevant data, the data that emerges from a data fabric will have gaps that delay business insights required to innovate, mitigate risk, or improve operational efficiencies. You must be able to continuously catalog, profile, and identify the most frequently used data.
Understanding these methods helps organizations optimize their data workflows for better decision-making. Introduction In today’s data-driven world, efficient data processing is crucial for informed decision-making and business growth. Load After extraction, the next step is Load. Conversely, ELT flips this sequence.
And in an increasingly remote workforce, people need to access data systems easily to do their jobs. Today, data dwells everywhere. Data modernization enables informed decision making by pulling data out of systems more reliably. It helps you identify high-value data combinations and integrations.
Open is creating a foundation for storing, managing, integrating and accessing data built on open and interoperable capabilities that span hybrid cloud deployments, data storage, data formats, query engines, governance and metadata. This enables your organization to extract valuable insights and drive informed decision-making.
Misconception 1: Cloud data warehouses are more expensive When considering moving data warehouses from on-premises to the cloud, companies often get sticker shock at the total cost of ownership. However, a more detailed analysis is needed to make an informed decision.
As an organization embraces digital transformation , more data is available to inform decisions. To use that data, decision-makers across the company will need to have access. However, opening the floodgates of information comes with challenges. Inform Decision Making. What Are the Top Data Challenges to Analytics?
What is Data Mining? In today’s data-driven world, organizations collect vast amounts of data from various sources. Information like customer interactions, and sales transactions plays a pivotal role in decision-making. But, this data is often stored in disparate systems and formats.
Understanding Lean Data Management Lean data management revolves around four core principles: accuracy , relevance , accessibility , and efficiency. Accurate data ensures decisions are grounded in reliable information. Relevance prioritises the most critical data for organisational goals, eliminating unnecessary noise.
Even if organizations survive a migration to S/4 and HANA cloud, licensing and performance constraints make it difficult to perform advanced analytics on this data within the SAP environment.
A data mesh is a decentralized approach to data architecture that’s been gaining traction as a solution to the challenges posed by large and complex data ecosystems. It’s all about breaking down datasilos, empowering domain teams to take ownership of their data, and fostering a culture of data collaboration.
However, most enterprises are hampered by data strategies that leave teams flat-footed when […]. The post Why the Next Generation of Data Management Begins with Data Fabrics appeared first on DATAVERSITY. Click to learn more about author Kendall Clark. The mandate for IT to deliver business value has never been stronger.
According to Gartner, data fabric is an architecture and set of data services that provides consistent functionality across a variety of environments, from on-premises to the cloud. Data fabric simplifies and integrates on-premises and cloud Data Management by accelerating digital transformation.
Using data to understand customers’ needs allows you to: Provide meaningful educational marketing materials. Ensure that customers have the information they need. The problem many companies face is that each department has its own data, technologies, and information handling processes. Accelerate the sales cycle.
So, ARC worked to make data more accessible across domains while capturing tribal knowledge in the data catalog; this reduced the subject-matter-expertise bottlenecks during product development and accelerated higher quality analysis. In addition to an AWS S3 DataLake and Snowflake Data Cloud, ARC also chose Alation Data Catalog.
A data catalog contains critical metadata (like schema information), which need to be secure and available to consumers at all times. Hence, the data catalog must be protected by enterprise-grade security. The cloud unifies a distributed data landscape. Enjoy the peace of mind of always-on security.
In the data-driven world we live in today, the field of analytics has become increasingly important to remain competitive in business. In fact, a study by McKinsey Global Institute shows that data-driven organizations are 23 times more likely to outperform competitors in customer acquisition and nine times […].
These pipelines assist data scientists in saving time and effort by ensuring that the data is clean, properly formatted, and ready for use in machine learning tasks. Moreover, ETL pipelines play a crucial role in breaking down datasilos and establishing a single source of truth.
With machine learning (ML) and artificial intelligence (AI) applications becoming more business-critical, organizations are in the race to advance their AI/ML capabilities. To realize the full potential of AI/ML, having the right underlying machine learning platform is a prerequisite.
The use of separate data warehouses and lakes has created datasilos, leading to problems such as lack of interoperability, duplicate governance efforts, complex architectures, and slower time to value. You can use Amazon SageMaker Lakehouse to achieve unified access to data in both data warehouses and datalakes.
Transitional modeling is like the Lego of the customer data world. Instead of trying to build a perfect, complete customer model from the get-go, it starts with small, standardized pieces of information – let’s call them data atoms (or atomic data). Let’s look at an example. Who performed the action?
Amazon Q Business is a generative AI-powered assistant that can answer questions, provide summaries, generate content, and securely complete tasks based on data and information in your enterprise systems. For more information, see Configure Amazon Q Business with AWS IAM Identity Center trusted identity propagation.
Decentralized clinical trials, however, often employ a singular datalake for all of an organization’s clinical trials. With a centralized datalake, organizations can avoid the duplication of data across separate trial databases.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






















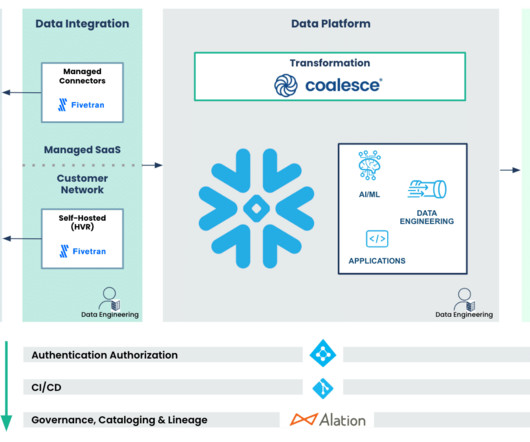



















Let's personalize your content