This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Before seeing the practical implementation of the use case, let’s briefly introduce Azure DataLake Storage Gen2 and the Paramiko module. Introduction to Azure DataLake Storage Gen2 Azure DataLake Storage Gen2 is a data storage solution specially designed for big data […].
Image Source: GitHub Table of Contents What is Data Engineering? Components of Data Engineering Object Storage Object Storage MinIO Install Object Storage MinIO DataLake with Buckets Demo DataLake Management Conclusion References What is Data Engineering?
Starburst, the datalake analytics platform, today extended their support for the most widely used multi-purpose, high-level programming language, Python with PyStarburst, as well as announced a new integration with the open source Python library, Ibis, built in collaboration with composable data systems builder and Ibis maintainer, Voltron Data. (..)
7 Best Platforms to Practice SQL • Explainable AI: 10 Python Libraries for Demystifying Your Model's Decisions • ChatGPT: Everything You Need to Know • DataLakes and SQL: A Match Made in Data Heaven • Google Data Analytics Certification Review for 2023
Be sure to check out his talk, “ Apache Kafka for Real-Time Machine Learning Without a DataLake ,” there! The combination of data streaming and machine learning (ML) enables you to build one scalable, reliable, but also simple infrastructure for all machine learning tasks using the Apache Kafka ecosystem.
To make your data management processes easier, here’s a primer on datalakes, and our picks for a few datalake vendors worth considering. What is a datalake? First, a datalake is a centralized repository that allows users or an organization to store and analyze large volumes of data.
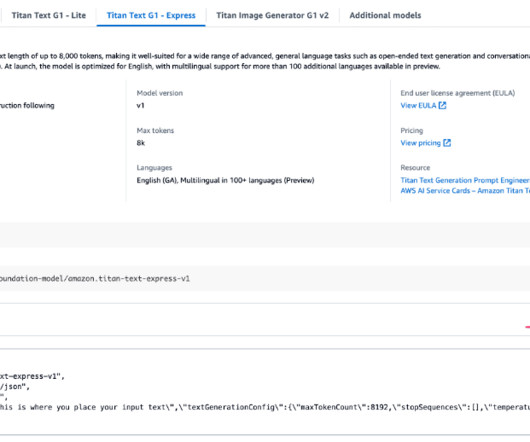
For this post, we run the code in a Jupyter notebook within VS Code and use Python. You can interact with Amazon Bedrock using AWS SDKs available in Python, Java, Node.js, and more. We walk through a Python example in this post. For this example, we use a Jupyter notebook (Kernel: Python 3.12.0).
Data management problems can also lead to data silos; disparate collections of databases that don’t communicate with each other, leading to flawed analysis based on incomplete or incorrect datasets. One way to address this is to implement a datalake: a large and complex database of diverse datasets all stored in their original format.
Apache Spark: Apache Spark is an open-source, unified analytics engine designed for big data processing. It provides high-speed, in-memory data processing capabilities and supports various programming languages like Scala, Java, Python, and R. It can handle both batch and real-time data processing tasks efficiently.
Real-Time ML with Spark and SBERT, AI Coding Assistants, DataLake Vendors, and ODSC East Highlights Getting Up to Speed on Real-Time Machine Learning with Spark and SBERT Learn more about real-time machine learning by using this approach that uses Apache Spark and SBERT. Well, these libraries will give you a solid start.
Many of these applications are complex to build because they require collaboration across teams and the integration of data, tools, and services. Data engineers use data warehouses, datalakes, and analytics tools to load, transform, clean, and aggregate data. Big Data Architect.
SageMaker Studio runs custom Python code to augment the training data and transform the metadata output from SageMaker Ground Truth into a format supported by the computer vision model training job. The model is then trained using a fully managed infrastructure, validated, and published to the Amazon SageMaker Model Registry.
When choosing a data structure, it may benefit you to see which has all the components of the CAP theorem and which best suits your needs. Drowning in Data? A DataLake May Be Your Lifesaver Read this Q&A with HPCC Systems on how datalakes let you spend less time managing data and more time analyzing it.
The Future of the Single Source of Truth is an Open DataLake Organizations that strive for high-performance data systems are increasingly turning towards the ELT (Extract, Load, Transform) model using an open datalake.
