This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Helping government agencies adopt AI and ML technologies Precise works closely with AWS to offer end-to-end cloud services such as enterprise cloud strategy, infrastructure design, cloud-native application development, modern data warehouses and datalakes, AI and ML, cloud migration, and operational support.
Cloud-Based IoT Platforms Cloud-based IoT platforms offer scalable storage and computing resources for handling the massive influx of IoT data. These platforms provide data engineers with the flexibility to develop and deploy IoT applications efficiently.
The Future of the Single Source of Truth is an Open DataLake Organizations that strive for high-performance data systems are increasingly turning towards the ELT (Extract, Load, Transform) model using an open datalake.
Google AutoML for NaturalLanguage goes GA Extracting meaning from text is still a challenging and important task faced by many organizations. Google AutoML for NLP (NaturalLanguageProcessing) provides sentiment analysis, classification, and entity extraction from text. It now also supports PDF documents.
The rise of large language models (LLMs) and foundation models (FMs) has revolutionized the field of naturallanguageprocessing (NLP) and artificial intelligence (AI). These powerful models, trained on vast amounts of data, can generate human-like text, answer questions, and even engage in creative writing tasks.
Prior joining AWS, as a Data/Solution Architect he implemented many projects in Big Data domain, including several datalakes in Hadoop ecosystem. As a Data Engineer he was involved in applying AI/ML to fraud detection and office automation. They are available in a variety of sizes and configurations.
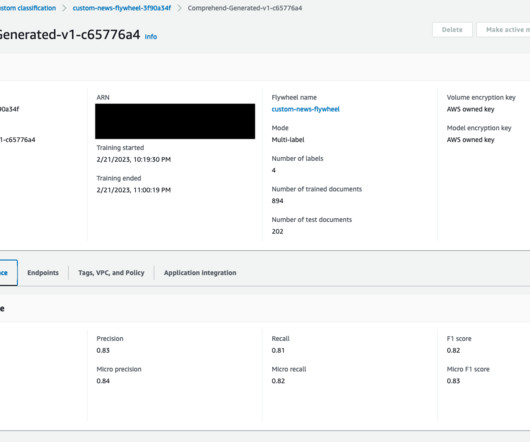
Solution overview Amazon Comprehend is a fully managed service that uses naturallanguageprocessing (NLP) to extract insights about the content of documents. This feature also allows you to automate model retraining after new datasets are ingested and available in the flywheel´s datalake.
He specializes in large language models, cloud infrastructure, and scalable data systems, focusing on building intelligent solutions that enhance automation and data accessibility across Amazons operations.
Amazon Comprehend is a managed AI service that uses naturallanguageprocessing (NLP) with ready-made intelligence to extract insights about the content of documents. It develops insights by recognizing the entities, key phrases, language, sentiments, and other common elements in a document.
Text analytics: Text analytics, also known as text mining, deals with unstructured text data, such as customer reviews, social media comments, or documents. It uses naturallanguageprocessing (NLP) techniques to extract valuable insights from textual data. Ensure that data is clean, consistent, and up-to-date.
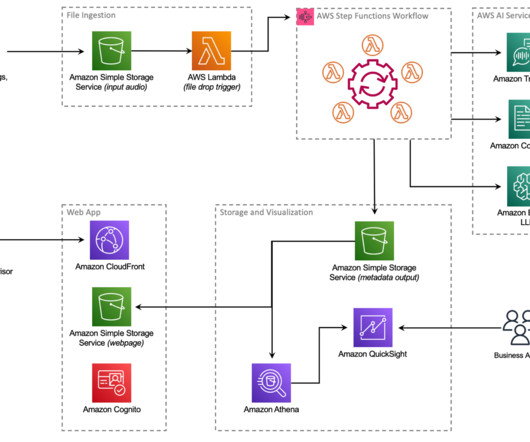
The following is a high-level architecture of the solution we can build to process the unstructured data, assuming the input data is being ingested to the raw input object store. The steps of the workflow are as follows: Integrated AI services extract data from the unstructured data.
eSentire has over 2 TB of signal data stored in their Amazon Simple Storage Service (Amazon S3) datalake. This further step updates the FM by training with data labeled by security experts (such as Q&A pairs and investigation conclusions).
