This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Summary: Associative classification in datamining combines association rule mining with classification for improved predictive accuracy. Despite computational challenges, its interpretability and efficiency make it a valuable technique in data-driven industries. Lets explore each in detail.
This data alone does not make any sense unless it’s identified to be related in some pattern. Datamining is the process of discovering these patterns among the data and is therefore also known as Knowledge Discovery from Data (KDD). Machine learning provides the technical basis for datamining.
Some of the applications of data science are driverless cars, gaming AI, movie recommendations, and shopping recommendations. Since the field covers such a vast array of services, datascientists can find a ton of great opportunities in their field. Datascientists use algorithms for creating data models.
Its robust ecosystem of libraries and frameworks tailored for Data Science, such as NumPy, Pandas, and Scikit-learn, contributes significantly to its popularity. Moreover, Python’s straightforward syntax allows DataScientists to focus on problem-solving rather than grappling with complex code.
It processes enormous amounts of data a human wouldn’t be able to work through in a lifetime and evolves as more data is processed. Challenges of data science Across most companies, finding, cleaning and preparing the proper data for analysis can take up to 80% of a datascientist’s day.
Machine learning (ML), a subset of artificial intelligence (AI), is an important piece of data-driven innovation. Machine learning engineers take massive datasets and use statistical methods to create algorithms that are trained to find patterns and uncover key insights in datamining projects.
Summary : This article equips Data Analysts with a solid foundation of key Data Science terms, from A to Z. Introduction In the rapidly evolving field of Data Science, understanding key terminology is crucial for Data Analysts to communicate effectively, collaborate effectively, and drive data-driven projects.
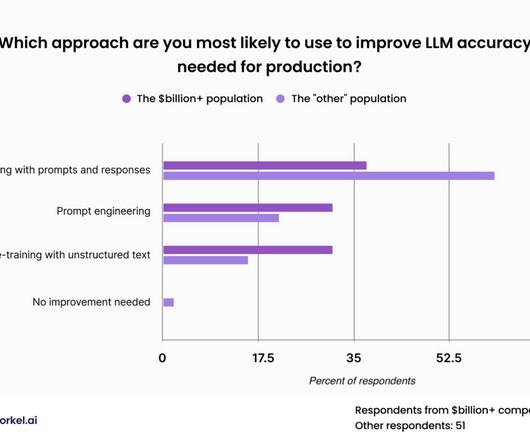
Pre-training with unstructured data Pre-training with unstructured data sounds simple: gather proprietary data from across your organization and dump it all into a self-supervisedlearning pipeline. Datascientists can clean this up ahead of pre-training in a number of ways.
Pandas: A powerful library for data manipulation and analysis, offering data structures and operations for manipulating numerical tables and time series data. Scikit-learn: A simple and efficient tool for datamining and data analysis, particularly for building and evaluating machine learning models.
Future directions in text mining include improving language understanding with the help of deep learning models, developing better techniques for multilingual text analysis, and integrating text mining with other domains like image and video analysis. Frequently Asked Questions How does text mining differ from datamining?
Pre-training with unstructured data Pre-training with unstructured data sounds simple: gather proprietary data from across your organization and dump it all into a self-supervisedlearning pipeline. Datascientists can clean this up ahead of pre-training in a number of ways.
Pre-training with unstructured data Pre-training with unstructured data sounds simple: gather proprietary data from across your organization and dump it all into a self-supervisedlearning pipeline. Datascientists can clean this up ahead of pre-training in a number of ways.
Synergy Between Artificial Intelligence and Data Science AI and Data Science complement each other through their unique but interconnected roles in data processing and analysis. Data Science involves extracting insights from structured and unstructured data using statistical methods, datamining, and visualisation techniques.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















Let's personalize your content