The solution harnesses the capabilities of generative AI, specifically Large Language Models (LLMs), to address the challenges posed by diverse sensor data and automatically generate Python functions based on various data formats. The solution only invokes the LLM for new device data file type (code has not yet been generated).
PlotlyInteractive Data Visualization Plotly is a leader in interactive data visualization tools, offering open-source graphing libraries in Python, R, JavaScript, and more. Their solutions, including Dash, make it easier for developers and data scientists to build analytical web applications with minimalcoding.
Although setting up a database to run your analyses may seem like an arduous task, modern open-source time series databases can provide significant benefits to any scientist running time series analysis on a large data set — and with much less effort than you might imagine.
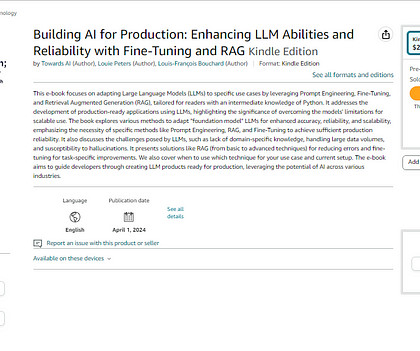
This e-book focuses on adapting large language models (LLMs) to specific use cases by leveraging Prompt Engineering, Fine-Tuning, and Retrieval Augmented Generation (RAG), tailored for readers with an intermediate knowledge of Python. He is looking for someone with project ideas and a basic understanding of AI and coding (preferably Python).
Snowpark is the set of libraries and runtimes in Snowflake that securely deploy and process non-SQL code, including Python , Java, and Scala. On the server side, runtimes include Python, Java, and Scala in the warehouse model or Snowpark Container Services (private preview).
Azure Synapse Analytics can be seen as a merge of Azure SQL Data Warehouse and Azure DataLake. Synapse allows one to use SQL to query petabytes of data, both relational and non-relational, with amazing speed. Python support has been available for a while. Azure Synapse. It’s true, I saw it happen this week.
These tools will help make your initial data exploration process easy. ydata-profiling GitHub | Website The primary goal of ydata-profiling is to provide a one-line Exploratory Data Analysis (EDA) experience in a consistent and fast solution. Output is a fully self-contained HTML application.
EL stands for extract and load, and its primary goal is to just move the data from one place to another where the destination is usually a Data Warehouse or a DataLake. The most fundamental difference between ELT and ETL is that the former first loads the data into the target storage and, then, processes them.
This doesn’t mean anything too complicated, but could range from basic Excel work to more advanced reporting to be used for data visualization later on. Computer Science and Computer Engineering Similar to knowing statistics and math, a data scientist should know the fundamentals of computer science as well.
Key Takeaways Big Data focuses on collecting, storing, and managing massive datasets. Data Science extracts insights and builds predictive models from processed data. Big Data technologies include Hadoop, Spark, and NoSQL databases. Data Science uses Python, R, and machine learning frameworks.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
By viewing data spatially, inferences can be made, and the imagination can be sparked. But in a world where so much data has a location, it’s essential to think spatially. From an ancient lake to a datalake: A paleo perspective. I’ve been getting my hands dirty with data for a long time now.
blog series, we experiment with the most interesting blends of data and tools. Whether it’s mixing traditional sources with modern datalakes, open-source devops on the cloud with protected internal legacy tools, SQL with noSQL, web-wisdom-of-the-crowd with in-house handwritten notes, or IoT […]. In the “Will They Blend?”
This setup uses the AWS SDK for Python (Boto3) to interact with AWS services. He specializes in large language models, cloud infrastructure, and scalable data systems, focusing on building intelligent solutions that enhance automation and data accessibility across Amazons operations.
This allows data to be read into DuckDB and moved between these systems in a convenient manner. In modern data analysis, data must often be combined from a wide variety of different sources. Data might sit in CSV files on your machine, in Parquet files in a datalake, or in an operational database.
He is focused on Big Data, DataLakes, Streaming and batch Analytics services and generative AI technologies. He is actively working on projects in the ML space and has presented at numerous conferences including Strata and GlueCon. Arghya Banerjee is a Sr.
Why: Data Makes It Different. If you peek under the hood of an ML-powered application, these days you will often find a repository of Python code. ML use cases rarely dictate the master data management solution, so the ML stack needs to integrate with existing data warehouses. However, not all Python code is equal.