Businesses can use LLMs to gain valuable insights, streamline processes, and deliver enhanced customer experiences. In the first step, an AWS Lambda function reads and validates the file, and extracts the raw data. The Step Functions workflow starts.
ML operationalization summary As defined in the post MLOps foundation roadmap for enterprises with Amazon SageMaker , ML and operations (MLOps) is the combination of people, processes, and technology to productionize machine learning (ML) solutions efficiently. The following figure illustrates the key steps.
One such area that is evolving is using naturallanguageprocessing (NLP) to unlock new opportunities for accessing data through intuitive SQL queries. Instead of dealing with complex technical code, business users and data analysts can ask questions related to data and insights in plain language.
Furthermore, the data that the model was trained on might be out of date, which leads to providing inaccurate responses. RAG is an advanced naturallanguageprocessing technique that combines knowledge retrieval with generative text models.
As organisations grapple with this vast amount of information, understanding the main components of Big Data becomes essential for leveraging its potential effectively. Key Takeaways Big Data originates from diverse sources, including IoT and social media. Datalakes and cloud storage provide scalable solutions for large datasets.
As organisations grapple with this vast amount of information, understanding the main components of Big Data becomes essential for leveraging its potential effectively. Key Takeaways Big Data originates from diverse sources, including IoT and social media. Datalakes and cloud storage provide scalable solutions for large datasets.
Hear expert insights and technical experiences during IBM watsonx Day Solving the risks of massive datasets and re-establishing trust for generative AI Some foundation models for naturallanguageprocessing (NLP), for instance, are pre-trained on massive amounts of data from the internet.
A foundation model is built on a neural network model architecture to process information much like the human brain does. studio a suite of language and code foundation models , each with a geology-themed code name, that can be customized for a range of enterprise tasks. All watsonx.ai
Wednesday, June 14th Me, my health, and AI: applications in medical diagnostics and prognostics: Sara Khalid | Associate Professor, Senior Research Fellow, Biomedical Data Science and Health Informatics | University of Oxford Iterated and Exponentially Weighted Moving Principal Component Analysis : Dr. Paul A.
Data Engineer Data engineers are responsible for the end-to-end process of collecting, storing, and processingdata. They use their knowledge of data warehousing, datalakes, and big data technologies to build and maintain data pipelines.
Get Started with NLP With Our New Introduction to NLP Course Gain the skills needed to start a successful career in naturallanguageprocessing with our new introduction to NLP course! In addition, we’ll discuss a variety of tools that form the modern LLM application development stack.
Foundation models: The power of curated datasets Foundation models , also known as “transformers,” are modern, large-scale AI models trained on large amounts of raw, unlabeled data. Open-source projects, academic institutions, startups and legacy tech companies all contributed to the development of foundation models.
As a first step, they wanted to transcribe voice calls and analyze those interactions to determine primary call drivers, including issues, topics, sentiment, average handle time (AHT) breakdowns, and develop additional naturallanguageprocessing (NLP)-based analytics.
This allows users to accomplish different NaturalLanguageProcessing (NLP) functional tasks and take advantage of IBM vetted pre-trained open-source foundation models. Encoder-decoder and decoder-only large language models are available in the Prompt Lab today. To bridge the tuning gap, watsonx.ai
Social media conversations, comments, customer reviews, and image data are unstructured in nature and hold valuable insights, many of which are still being uncovered through advanced techniques like NaturalLanguageProcessing (NLP) and machine learning. Tools like Unstructured.io
Structured Query Language (SQL) is a complex language that requires an understanding of databases and metadata. This generative AI task is called text-to-SQL, which generates SQL queries from naturallanguageprocessing (NLP) and converts text into semantically correct SQL.
