This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
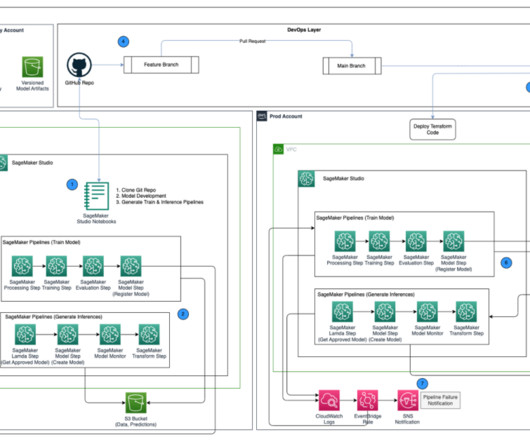
Amazon Redshift is the most popular cloud data warehouse that is used by tens of thousands of customers to analyze exabytes of data every day. SageMaker Studio is the first fully integrated development environment (IDE) for ML. Solution overview The following diagram illustrates the solution architecture for each option.
Companies are faced with the daunting task of ingesting all this data, cleansing it, and using it to provide outstanding customer experience. Typically, companies ingest data from multiple sources into their datalake to derive valuable insights from the data. Run the AWS Glue ML transform job.
Many of these applications are complex to build because they require collaboration across teams and the integration of data, tools, and services. Data engineers use data warehouses, datalakes, and analytics tools to load, transform, clean, and aggregate data. Choose Continue.
This combination of great models and continuous adaptation is what will lead to a successful machine learning (ML) strategy. MLOps focuses on the intersection of data science and data engineering in combination with existing DevOps practices to streamline model delivery across the ML development lifecycle.
Released in 2022, DagsHub’s Direct Data Access (DDA for short) allows Data Scientists and Machine Learning engineers to stream files from DagsHub repository without needing to download them to their local environment ahead of time. This can prevent lengthy datadownloads to the local disks before initiating their mode training.
ML operationalization summary As defined in the post MLOps foundation roadmap for enterprises with Amazon SageMaker , ML and operations (MLOps) is the combination of people, processes, and technology to productionize machine learning (ML) solutions efficiently.
If you are a returning user to SageMaker Studio, in order to ensure Salesforce Data Cloud is enabled, upgrade to the latest Jupyter and SageMaker Data Wrangler kernels. This completes the setup to enable data access from Salesforce Data Cloud to SageMaker Studio to build AI and machine learning (ML) models.
Alignment to other tools in the organization’s tech stack Consider how well the MLOps tool integrates with your existing tools and workflows, such as data sources, data engineering platforms, code repositories, CI/CD pipelines, monitoring systems, etc. and Pandas or Apache Spark DataFrames.
From data processing to quick insights, robust pipelines are a must for any ML system. Often the Data Team, comprising Data and ML Engineers , needs to build this infrastructure, and this experience can be painful. However, efficient use of ETL pipelines in ML can help make their life much easier.
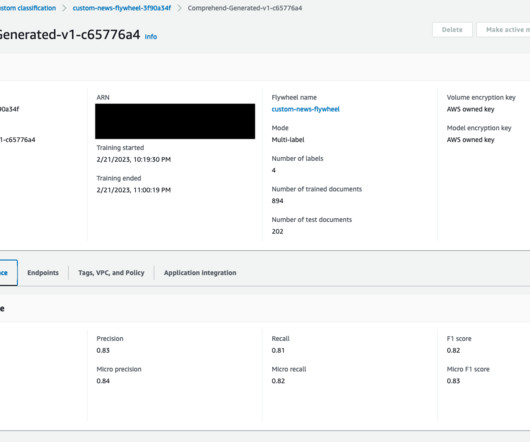
Flywheel creates a datalake (in Amazon S3) in your account where all the training and test data for all versions of the model are managed and stored. Periodically, the new labeled data (to retrain the model) can be made available to flywheel by creating datasets. One for the datalake for Comprehend flywheel.
These tools may have their own versioning system, which can be difficult to integrate with a broader data version control system. For instance, our datalake could contain a variety of relational and non-relational databases, files in different formats, and data stored using different cloud providers. DVC Git LFS neptune.ai
Photo by Zbynek Burival on Unsplash Time series forecasting is a specific machine learning (ML) discipline that enables organizations to make informed planning decisions. Here, accuracy means that future estimates produced by the ML model end up being as close as possible to the actual future.
Third, despite the larger adoption of centralized analytics solutions like datalakes and warehouses, complexity rises with different table names and other metadata that is required to create the SQL for the desired sources. Subsets of IMDb data are available for personal and non-commercial use. format('parquet').option('path',
Building out a machine learning operations (MLOps) platform in the rapidly evolving landscape of artificial intelligence (AI) and machine learning (ML) for organizations is essential for seamlessly bridging the gap between data science experimentation and deployment while meeting the requirements around model performance, security, and compliance.
