This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the Data Science Blogathon. Introduction A datalake is a centralized repository for storing, processing, and securing massive amounts of structured, semi-structured, and unstructured data. It can store data in its native format and process any type of data, regardless of size.
This article was published as a part of the Data Science Blogathon. Introduction Today, DataLake is most commonly used to describe an ecosystem of IT tools and processes (infrastructure as a service, software as a service, etc.) that work together to make processing and storing large volumes of data easy.
High quality, reliable data forms the backbone for all successful data endeavors, from reporting and analytics to machinelearning. Delta Lake is an open-source storage layer that solves many concerns around data. The post How to make datalakes reliable appeared first on Dataconomy.
This article was published as a part of the Data Science Blogathon. Introduction A datalake is a central data repository that allows us to store all of our structured and unstructured data on a large scale. The post A Detailed Introduction on DataLakes and Delta Lakes appeared first on Analytics Vidhya.
When it comes to data, there are two main types: datalakes and data warehouses. What is a datalake? An enormous amount of raw data is stored in its original format in a datalake until it is required for analytics applications. Which one is right for your business?
Be sure to check out his talk, “ Apache Kafka for Real-Time MachineLearning Without a DataLake ,” there! The combination of data streaming and machinelearning (ML) enables you to build one scalable, reliable, but also simple infrastructure for all machinelearning tasks using the Apache Kafka ecosystem.
Image Source: GitHub Table of Contents What is Data Engineering? Components of Data Engineering Object Storage Object Storage MinIO Install Object Storage MinIO DataLake with Buckets Demo DataLake Management Conclusion References What is Data Engineering?
Introduction A datalake is a centralized and scalable repository storing structured and unstructured data. The need for a datalake arises from the growing volume, variety, and velocity of data companies need to manage and analyze.
Datalakes and data warehouses are probably the two most widely used structures for storing data. Data Warehouses and DataLakes in a Nutshell. A data warehouse is used as a central storage space for large amounts of structured data coming from various sources. Data Type and Processing.
This post is part of an ongoing series about governing the machinelearning (ML) lifecycle at scale. This post dives deep into how to set up data governance at scale using Amazon DataZone for the data mesh. Data governance account – This account hosts the central data governance services provided by Amazon DataZone.
We have solicited insights from experts at industry-leading companies, asking: "What were the main AI, Data Science, MachineLearning Developments in 2021 and what key trends do you expect in 2022?" Read their opinions here.
The following points illustrates some of the main reasons why data versioning is crucial to the success of any data science and machinelearning project: Storage space One of the reasons of versioning data is to be able to keep track of multiple versions of the same data which obviously need to be stored as well.
Starburst, the datalake analytics platform, today extended their support for the most widely used multi-purpose, high-level programming language, Python with PyStarburst, as well as announced a new integration with the open source Python library, Ibis, built in collaboration with composable data systems builder and Ibis maintainer, Voltron Data. (..)
A datalake becomes a data swamp in the absence of comprehensive data quality validation and does not offer a clear link to value creation. Organizations are rapidly adopting the cloud datalake as the datalake of choice, and the need for validating data in real time has become critical.
Machinelearning is rewriting the rules of the gaming industry. One report showed that Caesars is investing $1 billion in big data. I still remember playing my favorite games growing up, before machinelearning was a thing or big data was a household word. Other companies are following suit.
Amazon DataZone is a data management service that makes it quick and convenient to catalog, discover, share, and govern data stored in AWS, on-premises, and third-party sources. The datalake environment is required to configure an AWS Glue database table, which is used to publish an asset in the Amazon DataZone catalog.
Unified data storage : Fabric’s centralized datalake, Microsoft OneLake, eliminates data silos and provides a unified storage system, simplifying data access and retrieval. OneLake is designed to store a single copy of data in a unified location, leveraging the open-source Apache Parquet format.
Data is the foundation for machinelearning (ML) algorithms. One of the most common formats for storing large amounts of data is Apache Parquet due to its compact and highly efficient format. Athena allows applications to use standard SQL to query massive amounts of data on an S3 datalake.
Additionally, consider exploring other AWS services and tools that can complement and enhance your AI-driven applications, such as Amazon SageMaker for machinelearning model training and deployment, or Amazon Lex for building conversational interfaces. He is passionate about cloud and machinelearning.
Enterprises migrating on-prem data environments to the cloud in pursuit of more robust, flexible, and integrated analytics and AI/ML capabilities are fueling a surge in cloud datalake implementations. The post How to Ensure Your New Cloud DataLake Is Secure appeared first on DATAVERSITY.
It integrates well with other Google Cloud services and supports advanced analytics and machinelearning features. It provides a scalable and fault-tolerant ecosystem for big data processing. Spark offers a rich set of libraries for data processing, machinelearning, graph processing, and stream processing.
To make your data management processes easier, here’s a primer on datalakes, and our picks for a few datalake vendors worth considering. What is a datalake? First, a datalake is a centralized repository that allows users or an organization to store and analyze large volumes of data.
We often hear that organizations have invested in data science capabilities but are struggling to operationalize their machinelearning models. Domain experts, for example, feel they are still overly reliant on core IT to access the data assets they need to make effective business decisions.
After completion of the program, Precise achieved Advanced tier partner status and was selected by a federal government agency to create a machinelearning as a service (MLaaS) platform on AWS. This customer wanted to use machinelearning as a tool to digitize images and recognize handwriting.
