This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Be sure to check out his talk, “ Apache Kafka for Real-Time Machine Learning Without a DataLake ,” there! The combination of data streaming and machine learning (ML) enables you to build one scalable, reliable, but also simple infrastructure for all machine learning tasks using the Apache Kafka ecosystem.
In the ever-evolving world of big data, managing vast amounts of information efficiently has become a critical challenge for businesses across the globe. As datalakes gain prominence as a preferred solution for storing and processing enormous datasets, the need for effective data version control mechanisms becomes increasingly evident.
In this contributed article, Tom Scott, CEO of Streambased, outlines the path event streaming systems have taken to arrive at the point where they must adopt analytical use cases and looks at some possible futures in this area.
Unified data storage : Fabric’s centralized datalake, Microsoft OneLake, eliminates data silos and provides a unified storage system, simplifying data access and retrieval. OneLake is designed to store a single copy of data in a unified location, leveraging the open-source Apache Parquet format.
Data management problems can also lead to data silos; disparate collections of databases that don’t communicate with each other, leading to flawed analysis based on incomplete or incorrect datasets. One way to address this is to implement a datalake: a large and complex database of diverse datasets all stored in their original format.
For many enterprises, a hybrid cloud datalake is no longer a trend, but becoming reality. Due to these needs, hybrid cloud datalakes emerged as a logical middle ground between the two consumption models. earthquake, flood, or fire), where the data collected does not need to be as tightly controlled.
With this full-fledged solution, you don’t have to spend all your time and effort combining different services or duplicating data. Overview of One Lake Fabric features a lake-centric architecture, with a central repository known as OneLake.
Real-Time ML with Spark and SBERT, AI Coding Assistants, DataLake Vendors, and ODSC East Highlights Getting Up to Speed on Real-Time Machine Learning with Spark and SBERT Learn more about real-time machine learning by using this approach that uses Apache Spark and SBERT. Well, these libraries will give you a solid start.
You can safely use an Apache Kafka cluster for seamless data movement from the on-premise hardware solution to the datalake using various cloud services like Amazon’s S3 and others. It will enable you to quickly transform and load the data results into Amazon S3 datalakes or JDBC data stores.
Data and governance foundations – This function uses a data mesh architecture for setting up and operating the datalake, central feature store, and data governance foundations to enable fine-grained data access. This framework considers multiple personas and services to govern the ML lifecycle at scale.
The Future of the Single Source of Truth is an Open DataLake Organizations that strive for high-performance data systems are increasingly turning towards the ELT (Extract, Load, Transform) model using an open datalake. See them here!
Although setting up a database to run your analyses may seem like an arduous task, modern open-source time series databases can provide significant benefits to any scientist running time series analysis on a large data set — and with much less effort than you might imagine. Interested in attending an ODSC event?
Even Forbes Tech Council has written about the benefits of datalakes in Fortnite. The game’s parent company, Epic Games, processes millions of events each minute, and its mountain of data grows steadily. Processing and analyzing this data — petabytes worth — must happen somewhere.
Recent events including Tropical Cyclone Gabrielle have highlighted the susceptibility of the grid to extreme weather and emphasized the need for climate adaptation with resilient infrastructure. The model is then trained using a fully managed infrastructure, validated, and published to the Amazon SageMaker Model Registry.
AI-driven revenue optimization The new system enables hoteliers to manage pricing dynamically , making data-driven adjustments across rooms, event spaces, and F&B outlets. “Our new RMS empowers revenue managers to evolve into strategic decision-makers, effectively translating data into tangible financial outcomes.”
Diagnostic analytics: Diagnostic analytics goes a step further by analyzing historical data to determine why certain events occurred. By understanding the “why” behind past events, organizations can make informed decisions to prevent or replicate them. Ensure that data is clean, consistent, and up-to-date.
Amazon AppFlow was used to facilitate the smooth and secure transfer of data from various sources into ODAP. Additionally, Amazon Simple Storage Service (Amazon S3) served as the central datalake, providing a scalable and cost-effective storage solution for the diverse data types collected from different systems.
response = bedrock_runtime.invoke_model_with_response_stream(**kwargs) stream = response.get('body') if stream: for event in stream: chunk = event.get('chunk') if chunk: print(json.loads(chunk.get('bytes')).get('completion'), Import the dependencies and create the Amazon Bedrock client: import boto3, json bedrock_runtime = boto3.client(
Working with AWS, Light & Wonder recently developed an industry-first secure solution, Light & Wonder Connect (LnW Connect), to stream telemetry and machine health data from roughly half a million electronic gaming machines distributed across its casino customer base globally when LnW Connect reaches its full potential.
If the question was Whats the schedule for AWS events in December?, AWS usually announces the dates for their upcoming # re:Invent event around 6-9 months in advance. our solution would provide the verified re:Invent dates to guide the Amazon Bedrock agents response with additional context.
Beyond his technical achievements, James is a sought-after speaker and is a prolific voice in the data community through his blog, JamesSerra.com. James Serra discusses data lakehouses, which merge datalakes and data warehouses. It lets you store a wide variety of data in a cost-effective way, like a datalake.
It is about hurricanes and big events like the California wildfires, but it is also about complex things like satellite launches, for example, or big building projects. A lot of people in our audience are looking at implementing datalakes or are in the middle of big datalake initiatives.
They are working through organizational design challenges while also establishing foundational data management capabilities like metadata management and data governance that will allow them to offer trusted data to the business in a timely and efficient manner for analytics and AI.”
A novel approach to solve this complex security analytics scenario combines the ingestion and storage of security data using Amazon Security Lake and analyzing the security data with machine learning (ML) using Amazon SageMaker. Store new security logs in an S3 bucket and queue events in Amazon Simple Queue Service (Amazon SQS).