Managing unstructured data is essential for the success of machine learning (ML) projects. Without structure, data is difficult to analyze and extracting meaningful insights and patterns is challenging. This article will discuss managing unstructured data for AI and ML projects. What is Unstructured Data?
Introduction With the increase in visual data, it can be hard to sort and classify videos, making it difficult for Search Engine Optimization (SEO) algorithms to sort out the video data. YouTube has a vast amount of videos, Instagram reels and TikToks are trending, and OTT platforms have emerged and contributed to the video datalake.
Amazon Kendra is an intelligent search service powered by machine learning (ML). Amazon Kendra supports a variety of document formats , such as Microsoft Word, PDF, and text from various data sources. Image captioning with GenAI Image description with GenAI involves using ML algorithms to generate textual descriptions of images.
This begins the process of converting the data stored in the S3 bucket into vector embeddings in your OpenSearch Serverless vector collection. Note: The syncing operation can take minutes to hours to complete, based on the size of the dataset stored in your S3 bucket.
Genie has built-in connectors that bring in data from every channel—mobile, web, APIs—even legacy data through MuleSoft and historical data from proprietary datalakes, in real time. . Data Stories help you understand what’s changing, why, and what to do. So how does this all work? This is available today.
Genie has built-in connectors that bring in data from every channel—mobile, web, APIs—even legacy data through MuleSoft and historical data from proprietary datalakes, in real time. . Data Stories help you understand what’s changing, why, and what to do. So how does this all work? This is available today.
It is suitable for a wide range of use cases, such as datalake storage, backup and recovery, and content delivery. Key features of MinIO Compatibility with S3 applications, high throughput, and low latency. MinIO can be easily deployed on various platforms, including on-premises hardware or in the cloud.
Organizations can unite their siloed data and securely share governed data while executing diverse analytic workloads. Snowflake’s engine provides a solution for data warehousing, datalakes, data engineering, data science, data application development, and data sharing.
This article was originally an episode of the MLOps Live , an interactive Q&A session where ML practitioners answer questions from other ML practitioners. Every episode is focused on one specific ML topic, and during this one, we talked to Michal Tadeusiak about managing computer vision projects. Then we are there to help.
Data pipeline stages But before delving deeper into the technical aspects of these tools, let’s quickly understand the core components of a data pipeline succinctly captured in the image below: Data pipeline stages | Source: Author What does a good data pipeline look like?
Genie has built-in connectors that bring in data from every channel—mobile, web, APIs—even legacy data through MuleSoft and historical data from proprietary datalakes, in real time. . Data Stories help you understand what’s changing, why, and what to do. So how does this all work? This is available today.
This article was originally an episode of the MLOps Live , an interactive Q&A session where ML practitioners answer questions from other ML practitioners. Every episode is focused on one specific ML topic, and during this one, we talked to Kuba Cieślik, founder and AI Engineer at tuul.ai , about building visual search engines.
LLM companies are businesses that specialize in developing and deploying Large Language Models (LLMs) and advanced machine learning (ML) models. WhyLabs WhyLabs is renowned for its versatile and robust machine learning (ML) observability platform. million downloads, demonstrating its widespread adoption and effectiveness.
Starting today, you can interactively prepare large datasets, create end-to-end data flows, and invoke automated machine learning (AutoML) experiments on petabytes of data—a substantial leap from the previous 5 GB limit. Organizations often struggle to extract meaningful insights and value from their ever-growing volume of data.
This article was originally an episode of the MLOps Live , an interactive Q&A session where ML practitioners answer questions from other ML practitioners. Every episode is focused on one specific ML topic, and during this one, we talked to David Hershey about GPT-3 and the feature of MLOps. David: Thank you.
His mission is to enable customers achieve their business goals and create value with data and AI. He helps architect solutions across AI/ML applications, enterprise data platforms, data governance, and unified search in enterprises. Modify the stack name or leave as default, then choose Next.
Run the cell under Sample document download to download the HTML file, create a new S3 bucket, and upload the HTML file to the bucket. He is passionate about distributed computing and using ML/AI for designing and building end-to-end solutions to address customers’ Data Integration needs. Choose Create notebook.
This blog is a collection of those insights, but for the full trendbook, we recommend downloading the PDF. With that, let’s get into the governance trends for data leaders! Just click this button and fill out the form to download it. Chief Information Officer, Legal Industry For all the quotes, download the Trendbook today!
Download the notebook file to use in this post. data # Assing local directory path to a python variable local_data_path = "./data/" data/" # Assign S3 bucket name to a python variable. . This enables you to use Aurora for generative AI RAG-based use cases by storing vectors with the rest of the data.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


































Let's personalize your content