This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This enables sales teams to interact with our internal sales enablement collateral, including sales plays and first-call decks, as well as customer references, customer- and field-facing incentive programs, and content on the AWS website, including blog posts and service documentation.
Generative AI models have the potential to revolutionize enterprise operations, but businesses must carefully consider how to harness their power while overcoming challenges such as safeguarding data and ensuring the quality of AI-generated content. Set up the database access and network access.
With the amount of data companies are using growing to unprecedented levels, organizations are grappling with the challenge of efficiently managing and deriving insights from these vast volumes of structured and unstructured data. What is a DataLake? Consistency of data throughout the datalake.
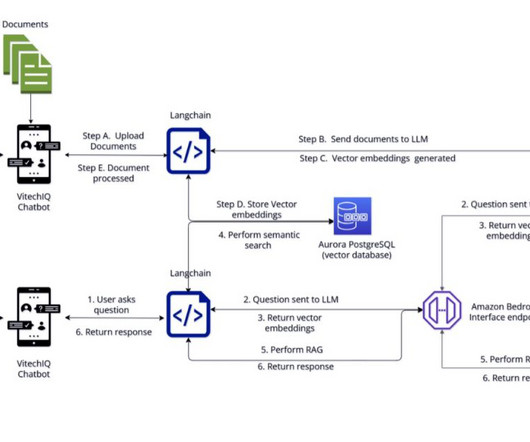
To serve their customers, Vitech maintains a repository of information that includes product documentation (user guides, standard operating procedures, runbooks), which is currently scattered across multiple internal platforms (for example, Confluence sites and SharePoint folders).
Data management problems can also lead to data silos; disparate collections of databases that don’t communicate with each other, leading to flawed analysis based on incomplete or incorrect datasets. The datalake can then refine, enrich, index, and analyze that data. and various countries in Europe.
The Product Stewardship department is responsible for managing a large collection of regulatory compliance documents. Example questions might be “What are the restrictions for CMR substances?”, “How long do I need to keep the documents related to a toluene sale?”, or “What is the reach characterization ratio and how do I calculate it?”
Our goal was to improve the user experience of an existing application used to explore the counters and insights data. The data is stored in a datalake and retrieved by SQL using Amazon Athena. The problem Making data accessible to users through applications has always been a challenge.
Intelligent document processing , translation and summarization, flexible and insightful responses for customer support agents, personalized marketing content, and image and code generation are a few use cases using generative AI that organizations are rolling out in production.
Adding new data to the storage requires pulling the existing data, then calculating the new hash before pushing back the whole data. DVC lacks crucial relational database features, making it an unsuitable choice for those familiar with relational databases. So, Dolt’s integration with Git makes it easier to learn.
Text, images, audio, and videos are common examples of unstructured data. Most companies produce and consume unstructured data such as documents, emails, web pages, engagement center phone calls, and social media. Understanding the data, categorizing it, storing it, and extracting insights from it can be challenging.
Text analytics: Text analytics, also known as text mining, deals with unstructured text data, such as customer reviews, social media comments, or documents. It uses natural language processing (NLP) techniques to extract valuable insights from textual data. Poor data integration can lead to inaccurate insights.
It now also supports PDF documents. Azure Data Factory Preserves Metadata during File Copy When performing a File copy between Amazon S3, Azure Blob, and Azure DataLake Gen 2, the metadata will be copied as well. Azure Database for MySQL now supports MySQL 8.0 Not a huge update but still a nice feature.
There are many well-known libraries and platforms for data analysis such as Pandas and Tableau, in addition to analytical databases like ClickHouse, MariaDB, Apache Druid, Apache Pinot, Google BigQuery, Amazon RedShift, etc. With Great Expectations , data teams can express what they “expect” from their data using simple assertions.
Structured Query Language (SQL) is a complex language that requires an understanding of databases and metadata. The solution in this post aims to bring enterprise analytics operations to the next level by shortening the path to your data using natural language. This table is used for finding the correct table, database, and attributes.
