This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This enables sales teams to interact with our internal sales enablement collateral, including sales plays and first-call decks, as well as customer references, customer- and field-facing incentive programs, and content on the AWS website, including blog posts and service documentation.
The platform helped the agency digitize and process forms, pictures, and other documents. The federal government agency Precise worked with needed to automate manual processes for document intake and image processing. For image processing, the agency does a lot of inspections and takes a lot of pictures.
With the amount of data companies are using growing to unprecedented levels, organizations are grappling with the challenge of efficiently managing and deriving insights from these vast volumes of structured and unstructured data. What is a DataLake? Consistency of data throughout the datalake.
When it was no longer a hard requirement that a physical data model be created upon the ingestion of data, there was a resulting drop in richness of the description and consistency of the data stored in Hadoop. You did not have to understand or prepare the data to get it into Hadoop, so people rarely did.
Data management problems can also lead to data silos; disparate collections of databases that don’t communicate with each other, leading to flawed analysis based on incomplete or incorrect datasets. One way to address this is to implement a datalake: a large and complex database of diverse datasets all stored in their original format.
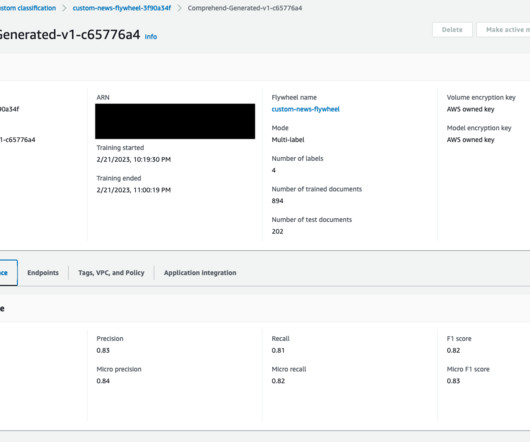
Amazon Comprehend is a managed AI service that uses natural language processing (NLP) with ready-made intelligence to extract insights about the content of documents. It develops insights by recognizing the entities, key phrases, language, sentiments, and other common elements in a document.
You can safely use an Apache Kafka cluster for seamless data movement from the on-premise hardware solution to the datalake using various cloud services like Amazon’s S3 and others. It will enable you to quickly transform and load the data results into Amazon S3 datalakes or JDBC data stores.
Solution overview Amazon Comprehend is a fully managed service that uses natural language processing (NLP) to extract insights about the content of documents. This feature also allows you to automate model retraining after new datasets are ingested and available in the flywheel´s datalake.
Generative AI models have the potential to revolutionize enterprise operations, but businesses must carefully consider how to harness their power while overcoming challenges such as safeguarding data and ensuring the quality of AI-generated content. As a Data Engineer he was involved in applying AI/ML to fraud detection and office automation.
This archive, along with 765,933 varied-quality inspection photographs, some over 15 years old, presented a significant data processing challenge. Processing these images and scanned documents is not a cost- or time-efficient task for humans, and requires highly performant infrastructure that can reduce the time to value.
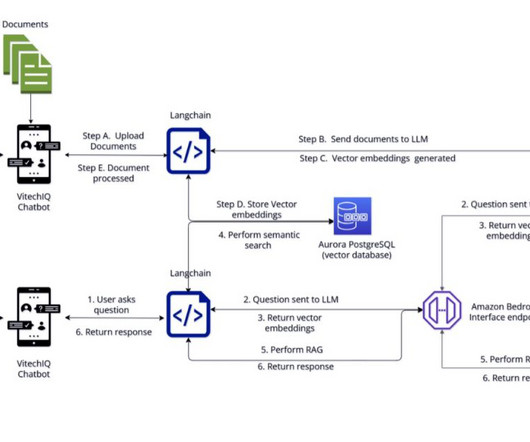
To serve their customers, Vitech maintains a repository of information that includes product documentation (user guides, standard operating procedures, runbooks), which is currently scattered across multiple internal platforms (for example, Confluence sites and SharePoint folders).
Amazon AppFlow was used to facilitate the smooth and secure transfer of data from various sources into ODAP. Additionally, Amazon Simple Storage Service (Amazon S3) served as the central datalake, providing a scalable and cost-effective storage solution for the diverse data types collected from different systems.
