This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
As one of the largest AWS customers, Twilio engages with data, artificial intelligence (AI), and machine learning (ML) services to run their daily workloads. Data is the foundational layer for all generative AI and ML applications.
Many of these applications are complex to build because they require collaboration across teams and the integration of data, tools, and services. Data engineers use data warehouses, datalakes, and analytics tools to load, transform, clean, and aggregate data.
Structured Query Language (SQL) is a complex language that requires an understanding of databases and metadata. Today, generative AI can enable people without SQL knowledge. This generative AI task is called text-to-SQL, which generates SQL queries from natural language processing (NLP) and converts text into semantically correct SQL.
NOTE : Since we used an SQL query engine to query the dataset for this demonstration, the prompts and generated outputs mention SQL below. The question in the preceding example doesn’t require a lot of complex analysis on the data returned from the ETF dataset. A user can ask a business- or industry-related question for ETFs.
Amazon Redshift is the most popular cloud data warehouse that is used by tens of thousands of customers to analyze exabytes of data every day. SageMaker Studio is the first fully integrated development environment (IDE) for ML. You can use query_string to filter your dataset by SQL and unload it to Amazon S3.
Companies are faced with the daunting task of ingesting all this data, cleansing it, and using it to provide outstanding customer experience. Typically, companies ingest data from multiple sources into their datalake to derive valuable insights from the data. Run the AWS Glue ML transform job.
Customers use Amazon Redshift as a key component of their data architecture to drive use cases from typical dashboarding to self-service analytics, real-time analytics, machine learning (ML), data sharing and monetization, and more. Discover how you can use Amazon Redshift to build a data mesh architecture to analyze your data.
One such area that is evolving is using natural language processing (NLP) to unlock new opportunities for accessing data through intuitive SQL queries. Instead of dealing with complex technical code, business users and data analysts can ask questions related to data and insights in plain language.
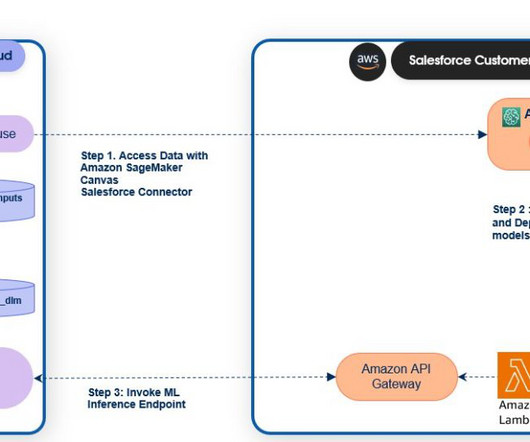
SageMaker endpoints can be registered to the Salesforce Data Cloud to activate predictions in Salesforce. SageMaker Canvas provides a no-code experience to access data from Salesforce Data Cloud and build, test, and deploy models using just a few clicks. Manage Data Cloud profile data ( Data Cloud_profile_api ).
Amazon AppFlow was used to facilitate the smooth and secure transfer of data from various sources into ODAP. Additionally, Amazon Simple Storage Service (Amazon S3) served as the central datalake, providing a scalable and cost-effective storage solution for the diverse data types collected from different systems.
Data exploration and model development were conducted using well-known machine learning (ML) tools such as Jupyter or Apache Zeppelin notebooks. Apache Hive was used to provide a tabular interface to data stored in HDFS, and to integrate with Apache Spark SQL. This also led to a backlog of data that needed to be ingested.
It combines data warehousing and datalakes into a simple query interface for a simple and fast analytics service. SQL Server 2019 SQL Server 2019 went Generally Available. Amazon Web Services.
In this post, we discuss a Q&A bot use case that Q4 has implemented, the challenges that numerical and structured datasets presented, and how Q4 concluded that using SQL may be a viable solution. RAG with semantic search – Conventional RAG with semantic search was the last step before moving to SQL generation.
Solution overview Amazon SageMaker is a fully managed service that helps developers and data scientists build, train, and deploy machine learning (ML) models. Data preparation SageMaker Ground Truth employs a human workforce made up of Northpower volunteers to annotate a set of 10,000 images.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
Data is the foundation for machine learning (ML) algorithms. One of the most common formats for storing large amounts of data is Apache Parquet due to its compact and highly efficient format. Athena allows applications to use standard SQL to query massive amounts of data on an S3 datalake.
Azure Machine Learning is Microsoft’s enterprise-grade service that provides a comprehensive environment for data scientists and ML engineers to build, train, deploy, and manage machine learning models at scale. You can explore its capabilities through the official Azure ML Studio documentation. Awesome, right?
If you are a returning user to SageMaker Studio, in order to ensure Salesforce Data Cloud is enabled, upgrade to the latest Jupyter and SageMaker Data Wrangler kernels. This completes the setup to enable data access from Salesforce Data Cloud to SageMaker Studio to build AI and machine learning (ML) models.
Snowpark is the set of libraries and runtimes in Snowflake that securely deploy and process non-SQL code, including Python , Java, and Scala. As a declarative language, SQL is very powerful in allowing users from all backgrounds to ask questions about data. Why Does Snowpark Matter? Who Should use Snowpark?
DVC Released in 2017, Data Version Control ( DVC for short) is an open-source tool created by iterative. DVC can be used for versioning data and models, to track experiments and compare any data, code, parameters models and graphical plots of performance. DVC can efficiently handle large files and machine learning models.