With the amount of data companies are using growing to unprecedented levels, organizations are grappling with the challenge of efficiently managing and deriving insights from these vast volumes of structured and unstructured data. What is a DataLake? Consistency of data throughout the datalake.
Discover the nuanced dissimilarities between DataLakes and Data Warehouses. Data management in the digital age has become a crucial aspect of businesses, and two prominent concepts in this realm are DataLakes and Data Warehouses. It acts as a repository for storing all the data.
Amazon AppFlow was used to facilitate the smooth and secure transfer of data from various sources into ODAP. Additionally, Amazon Simple Storage Service (Amazon S3) served as the central datalake, providing a scalable and cost-effective storage solution for the diverse data types collected from different systems.
When it was no longer a hard requirement that a physical data model be created upon the ingestion of data, there was a resulting drop in richness of the description and consistency of the data stored in Hadoop. You did not have to understand or prepare the data to get it into Hadoop, so people rarely did.
As one of the largest AWS customers, Twilio engages with data, artificial intelligence (AI), and machinelearning (ML) services to run their daily workloads. Data is the foundational layer for all generative AI and ML applications. The following diagram illustrates the solution architecture.
Real-Time ML with Spark and SBERT, AI Coding Assistants, DataLake Vendors, and ODSC East Highlights Getting Up to Speed on Real-Time MachineLearning with Spark and SBERT Learn more about real-time machinelearning by using this approach that uses Apache Spark and SBERT.
Azure Synapse Analytics This is the future of data warehousing. It combines data warehousing and datalakes into a simple query interface for a simple and fast analytics service. Call for Research Proposals Amazon is seeking proposals impact research in the Artificial Intelligence and MachineLearning areas.
Enterprises often rely on data warehouses and datalakes to handle big data for various purposes, from business intelligence to data science. A new approach, called a data lakehouse, aims to … But these architectures have limitations and tradeoffs that make them less than ideal for modern teams.
MPII is using a machinelearning (ML) bid optimization engine to inform upstream decision-making processes in power asset management and trading. This solution helps market analysts design and perform data-driven bidding strategies optimized for power asset profitability.
Customers of every size and industry are innovating on AWS by infusing machinelearning (ML) into their products and services. However, implementing security, data privacy, and governance controls are still key challenges faced by customers when implementing ML workloads at scale.
Traditional relational databases provide certain benefits, but they are not suitable to handle big and various data. That is when datalake products started gaining popularity, and since then, more companies introduced lake solutions as part of their data infrastructure. How to improve indexing.
DatasaurAI-Powered DataLabeling Datasaur focuses on improving AI development with its open-source data labeling solutions. Designed for NLP and machinelearning applications, Datasaurs tools enable teams to streamline data annotation workflows.
The Future of the Single Source of Truth is an Open DataLake Organizations that strive for high-performance data systems are increasingly turning towards the ELT (Extract, Load, Transform) model using an open datalake. Register by Friday for 50% off! See them here!
Azure Synapse Analytics can be seen as a merge of Azure SQL Data Warehouse and Azure DataLake. Synapse allows one to use SQL to query petabytes of data, both relational and non-relational, with amazing speed. R Support for Azure MachineLearning. Azure Synapse. It’s true, I saw it happen this week.
He specializes in large language models, cloud infrastructure, and scalable data systems, focusing on building intelligent solutions that enhance automation and data accessibility across Amazons operations. He specializes in building scalable machinelearning infrastructure, distributed systems, and containerization technologies.
With machinelearning (ML) and artificial intelligence (AI) applications becoming more business-critical, organizations are in the race to advance their AI/ML capabilities. To realize the full potential of AI/ML, having the right underlying machinelearning platform is a prerequisite.
Data storage and processing The storage and processing of big data require specific architectures tailored to handle large volumes and various types of data efficiently. DatalakesDatalakes provide a centralized repository for storing raw data in its original format, making it easy to analyze different data types as needed.
Cloud-Based IoT Platforms Cloud-based IoT platforms offer scalable storage and computing resources for handling the massive influx of IoT data. These platforms provide data engineers with the flexibility to develop and deploy IoT applications efficiently.
Machinelearning (ML)—the artificial intelligence (AI) subfield in which machineslearn from datasets and past experiences by recognizing patterns and generating predictions—is a $21 billion global industry projected to become a $209 billion industry by 2029.
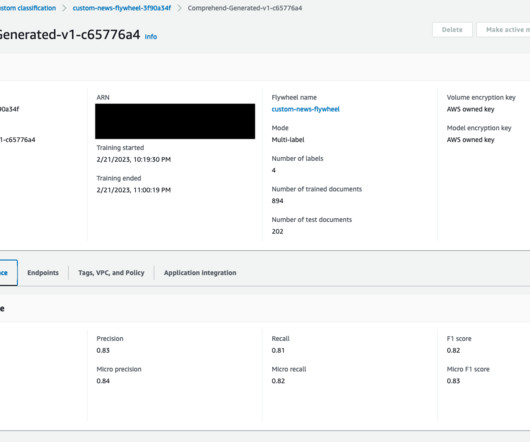
This combination of great models and continuous adaptation is what will lead to a successful machinelearning (ML) strategy. Today, we are excited to announce the launch of Amazon Comprehend flywheel—a one-stop machinelearning operations (MLOps) feature for an Amazon Comprehend model.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content