This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Generative AI models have the potential to revolutionize enterprise operations, but businesses must carefully consider how to harness their power while overcoming challenges such as safeguarding data and ensuring the quality of AI-generated content. Set up the database access and network access.
Data Collection and Integration Data engineers are responsible for designing robust data collection systems that gather information from various IoT devices and sensors. This data is then integrated into centralized databases for further processing and analysis.
Google AutoML for NaturalLanguage goes GA Extracting meaning from text is still a challenging and important task faced by many organizations. Google AutoML for NLP (NaturalLanguageProcessing) provides sentiment analysis, classification, and entity extraction from text. Data Labeling in Azure ML Studio.
One such area that is evolving is using naturallanguageprocessing (NLP) to unlock new opportunities for accessing data through intuitive SQL queries. Instead of dealing with complex technical code, business users and data analysts can ask questions related to data and insights in plain language.
The Future of the Single Source of Truth is an Open DataLake Organizations that strive for high-performance data systems are increasingly turning towards the ELT (Extract, Load, Transform) model using an open datalake. To DIY you need to: host an API, build a UI, and run or rent a database.
Why it’s challenging to process and manage unstructured data Unstructured data makes up a large proportion of the data in the enterprise that can’t be stored in a traditional relational database management systems (RDBMS). These services write the output to a datalake.
During the embeddings experiment, the dataset was converted into embeddings, stored in a vector database, and then matched with the embeddings of the question to extract context. The idea was to use the LLM to first generate a SQL statement from the user question, presented to the LLM in naturallanguage.
RAG is an advanced naturallanguageprocessing technique that combines knowledge retrieval with generative text models. RAG combines the powers of pre-trained language models with a retrieval-based approach to generate more informed and accurate responses.
Businesses can use LLMs to gain valuable insights, streamline processes, and deliver enhanced customer experiences. In the first step, an AWS Lambda function reads and validates the file, and extracts the raw data. The raw data is processed by an LLM using a preconfigured user prompt. The Step Functions workflow starts.
Text analytics: Text analytics, also known as text mining, deals with unstructured text data, such as customer reviews, social media comments, or documents. It uses naturallanguageprocessing (NLP) techniques to extract valuable insights from textual data. Ensure that data is clean, consistent, and up-to-date.
The combination of large language models (LLMs), including the ease of integration that Amazon Bedrock offers, and a scalable, domain-oriented data infrastructure positions this as an intelligent method of tapping into the abundant information held in various analytics databases and datalakes.
eSentire has over 2 TB of signal data stored in their Amazon Simple Storage Service (Amazon S3) datalake. This further step updates the FM by training with data labeled by security experts (such as Q&A pairs and investigation conclusions).
Structured Query Language (SQL) is a complex language that requires an understanding of databases and metadata. This generative AI task is called text-to-SQL, which generates SQL queries from naturallanguageprocessing (NLP) and converts text into semantically correct SQL. on Amazon Bedrock.
As organisations grapple with this vast amount of information, understanding the main components of Big Data becomes essential for leveraging its potential effectively. Key Takeaways Big Data originates from diverse sources, including IoT and social media. Datalakes and cloud storage provide scalable solutions for large datasets.
As organisations grapple with this vast amount of information, understanding the main components of Big Data becomes essential for leveraging its potential effectively. Key Takeaways Big Data originates from diverse sources, including IoT and social media. Datalakes and cloud storage provide scalable solutions for large datasets.
ML operationalization summary As defined in the post MLOps foundation roadmap for enterprises with Amazon SageMaker , ML and operations (MLOps) is the combination of people, processes, and technology to productionize machine learning (ML) solutions efficiently. In the case of FMs, they need either billions of labeled or unlabeled data points.
Social media conversations, comments, customer reviews, and image data are unstructured in nature and hold valuable insights, many of which are still being uncovered through advanced techniques like NaturalLanguageProcessing (NLP) and machine learning. Tools like Unstructured.io
Learn more The Best Tools, Libraries, Frameworks and Methodologies that ML Teams Actually Use – Things We Learned from 41 ML Startups [ROUNDUP] Key use cases and/or user journeys Identify the main business problems and the data scientist’s needs that you want to solve with ML, and choose a tool that can handle them effectively.
There are 5 stages in unstructured data management: Data collection Data integration Data cleaning Data annotation and labeling Data preprocessing Data Collection The first stage in the unstructured data management workflow is data collection. mp4,webm, etc.), and audio files (.wav,mp3,acc,
This allows users to accomplish different NaturalLanguageProcessing (NLP) functional tasks and take advantage of IBM vetted pre-trained open-source foundation models. Encoder-decoder and decoder-only large language models are available in the Prompt Lab today. To bridge the tuning gap, watsonx.ai
Foundation models: The power of curated datasets Foundation models , also known as “transformers,” are modern, large-scale AI models trained on large amounts of raw, unlabeled data. It allows for automation and integrations with existing databases and provides tools that permit a simplified setup and user experience.
As a first step, they wanted to transcribe voice calls and analyze those interactions to determine primary call drivers, including issues, topics, sentiment, average handle time (AHT) breakdowns, and develop additional naturallanguageprocessing (NLP)-based analytics. The Results PCA helped accelerate time to market.
Mai-Lan Tomsen Bukovec, Vice President, Technology | AIM250-INT | Putting your data to work with generative AI Thursday November 30 | 12:30 PM – 1:30 PM (PST) | Venetian | Level 5 | Palazzo Ballroom B How can you turn your datalake into a business advantage with generative AI?
For example, data catalogs have evolved to deliver governance capabilities like managing data quality and data privacy and compliance. It uses metadata and data management tools to organize all data assets within your organization. After all, Alex may not be aware of all the data available to her.
Cloudera Cloudera is a cloud-based platform that provides businesses with the tools they need to manage and analyze data. They offer a variety of services, including data warehousing, datalakes, and machine learning. ArangoDB ArangoDB is a company that provides a database platform for graph and document data.
Voice-based queries use NaturalLanguageProcessing (NLP) and sentiment analysis for speech recognition. Customer service use cases Not only can ML understand what customers are saying, but it also understands their tone and can direct them to appropriate customer service agents for customer support.
The amount of data generated in the digital world is increasing by the minute! This massive amount of data is termed “big data.” We may classify the data as structured, unstructured, or semi-structured. Data that is structured or semi-structured is relatively easy to store, process, and analyze. […].
Storage Solutions: Secure and scalable storage options like Azure Blob Storage and Azure DataLake Storage. Key features and benefits of Azure for Data Science include: Scalability: Easily scale resources up or down based on demand, ideal for handling large datasets and complex computations.
Also consider using Amazon Security Lake to automatically centralize security data from AWS environments, SaaS providers, on premises, and cloud sources into a purpose-built datalake stored in your account. Emily Soward is a Data Scientist with AWS Professional Services.
Each document is divided into chunks to ease the indexing and retrieval processes based on semantic meaning. Embeddings generation – An embeddings model is used to encode the semantic information of each chunk into an embeddings vector, which is stored in a vector database, enabling similarity search of user queries.
The job reads features, generates predictions, and writes them to a database. The client queries and reads the predictions from the database when needed. Inside the engine is a metrics data processor that: Reads the telemetry data, Calculates different operational metrics at regular intervals, And stores them in a metrics database.
This post dives deep into Amazon Bedrock Knowledge Bases , which helps with the storage and retrieval of data in vector databases for RAG-based workflows, with the objective to improve large language model (LLM) responses for inference involving an organization’s datasets. The LLM response is passed back to the agent.
Many organizations store their data in structured formats within data warehouses and datalakes. Amazon Bedrock Knowledge Bases offers a feature that lets you connect your RAG workflow to structured data stores. The key is to choose a solution that can effectively host your database and compute infrastructure.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