The Product Stewardship department is responsible for managing a large collection of regulatory compliance documents. Example questions might be “What are the restrictions for CMR substances?”, “How long do I need to keep the documents related to a toluene sale?”, or “What is the reach characterization ratio and how do I calculate it?”
Text analytics: Text analytics, also known as text mining, deals with unstructured text data, such as customer reviews, social media comments, or documents. It uses natural language processing (NLP) techniques to extract valuable insights from textual data. Poor data integration can lead to inaccurate insights.
Lake File System ( LakeFS for short) is an open-source version control tool, launched in 2020, to bridge the gap between version control and those big data solutions (datalakes). It provides ACID transactions, scalable metadata management, and schema enforcement to datalakes.
Then the transcripts of contacts become available to CSBA to extract actionable insights through millions of customer contacts for the sellers, and the data is stored in the Seller DataLake. After the AI/ML-based analytics, all actionable insights are generated and then stored in the Seller DataLake.
The IDP Well-Architected Lens is intended for all AWS customers who use AWS to run intelligent document processing (IDP) solutions and are searching for guidance on how to build secure, efficient, and reliable IDP solutions on AWS. This post focuses on the Operational Excellence pillar of the IDP solution.
You can find instructions on how to do this in the AWS documentation for your chosen SDK. AWS credentials – Configure your AWS credentials in your development environment to authenticate with AWS services. We walk through a Python example in this post.
Intelligent document processing , translation and summarization, flexible and insightful responses for customer support agents, personalized marketing content, and image and code generation are a few use cases using generative AI that organizations are rolling out in production.
Text, images, audio, and videos are common examples of unstructured data. Most companies produce and consume unstructured data such as documents, emails, web pages, engagement center phone calls, and social media. The steps of the workflow are as follows: Integrated AI services extract data from the unstructured data.
It now also supports PDF documents. Azure Data Factory Preserves Metadata during File Copy When performing a File copy between Amazon S3, Azure Blob, and Azure DataLake Gen 2, the metadata will be copied as well. Not a huge update but still a nice feature. Azure Database for MySQL now supports MySQL 8.0
You can explore its capabilities through the official Azure ML Studio documentation. Azure ML SDK : For those who prefer a code-first approach, the Azure Machine Learning Python SDK allows data scientists to work in familiar environments like Jupyter notebooks while leveraging Azure’s capabilities.
The agent knowledge base stores Amazon Bedrock service documentation, while the cache knowledge base contains curated and verified question-answer pairs. For this example, you will ingest Amazon Bedrock documentation in the form of the User Guide PDF into the Amazon Bedrock knowledge base. This will be the primary dataset.
Or we create a datalake, which quickly degenerates to a data swamp. Various initiatives to create a knowledge graph of these systems have been only partially successful due to the depth of legacy knowledge, incomplete documentation and technical debt incurred over decades.
Menninger states that modern data governance programs can provide a more significant ROI at a much faster pace. Ventana found that the most time-consuming part of an organization’s analytic efforts is accessing and preparing data; this is the case for more than one-half (55%) of respondents. Curious to learn more?
How to build a chatbot that answers questions about documentation and cites its sources The tutorial was initially hosted via a live stream on our Learn AI Discord. Three 5-minute reads/videos to keep you learning 1.How These considerations include cost, complexity, expertise, time to value, and competitive advantage.
It also excels at creating concise, relevant, and customizable summaries of text and documents. Embedding Models : Cohere’s embedding models enhance applications by understanding the meaning of text data at scale. Trained to respond to user instructions, Command proves immediately valuable in practical business applications.
Our goal was to improve the user experience of an existing application used to explore the counters and insights data. The data is stored in a datalake and retrieved by SQL using Amazon Athena. The question is sent through a retrieval-augmented generation (RAG) process, which finds similar documents.
Great Expectations GitHub | Website Great Expectations (GX) helps data teams build a shared understanding of their data through quality testing, documentation, and profiling. With Great Expectations , data teams can express what they “expect” from their data using simple assertions.
These teams are as follows: Advanced analytics team (datalake and data mesh) – Data engineers are responsible for preparing and ingesting data from multiple sources, building ETL (extract, transform, and load) pipelines to curate and catalog the data, and prepare the necessary historical data for the ML use cases.