Alignment to other tools in the organization’s tech stack Consider how well the MLOps tool integrates with your existing tools and workflows, such as data sources, data engineering platforms, code repositories, CI/CD pipelines, monitoring systems, etc. and Pandas or Apache Spark DataFrames.
By running reports on historical data, a data warehouse can clarify what systems and processes are working and what methods need improvement. Data warehouse is the base architecture for artificial intelligence and machine learning (AI/ML) solutions as well.
Amazon SageMaker Data Wrangler reduces the time it takes to collect and prepare data for machine learning (ML) from weeks to minutes. Data is frequently kept in datalakes that can be managed by AWS Lake Formation , giving you the ability to implement fine-grained access control using a straightforward grant or revoke procedure.
Its goal is to help with a quick analysis of target characteristics, training vs testing data, and other such data characterization tasks. Apache Superset GitHub | Website Apache Superset is a must-try project for any ML engineer, data scientist, or data analyst.
Just as a writer needs to know core skills like sentence structure, grammar, and so on, data scientists at all levels should know core data science skills like programming, computer science, algorithms, and so on. While knowing Python, R, and SQL are expected, you’ll need to go beyond that.
The natural language capabilities allow non-technical users to query data through conversational English rather than complex SQL. The AI and language models must identify the appropriate data sources, generate effective SQL queries, and produce coherent responses with embedded results at scale.
These tools may have their own versioning system, which can be difficult to integrate with a broader data version control system. For instance, our datalake could contain a variety of relational and non-relational databases, files in different formats, and data stored using different cloud providers. DVC Git LFS neptune.ai
Using Azure ML to Train a Serengeti Data Model, Fast Option Pricing with DL, and How To Connect a GPU to a Container Using Azure ML to Train a Serengeti Data Model for Animal Identification In this article, we will cover how you can train a model using Notebooks in Azure Machine Learning Studio.
blog series, we experiment with the most interesting blends of data and tools. Whether it’s mixing traditional sources with modern datalakes, open-source DevOps on the cloud with protected internal legacy tools, SQL with NoSQL, web-wisdom-of-the-crowd with in-house handwritten notes, or IoT […].
Amazon Monitron is an end-to-end condition monitoring solution that enables you to start monitoring equipment health with the aid of machine learning (ML) in minutes, so you can implement predictive maintenance and reduce unplanned downtime. For the detailed Amazon Monitron installation guide, refer to Getting started with Amazon Monitron.
MPII is using a machine learning (ML) bid optimization engine to inform upstream decision-making processes in power asset management and trading. This solution helps market analysts design and perform data-driven bidding strategies optimized for power asset profitability. Data comes from disparate sources in a number of formats.
How you now anonymize Data more easily Photo by Dušan veverkolog on Unsplash Google has just announced the public preview of BigQuery differential privacy with SQL building blocks. You can use these functions to anonymize their data. Hence, with this feature you can also ensure that data is shared there securely.
Powered by machine learning (ML), Einstein Discovery provides predictions and recommendations within Tableau workflows for accelerated and smarter decision-making. Here’s how: Einstein dashboard extension : Enjoy on-demand, interpretable ML predictions from Einstein Discovery natively integrated in Tableau dashboards.
By leveraging data services and APIs, a data fabric can also pull together data from legacy systems, datalakes, data warehouses and SQL databases, providing a holistic view into business performance. Then, it applies these insights to automate and orchestrate the data lifecycle.
In addition, the generative business intelligence (BI) capabilities of QuickSight allow you to ask questions about customer feedback using natural language, without the need to write SQL queries or learn a BI tool. For more information, see Customize models in Amazon Bedrock with your own data using fine-tuning and continued pre-training.
In another decade, the internet and mobile started the generate data of unforeseen volume, variety and velocity. It required a different data platform solution. Hence, DataLake emerged, which handles unstructured and structured data with huge volume. All phases of the data-information lifecycle.
From gathering and processing data to building models through experiments, deploying the best ones, and managing them at scale for continuous value in production—it’s a lot. As the number of ML-powered apps and services grows, it gets overwhelming for data scientists and ML engineers to build and deploy models at scale.
Start Learning AI With the ODSC West Data Primer Series In this six-part series as part of the ODSC West mini-bootcamp, you’ll learn everything you need to know to get started with AI, including SQL, machine learning, and even LLMs. But it doesn’t stop there.
Data analysts often must go out and find their data, process it, clean it, and get it ready for analysis. This pushes into Big Data as well, as many companies now have significant amounts of data and large datalakes that need analyzing. Cloud Services: Google Cloud Platform, AWS, Azure.
Having a solid understanding of ML principles and practical knowledge of statistics, algorithms, and mathematics. Data Warehousing concepts and knowledge should be strong. Having experience using at least one end-to-end Azure datalake project. Hands-on experience working with SQLDW and SQL-DB. What is Polybase?
is our enterprise-ready next-generation studio for AI builders, bringing together traditional machine learning (ML) and new generative AI capabilities powered by foundation models. IBM watsonx.ai With watsonx.ai, businesses can effectively train, validate, tune and deploy AI models with confidence and at scale across their enterprise.
To cluster the data we have to calculate distances between IPs — The number of all possible IP pairs is very large, and we had to solve the scale problem. Data Processing and Clustering Our data is stored in a DataLake and we used PrestoDB as a query engine. AS ip_1, r.ip AND l.ip < r.ip
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content