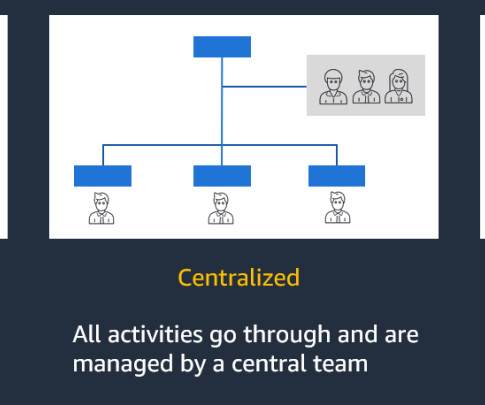













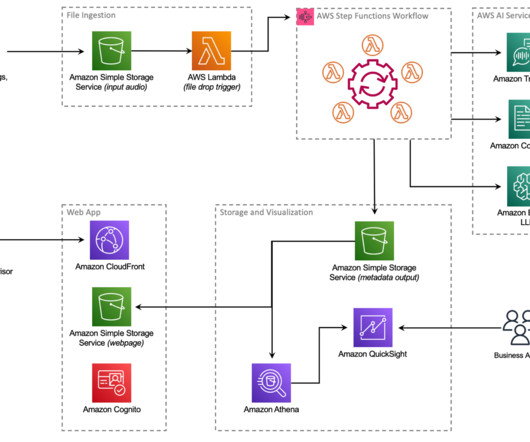










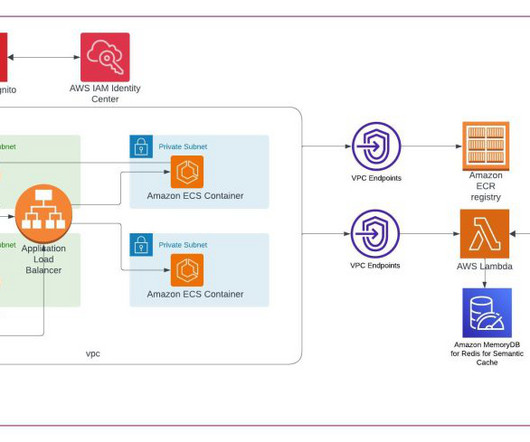






Let's personalize your content