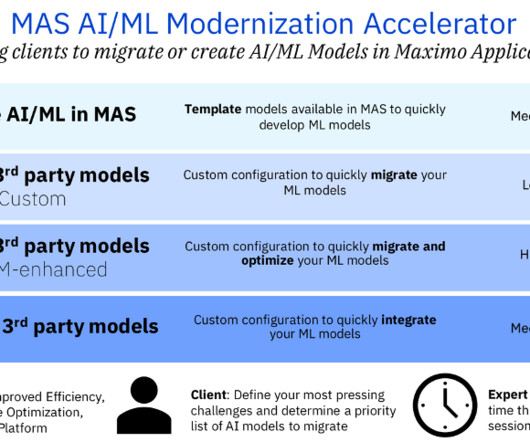
Solution 4: Integrate 3rd party models with MAS This data science solution predicts anomalies in air compressor assets using an external model. Through Watson Studio, we create a Python wrapper function to get results from the deployed models and integrate the model within Watson Machine Learning.
Amazon Redshift uses SQL to analyze structured and semi-structured data across data warehouses, operational databases, and datalakes, using AWS-designed hardware and ML to deliver the best price-performance at any scale. as the image and Glue Python [PySpark and Ray] as the kernel, then choose Select.
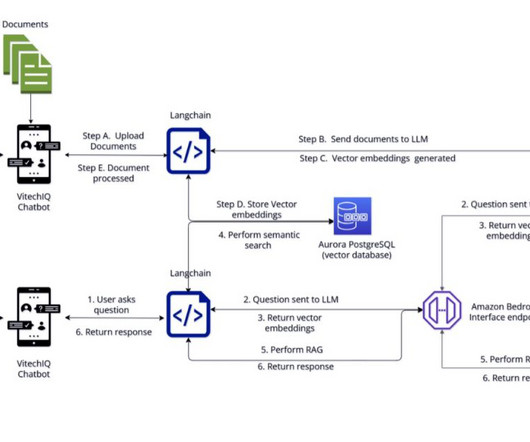
Vitech used Python virtual environments to freeze a stable version of the LangChain dependencies and seamlessly move it from development to production environments. Streamlit offers a user-friendly experience to quickly build interactive and easily deployable solutions using the Python library (used widely at Vitech). langsmith==0.0.43
Choosing a DataLake Format: What to Actually Look For The differences between many datalake products today might not matter as much as you think. When choosing a datalake, here’s something else to consider. When choosing a datalake, here’s something else to consider.
Our goal was to improve the user experience of an existing application used to explore the counters and insights data. The data is stored in a datalake and retrieved by SQL using Amazon Athena. You can experiment with and evaluate top FMs for your use case and customize them with your data.
Companies are faced with the daunting task of ingesting all this data, cleansing it, and using it to provide outstanding customer experience. Typically, companies ingest data from multiple sources into their datalake to derive valuable insights from the data. Jupyter notebooks are web-based interactive platforms.
These tools may have their own versioning system, which can be difficult to integrate with a broader data version control system. For instance, our datalake could contain a variety of relational and non-relational databases, files in different formats, and data stored using different cloud providers. DVC Git LFS neptune.ai
To get the data, you will need to follow the instructions in the article: Create a Data Solution on Azure Synapse Analytics with Snapshot Serengeti — Part 1 — Microsoft Community Hub, where you will load data into Azure DataLake via Azure Synapse. Lastly, upload the data from Azure Subscription.
As a first step, we’re carefully curating an enterprise-ready data set using our datalake tooling to serve as a foundation for our, well, foundation models. fit into a greater data and AI platform, watsonx, alongside two other key pillars watsonx.data and watsonx.governance.
For example, if your team is proficient in Python and R, you may want an MLOps tool that supports open data formats like Parquet, JSON, CSV, etc., LakeFS LakeFS is an open-source platform that provides datalake versioning and management capabilities. and programmatically via the Kolena Python client.
To pursue a data science career, you need a deep understanding and expansive knowledge of machine learning and AI. Your skill set should include the ability to write in the programming languages Python, SAS, R and Scala. And you should have experience working with big data platforms such as Hadoop or Apache Spark.
Third, despite the larger adoption of centralized analytics solutions like datalakes and warehouses, complexity rises with different table names and other metadata that is required to create the SQL for the desired sources. Set up the SDK for Python (Boto3). medium instance with the Python 3 (Data Science) kernel.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content