This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Big Data Analytics erreicht die nötige Reife Der Begriff Big Data war schon immer etwas schwammig und wurde von vielen Unternehmen und Experten schnell auch im Kontext kleinerer Datenmengen verwendet. 2 Denn heute spielt die Definition darüber, was Big Data eigentlich genau ist, wirklich keine Rolle mehr.
As a result, businesses have focused mainly on automating tasks with abundant data and high business value, leaving everything else on the table. models are trained on IBM’s curated, enterprise-focused datalake, on our custom-designed cloud-native AI supercomputer, Vela. But this is starting to change. All watsonx.ai
Foundation models can be trained to perform tasks such as data classification, the identification of objects within images (computer vision) and natural language processing (NLP) (understanding and generating text) with a high degree of accuracy. models are trained on IBM’s curated, enterprise-focused datalake.
With a foundation model, often using a kind of neural network called a “transformer” and leveraging a technique called self-supervisedlearning, you can create pre-trained models for a vast amount of unlabeled data. But that’s all changing thanks to pre-trained, open source foundation models.
Given the availability of diverse data sources at this juncture, employing the CNN-QR algorithm facilitated the integration of various features, operating within a supervisedlearning framework. Utilizing Forecast proved effective due to the simplicity of providing the requisite data and specifying the forecast duration.
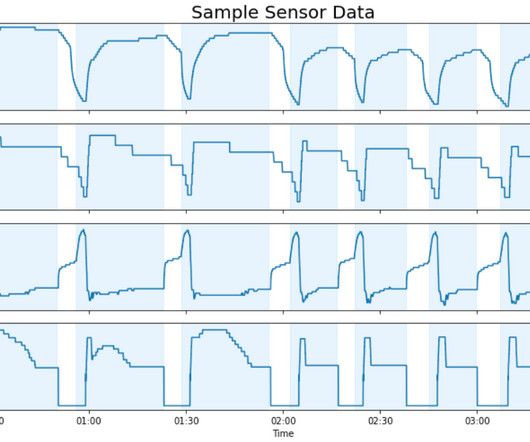
Conclusion In this post, we showed how our team used AWS Glue and SageMaker to create a scalable supervisedlearning solution for predictive maintenance. Our model is capable of capturing trends across long-term histories of sensor data and accurately detecting hundreds of equipment failures weeks in advance. The remaining 8.4%
These processes are essential in AI-based big data analytics and decision-making. DataLakesDatalakes are crucial in effectively handling unstructured data for AI applications. They serve as centralized repositories where raw data, whether structured or unstructured, can be stored in its native format.
DataLake vs. Data Warehouse Distinguishing between these two storage paradigms and understanding their use cases. Students should learn how datalake s can store raw data in its native format, while data warehouses are optimised for structured data.
Cloudera Cloudera is a cloud-based platform that provides businesses with the tools they need to manage and analyze data. They offer a variety of services, including data warehousing, datalakes, and machine learning.
To cluster the data we have to calculate distances between IPs — The number of all possible IP pairs is very large, and we had to solve the scale problem. Data Processing and Clustering Our data is stored in a DataLake and we used PrestoDB as a query engine.
For instance, something from a factory maybe some uses case where there’s a limited amount of data, then I think the current approach, and especially in the growing field of self-supervisedlearning, is very helpful here. You can actually improve embeddings and train embeddings in a self-supervised way.
Solution Datalakes and warehouses are the two key components of any data pipeline. The datalake is a platform where any kind or amount of data can be stored, processed, and analyzed. Data engineers are mostly in charge of it. You can read this article to learn how to choose a data labeling tool.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















Let's personalize your content