This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction All data mining repositories have a similar purpose: to onboard data for reporting intents, analysis purposes, and delivering insights. By their definition, the types of data it stores and how it can be accessible to users differ.
Whereas a datawarehouse will need rigid data modeling and definitions, a datalake can store different types and shapes of data. In a datalake, the schema of the data can be inferred when it’s read, providing the aforementioned flexibility.
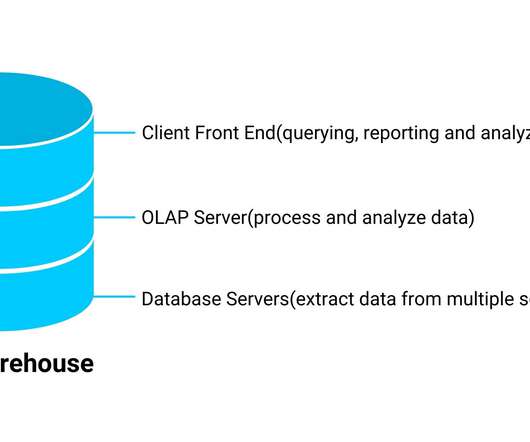
The goal of this post is to understand how data integrity best practices have been embraced time and time again, no matter the technology underpinning. In the beginning, there was a datawarehouse The datawarehouse (DW) was an approach to data architecture and structured data management that really hit its stride in the early 1990s.
In the ever-evolving world of big data, managing vast amounts of information efficiently has become a critical challenge for businesses across the globe. As datalakes gain prominence as a preferred solution for storing and processing enormous datasets, the need for effective data version control mechanisms becomes increasingly evident.
DataLakes have been around for well over a decade now, supporting the analytic operations of some of the largest world corporations. Such data volumes are not easy to move, migrate or modernize. The challenges of a monolithic datalake architecture Datalakes are, at a high level, single repositories of data at scale.
Unified data storage : Fabric’s centralized datalake, Microsoft OneLake, eliminates data silos and provides a unified storage system, simplifying data access and retrieval. OneLake is designed to store a single copy of data in a unified location, leveraging the open-source Apache Parquet format.
Summary: A datawarehouse is a central information hub that stores and organizes vast amounts of data from different sources within an organization. Unlike operational databases focused on daily tasks, datawarehouses are designed for analysis, enabling historical trend exploration and informed decision-making.
This data mesh strategy combined with the end consumers of your data cloud enables your business to scale effectively, securely, and reliably without sacrificing speed-to-market. What is a Cloud DataWarehouse? For example, most datawarehouse workloads peak during certain times, say during business hours.
Each stage is crucial for deriving meaningful insights from data. Data gathering The first step is gathering relevant data from various sources. This could include datawarehouses, datalakes, or even external datasets.
A data lakehouse architecture combines the performance of datawarehouses with the flexibility of datalakes, to address the challenges of today’s complex data landscape and scale AI. New insights and relationships are found in this combination. All of this supports the use of AI.
Amazon Redshift is the most popular cloud datawarehouse that is used by tens of thousands of customers to analyze exabytes of data every day. AWS Glue is a serverless data integration service that makes it easy to discover, prepare, and combine data for analytics, ML, and application development.
In another decade, the internet and mobile started the generate data of unforeseen volume, variety and velocity. It required a different data platform solution. Hence, DataLake emerged, which handles unstructured and structured data with huge volume. Data lakehouse was created to solve these problems.
Thoughtworks says data mesh is key to moving beyond a monolithic datalake. Spoiler alert: data fabric and data mesh are independent design concepts that are, in fact, quite complementary. Thoughtworks says data mesh is key to moving beyond a monolithic datalake 2. Gartner on Data Fabric.
How they can supplement DataLakes and DataWarehouses medium.com The news are also quite fitting, since Google will now enter a partnership with Tumult Labs, a leader in differential privacy for companies and government agencies[4].
Ensure the behaves the way you want it to— especially sensitive data and access. Data integration. Gain useful insights from data stored across different platforms and data sources, such as datawarehouses, datalakes, and CRMs. Create trust and verifiability where viewers consume their data.