To combine the collected data, you can integrate different data producers into a datalake as a repository. A central repository for unstructured data is beneficial for tasks like analytics and data virtualization. Data Cleaning The next step is to clean the data after ingesting it into the datalake.
models are trained on IBM’s curated, enterprise-focused datalake. Fortunately, data stores serve as secure data repositories and enable foundation models to scale in both terms of their size and their training data. Foundation models focused on enterprise value IBM’s watsonx.ai All watsonx.ai
As organisations grapple with this vast amount of information, understanding the main components of Big Data becomes essential for leveraging its potential effectively. Key Takeaways Big Data originates from diverse sources, including IoT and social media. Datalakes and cloud storage provide scalable solutions for large datasets.
As organisations grapple with this vast amount of information, understanding the main components of Big Data becomes essential for leveraging its potential effectively. Key Takeaways Big Data originates from diverse sources, including IoT and social media. Datalakes and cloud storage provide scalable solutions for large datasets.
And where data was available, the ability to access and interpret it proved problematic. Big data can grow too big fast. Left unchecked, datalakes became data swamps. Some datalake implementations required expensive ‘cleansing pumps’ to make them navigable again.
User support arrangements Consider the availability and quality of support from the provider or vendor, including documentation, tutorials, forums, customer service, etc. Check out the Kubeflow documentation. Metaflow Metaflow helps data scientists and machine learning engineers build, manage, and deploy data science projects.
Third, despite the larger adoption of centralized analytics solutions like datalakes and warehouses, complexity rises with different table names and other metadata that is required to create the SQL for the desired sources. You may have to recreate the capability for every database to enable users with NLP-based SQL generation.
It includes processes that trace and document the origin of data, models and associated metadata and pipelines for audits. How to scale AL and ML with built-in governance A fit-for-purpose data store built on an open lakehouse architecture allows you to scale AI and ML while providing built-in governance tools.
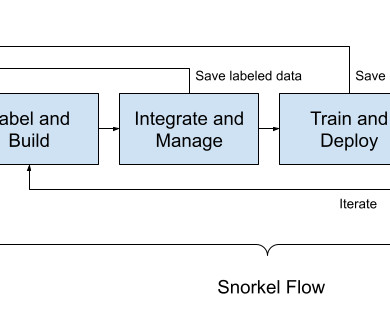
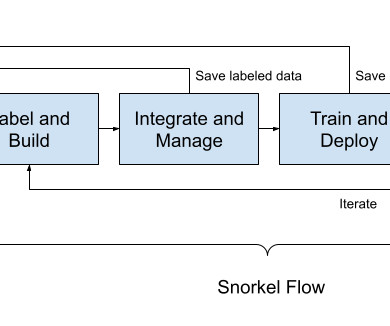
Statistical Data Analysis: Oftentimes, important information is buried within a document that contains important clues for labeling. If these documents need to be manually processed to pull out information needed for model training, then that would be an arduous and error-prone process.
Statistical Data Analysis: Oftentimes, important information is buried within a document that contains important clues for labeling. If these documents need to be manually processed to pull out information needed for model training, then that would be an arduous and error-prone process.
Figure 1 illustrates the typical metadata subjects contained in a data catalog. Figure 1 – Data Catalog Metadata Subjects. Datasets are the files and tables that data workers need to find and access. They may reside in a datalake, warehouse, master data repository, or any other shared data resource.
Amazon Kendra supports a variety of document formats , such as Microsoft Word, PDF, and text from various data sources. In this post, we focus on extending the document support in Amazon Kendra to make images searchable by their displayed content. This means you can manipulate and ingest your data as needed.
Semi-Structured Data: Data that has some organizational properties but doesn’t fit a rigid database structure (like emails, XML files, or JSON data used by websites). Unstructured Data: Data with no predefined format (like text documents, social media posts, images, audio files, videos).
Challenges and considerations with RAG architectures Typical RAG architecture at a high level involves three stages: Source data pre-processing Generating embeddings using an embedding LLM Storing the embeddings in a vector store. Vector embeddings include the numeric representations of text data within your documents.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content