While there is more of a push to use cloud data for off-site backup , this method comes with its own caveats. In the event of a network shutdown or failure, it may take much longer to restore functionality (and therefore connection) to a cloud-hosted off-site backup. Big Data Storage Concerns.
We continue to gather high-quality data to help tackle some of the most pressing business challenges across a range of domains like finance, law, cybersecurity, and sustainability. Our work in this area includes FairIJ , which identifies biased data points in data used to tune a model, so that they can be edited out.
Imperva Cloud WAF protects hundreds of thousands of websites against cyber threats and blocks billions of security events every day. Counters and insights based on security events are calculated daily and used by users from multiple departments. The data is stored in a datalake and retrieved by SQL using Amazon Athena.
With the recently launched Amazon Monitron Kinesis data export v2 feature , your OT team can stream incoming measurement data and inference results from Amazon Monitron via Amazon Kinesis to AWS Simple Storage Service (Amazon S3) to build an Internet of Things (IoT) datalake. Choose Create delivery stream.
Flow-Based Programming : NiFi employs a flow-based programming model, allowing users to create complex data flows using simple drag-and-drop operations. This visual representation simplifies the design and management of data pipelines. Guaranteed Delivery : NiFi ensures that data delivered reliably, even in the event of failures.
Data Pipeline Architecture — Stop Building Monoliths Elliott Cordo | Founder, Architect, Builder | Datafutures Although common, data monoliths present several challenges, especially for larger teams and organizations that allow for federated data product development. Interested in attending an ODSC event?
This is a pretty important job as once the data has been integrated, it can be used for a variety of purposes, such as: Reporting and analytics Business intelligence Machine learning Data mining All of this provides stakeholders and even their own teams with the data they need when they need it.
Buy Your Data Warehouse (5 Key Factors) Nishith Agarwal, the Head of Data and ML Platforms at Lyra Health and the creator of Apache Hudi, draws on his experiences at both Uber and Lyra Health to present five considerations that impact the decision to build or buy the data warehouse, datalake, and data lakehouse layers of a data stack.
Expo Hall ODSC events are more than just data science training and networking events. Thank you to everyone who attended for making this event possible, and showing once again why we do what we do — connecting the greater data science community together to push the industry forward. What’s next?
Enterprise data architects, data engineers, and business leaders from around the globe gathered in New York last week for the 3-day Strata Data Conference , which featured new technologies, innovations, and many collaborative ideas. 2) When data becomes information, many (incremental) use cases surface.
How do you provide access and connect the right people to the right data? AWS has created a way to manage policies and access, but this is only for datalake formation. What about other data sources? In summary, AWS powers next-generation analytics with the best of both datalakes and purpose-built data stores.
Set up regular game days to test workload and team responses to simulated events. Learn from all operational failures – Drive improvement through lessons learned from all operational events and failures. By centralizing datasets within the flywheel’s dedicated Amazon S3 datalake, you ensure efficient data management.
Recognizing these specific needs, Fivetran has developed a range of connectors, including dedicated applications, databases, files, and events, which can accommodate the diverse formats used by healthcare systems. Addressing these needs may pose challenges that lead to the implementation of custom solutions rather than a uniform approach.
Data Engineer Data engineers are responsible for the end-to-end process of collecting, storing, and processing data. They use their knowledge of data warehousing, datalakes, and big data technologies to build and maintain data pipelines. Interested in attending an ODSC event?
Despite the benefits of this architecture, Rocket faced challenges that limited its effectiveness: Accessibility limitations: The datalake was stored in HDFS and only accessible from the Hadoop environment, hindering integration with other data sources. This also led to a backlog of data that needed to be ingested.
Data Governance Account This account hosts data governance services for datalake, central feature store, and fine-grained data access. The lead data scientist approves the model locally in the ML Dev Account. Follow the sample code to run an ML experiment pipeline using data stored in an S3 bucket.
Examples include seasonality, marketing promotions, pricing, and in-stock availability for retail sales, or temperature, length of daylight, or special events for utility demand. Local, regional, and world factors such as commodity prices, financial markets, and events such as COVID-19 can also change demand trajectory.
The triggers need to be scheduled to write the data to S3 at a period frequency based on the business need for training the models. Prior joining AWS, as a Data/Solution Architect he implemented many projects in Big Data domain, including several datalakes in Hadoop ecosystem.
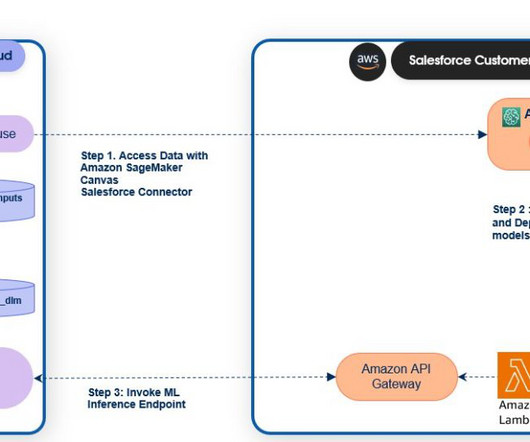
For Data Source , choose Salesforce Data Cloud and Add Connection to import the datalake object. If you’ve previously configured a connection to Salesforce Data Cloud, you will see an option to use that connection instead of creating a new one. Salesforce adds a “__c “ to all the Data Cloud object fields.
This is usually text, but it can also be code, IT events, time series, geospatial data, or even molecules. Starting from this foundation model, you can start solving automation problems easily with AI and using very little data—in some cases, called few-shot learning, just a few examples.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content