An IDP pipeline usually combines optical character recognition (OCR) and naturallanguageprocessing (NLP) to read and understand a document and extract specific terms or words. By centralizing datasets within the flywheel’s dedicated Amazon S3 datalake, you ensure efficient data management.
To combine the collected data, you can integrate different data producers into a datalake as a repository. A central repository for unstructured data is beneficial for tasks like analytics and data virtualization. Data Cleaning The next step is to clean the data after ingesting it into the datalake.
Data Morph: A Cautionary Tale of Summary Statistics Visualization in Bayesian Workflow Using Python or R Harnessing Bayesian Statistics for Business-Centric Data Science Data Engineering and Big Data Join this track to learn the latest techniques and processes to analyze raw data and automate data into mechanical processes and algorithms.
The combination of large language models (LLMs), including the ease of integration that Amazon Bedrock offers, and a scalable, domain-oriented data infrastructure positions this as an intelligent method of tapping into the abundant information held in various analytics databases and datalakes.
Learn more The Best Tools, Libraries, Frameworks and Methodologies that ML Teams Actually Use – Things We Learned from 41 ML Startups [ROUNDUP] Key use cases and/or user journeys Identify the main business problems and the data scientist’s needs that you want to solve with ML, and choose a tool that can handle them effectively.
The dataset Our structured dataset can reside in a SQL database, datalake, or data warehouse as long as we have support for SQL. She leads machine learning (ML) projects in various domains such as computer vision, naturallanguageprocessing and generative AI.
For example, data catalogs have evolved to deliver governance capabilities like managing data quality and data privacy and compliance. It uses metadata and data management tools to organize all data assets within your organization.
Mai-Lan Tomsen Bukovec, Vice President, Technology | AIM250-INT | Putting your data to work with generative AI Thursday November 30 | 12:30 PM – 1:30 PM (PST) | Venetian | Level 5 | Palazzo Ballroom B How can you turn your datalake into a business advantage with generative AI?
Cloudera Cloudera is a cloud-based platform that provides businesses with the tools they need to manage and analyze data. They offer a variety of services, including data warehousing, datalakes, and machine learning. It is used by a variety of companies, including Netflix, Uber, and Spotify.
Only once you form a clear definition and understanding of the business problem , goals, and the necessity of machine learning should you move forward to the next stage of data preparation. In large ML organizations, there is typically a dedicated team for all the above aspects of data preparation. link] | [link] | [link]
From business processes and smart home technology to healthcare and life sciences, AI continues to evolve and grow as it plays an increasing role in many aspects of our work, home lives, and beyond. The post 2021 Crystal Ball: What’s in Store for AI, Machine Learning, and Data appeared first on DATAVERSITY.
Voice-based queries use NaturalLanguageProcessing (NLP) and sentiment analysis for speech recognition. Customer service use cases Not only can ML understand what customers are saying, but it also understands their tone and can direct them to appropriate customer service agents for customer support.
The amount of data generated in the digital world is increasing by the minute! This massive amount of data is termed “big data.” We may classify the data as structured, unstructured, or semi-structured. Data that is structured or semi-structured is relatively easy to store, process, and analyze. […].
The process is also known as image captioning , and operates at the intersection of computer vision and naturallanguageprocessing (NLP). Marketing firms store vast amounts of digital data that needs to be centralized, easily searchable, and scalable enabled by data catalogs.
Storage Solutions: Secure and scalable storage options like Azure Blob Storage and Azure DataLake Storage. Key features and benefits of Azure for Data Science include: Scalability: Easily scale resources up or down based on demand, ideal for handling large datasets and complex computations.
Also consider using Amazon Security Lake to automatically centralize security data from AWS environments, SaaS providers, on premises, and cloud sources into a purpose-built datalake stored in your account. Emily Soward is a Data Scientist with AWS Professional Services.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content