In this post, we will explore the potential of using MongoDB’s time series data and SageMaker Canvas as a comprehensive solution. MongoDB Atlas MongoDB Atlas is a fully managed developer data platform that simplifies the deployment and scaling of MongoDB databases in the cloud. Setup the Database access and Network access.
And where data was available, the ability to access and interpret it proved problematic. Big data can grow too big fast. Left unchecked, datalakes became data swamps. Some datalake implementations required expensive ‘cleansing pumps’ to make them navigable again.
User support arrangements Consider the availability and quality of support from the provider or vendor, including documentation, tutorials, forums, customer service, etc. Check out the Kubeflow documentation. Metaflow Metaflow helps data scientists and machine learning engineers build, manage, and deploy data science projects.
There are 5 stages in unstructured data management: Data collection Data integration Data cleaning Data annotation and labeling Data preprocessing Data Collection The first stage in the unstructured data management workflow is data collection. mp4,webm, etc.), and audio files (.wav,mp3,acc,
As organisations grapple with this vast amount of information, understanding the main components of Big Data becomes essential for leveraging its potential effectively. Key Takeaways Big Data originates from diverse sources, including IoT and social media. Datalakes and cloud storage provide scalable solutions for large datasets.
As organisations grapple with this vast amount of information, understanding the main components of Big Data becomes essential for leveraging its potential effectively. Key Takeaways Big Data originates from diverse sources, including IoT and social media. Datalakes and cloud storage provide scalable solutions for large datasets.
Challenges associated with these stages involve not knowing all touchpoints where data is persisted, maintaining a data pre-processing pipeline for document chunking, choosing a chunking strategy, vector database, and indexing strategy, generating embeddings, and any manual steps to purge data from vector stores and keep it in sync with source data.
Unlike structured data, unstructured data doesn’t fit neatly into predefined models or databases, making it harder to analyse using traditional methods. So, we must understand the different unstructured data types and effectively process them to uncover hidden patterns.
This allows the Masters to scale analytics and AI wherever their data resides, through open formats and integration with existing databases and tools. “Hole distances and pin positions vary from round to round and year to year; these factors are important as we stage the data.”
These teams are as follows: Advanced analytics team (datalake and data mesh) – Data engineers are responsible for preparing and ingesting data from multiple sources, building ETL (extract, transform, and load) pipelines to curate and catalog the data, and prepare the necessary historical data for the ML use cases.
You can integrate existing data from AWS datalakes, Amazon Simple Storage Service (Amazon S3) buckets, or Amazon Relational Database Service (Amazon RDS) instances with services such as Amazon Bedrock and Amazon Q. This helps catch any fabricated or misrepresented quantitative information in the summaries.
When the automated content processing steps are complete, you can use the output for downstream tasks, such as to invoke different components in a customer service backend application, or to insert the generated tags into metadata of each document for product recommendation. The stored data is visualized in a BI dashboard using QuickSight.
Statistical Data Analysis: Oftentimes, important information is buried within a document that contains important clues for labeling. If these documents need to be manually processed to pull out information needed for model training, then that would be an arduous and error-prone process.
Statistical Data Analysis: Oftentimes, important information is buried within a document that contains important clues for labeling. If these documents need to be manually processed to pull out information needed for model training, then that would be an arduous and error-prone process.
It includes processes that trace and document the origin of data, models and associated metadata and pipelines for audits. This type of next-generation data store combines a datalake’s flexibility with a data warehouse’s performance and lets you scale AI workloads no matter where they reside.
A common problem solved by phData is the migration from an existing data platform to the Snowflake Data Cloud , in the best possible manner. Sources The sources involved could influence or determine the options available for the data ingestion tool(s). These could include other databases, datalakes, SaaS applications (e.g.
Recognizing these specific needs, Fivetran has developed a range of connectors, including dedicated applications, databases, files, and events, which can accommodate the diverse formats used by healthcare systems. Addressing these needs may pose challenges that lead to the implementation of custom solutions rather than a uniform approach.