Ensure the behaves the way you want it to— especially sensitive data and access. Data integration. Gain useful insights from data stored across different platforms and data sources, such as datawarehouses, datalakes, and CRMs. Create trust and verifiability where viewers consume their data.
This article is an excerpt from the book Expert Data Modeling with Power BI, Third Edition by Soheil Bakhshi, a completely updated and revised edition of the bestselling guide to Power BI and data modeling. A quick search on the Internet provides multiple definitions by technology-leading companies such as IBM, Amazon, and Oracle.
While there isn’t an authoritative definition for the term, it shares its ethos with its predecessor, the DevOps movement in software engineering: by adopting well-defined processes, modern tooling, and automated workflows, we can streamline the process of moving from development to robust production deployments.
The datawarehouse and analytical data stores moved to the cloud and disaggregated into the data mesh. Today, the brightest minds in our industry are targeting the massive proliferation of data volumes and the accompanying but hard-to-find value locked within all that data. Architectures became fabrics.
A Data Catalog is a collection of metadata, combined with data management and search tools, that helps analysts and other data users to find the data that they need, serves as an inventory of available data, and provides information to evaluate fitness data for intended uses. Conclusion.
The primary goal of Data Engineering is to transform raw data into a structured and usable format that can be easily accessed, analyzed, and interpreted by Data Scientists, analysts, and other stakeholders. Future of Data Engineering The Data Engineering market will expand from $18.2
The customer review analysis workflow consists of the following steps: A user uploads a file to dedicated data repository within your Amazon Simple Storage Service (Amazon S3) datalake, invoking the processing using AWS Step Functions. The raw data is processed by an LLM using a preconfigured user prompt.
The combination of large language models (LLMs), including the ease of integration that Amazon Bedrock offers, and a scalable, domain-oriented data infrastructure positions this as an intelligent method of tapping into the abundant information held in various analytics databases and datalakes.
These pipelines automate collecting, transforming, and delivering data, crucial for informed decision-making and operational efficiency across industries. NoSQL Databases: Flexible, scalable solutions for unstructured or semi-structured data. DataWarehouses : Centralised repositories optimised for analytics and reporting.
Similar to a datawarehouse schema, this prep tool automates the development of the recipe to match. For example, data science always consumes “historical” data, and there is no guarantee that the semantics of older datasets are the same, even if their names are unchanged. It’s not a simple definition.
Now, a single customer might use multiple emails or phone numbers, but matching in this way provides a precise definition that could significantly reduce or even eliminate the risk of accidentally associating the actions of multiple customers with one identity. Store this data in a customer data platform or datalake.
Bear the following points in mind when doing so: Consider critical data based on function You’ll have data that is essential for optimizing your customer support. Similarly, you’ll have data that is integral to internal processes, such as SOX controls. Narrow the scope It’s tempting to mark huge swaths of data as critical.
Another useful characteristic of external tables is that they can be partitioned, meaning you can limit queries to specific partitions of the data, which is handy when dealing with large datasets. This allows you to use tools like BigQuery to query the data before it’s migrated to a native BigQuery table.
tl;dr Ein Data Lakehouse ist eine moderne Datenarchitektur, die die Vorteile eines DataLake und eines DataWarehouse kombiniert. Organisationen können je nach ihren spezifischen Bedürfnissen und Anforderungen zwischen einem DataWarehouse und einem Data Lakehouse wählen.
All this raw data goes into your persistent stage. Then, if you later refine your definition of what constitutes an “engaged” customer, having the raw data in persistent staging allows for easy reprocessing of historical data with the new logic. Are people binge-watching your original series?
So, if we compare data to oil, it suggests everyone has access to the same data, though in different quantities and easier to harvest for some. This comparison makes data feel like a commodity, available to everyone but processed in different ways. However, it definitely doesn’t define the product.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




































Let's personalize your content