Modernizing your data infrastructure to hybrid cloud for applications, analytics and gen AI Adopting multicloud and hybrid strategies is becoming mandatory, requiring databases that support flexible deployments across the hybrid cloud. This ensures you have a data foundation that grows with your data needs, wherever your data resides.
The DataRobot AI Platform seamlessly integrates with Azure cloud services, including Azure Machine Learning, Azure DataLake Storage Gen 2 (ADLS), Azure Synapse Analytics, and Azure SQL database. This drastically improves productivity of teams and allows them to scale business results.
They encompass all the origins from which data is collected, including: Internal Data Sources: These include databases, enterprise resource planning (ERP) systems, customer relationship management (CRM) systems, and flat files within an organization. Data can be structured (e.g., databases), semi-structured (e.g.,
Key Takeaways Big Data focuses on collecting, storing, and managing massive datasets. Data Science extracts insights and builds predictive models from processed data. Big Data technologies include Hadoop, Spark, and NoSQL databases. Data Science uses Python, R, and machine learning frameworks.
The importance of ETL tools is underscored by their ability to handle diverse data sources, from relational databases to cloud-based services. This capability allows organizations to consolidate disparate data into a unified repository for analytics and reporting, providing insights that can drive strategic decisions.
Airline Reporting Corporation (ARC) sells data products to travel agencies and airlines. Lineage helps them identify the source of bad data to fix the problem fast. Manual lineage will give ARC a fuller picture of how data was created between AWS S3 datalake, Snowflake cloud data warehouse and Tableau (and how it can be fixed).
These encoder-only architecture models are fast and effective for many enterprise NLP tasks, such as classifying customer feedback and extracting information from large documents. While they require task-specific labeled data for fine tuning, they also offer clients the best cost performance trade-off for non-generative use cases.
Data integration is essentially the Extract and Load portion of the Extract, Load, and Transform (ELT) process. Data ingestion involves connecting your data sources, including databases, flat files, streaming data, etc, to your data warehouse. Snowflake provides native ways for data ingestion.
More on this topic later; but for now, keep in mind that the simplest method is to create a naming convention for database objects that allows you to identify the owner and associated budget. The extended period will allow you to perform Time Travel activities, such as undropping tables or comparing new data against historical values.
By leveraging cloud-based data platforms such as Snowflake Data Cloud , these commercial banks can aggregate and curate their data to understand individual customer preferences and offer relevant and personalized products.
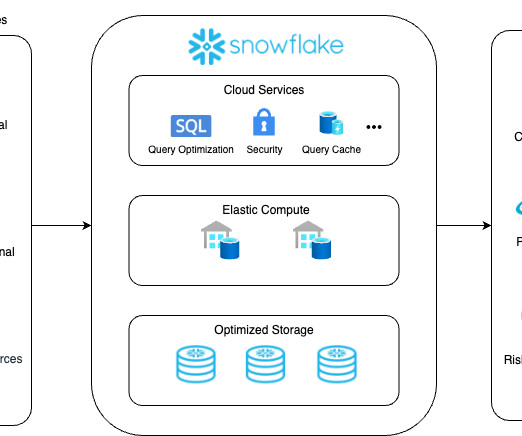
Thus, the solution allows for scaling data workloads independently from one another and seamlessly handling data warehousing, datalakes , data sharing, and engineering. Snowflake Database Pros Extensive Storage Opportunities Snowflake provides affordability, scalability, and a user-friendly interface.
The explosion in data and database types is a major pain point of the modern data consumer. What is Data Search & Discovery? According to IDC , more than 59 zettabytes (59,000,000,000,000,000,000,000 bytes) of data was created, captured, and consumed in the world in 2020. Today they have too much.
References : Links to internal or external documentation with background information or specific information used within the analysis presented in the notebook. Data to explore: Outline the tables or datasets you’re exploring/analyzing and reference their sources or link their data catalog entries. documentation.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content