This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Through big datamodeling, data-driven organizations can better understand and manage the complexities of big data, improve business intelligence (BI), and enable organizations to benefit from actionable insight.
Data, undoubtedly, is one of the most significant components making up a machine learning (ML) workflow, and due to this, data management is one of the most important factors in sustaining ML pipelines.
This article was published as a part of the Data Science Blogathon. Introduction A datamodel is an abstraction of real-world events that we use to create, capture, and store data in a database that user applications require, omitting unnecessary details.
What is datamodeling is a question of the day. Databases help run applications and provide almost any information a company might require. Consider datamodeling as. But what makes a database valuable and practical?
This time, well be going over DataModels for Banking, Finance, and Insurance by Claire L. This book arms the reader with a set of best practices and datamodels to help implement solutions in the banking, finance, and insurance industries. Welcome to the first Book of the Month for 2025.This
Reading Larry Burns’ “DataModel Storytelling” (TechnicsPub.com, 2021) was a really good experience for a guy like me (i.e., someone who thinks that datamodels are narratives). The post Tales of DataModelers appeared first on DATAVERSITY. The post Tales of DataModelers appeared first on DATAVERSITY.
In addition to Business Intelligence (BI), Process Mining is no longer a new phenomenon, but almost all larger companies are conducting this data-driven process analysis in their organization. The Event Log DataModel for Process Mining Process Mining as an analytical system can very well be imagined as an iceberg.
A unified datamodel allows businesses to make better-informed decisions. By providing organizations with a more comprehensive view of the data sources they’re using, which makes it easier to understand their customers’ experiences. appeared first on DATAVERSITY.
In the current landscape, data science has emerged as the lifeblood of organizations seeking to gain a competitive edge. As the volume and complexity of data continue to surge, the demand for skilled professionals who can derive meaningful insights from this wealth of information has skyrocketed.
This blog delves into a detailed comparison between the two data management techniques. In today’s digital world, businesses must make data-driven decisions to manage huge sets of information. Hence, databases are important for strategic data handling and enhanced operational efficiency.
While the front-end report visuals are important and the most visible to end users, a lot goes on behind the scenes that contribute heavily to the end product, including datamodeling. In this blog, we’ll describe datamodeling and its significance in Power BI. What is DataModeling?
But with this rapid growth comes a key challenge: ensuring that AI-generated information is precise, trustworthy, and free from “hallucinations”. In AI, hallucinations refer to errors where the model generates incorrect or invented information.
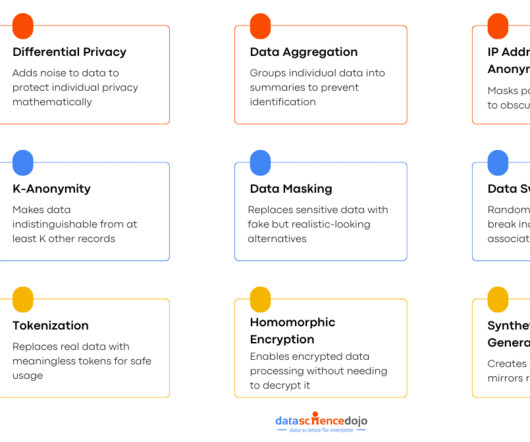
In the digital age, data is powe r. But with great power comes great responsibility, especially when it comes to protecting peoples personal information. One of the ways to make sure that data is used responsibly is through data anonymization. These concerns arent just hypothetical.
The vast majority of data created today is unstructured – that is, it’s information in many different forms that don’t follow conventional datamodels. According to IDC, 80% of all data by 2025. That makes it difficult to store and manage in a standard relational database.
By narrowing down the search space to the most relevant documents or chunks, metadata filtering reduces noise and irrelevant information, enabling the LLM to focus on the most relevant content. By combining the capabilities of LLM function calling and Pydantic datamodels, you can dynamically extract metadata from user queries.
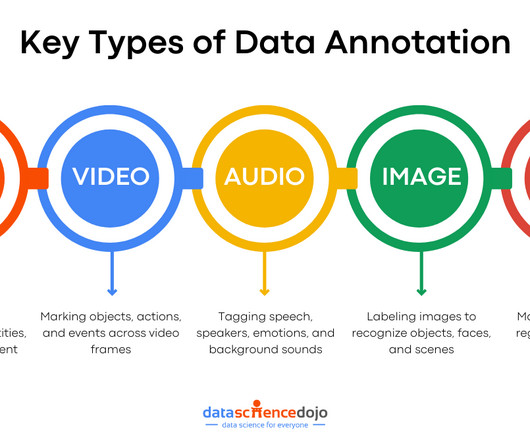
It is a fundamental step in AI training as it provides the necessary context and structure that models need to learn from raw data. It enables AI systems to recognize patterns, understand them, and make informed predictions. Video Annotation It is similar to image annotation but is applied to video data.
Researchers from many universities build open-source projects which contribute to the development of the Data Science domain. It is also called the second brain as it can store data that is not arranged according to a present datamodel or schema and, therefore, cannot be stored in a traditional relational database or RDBMS.
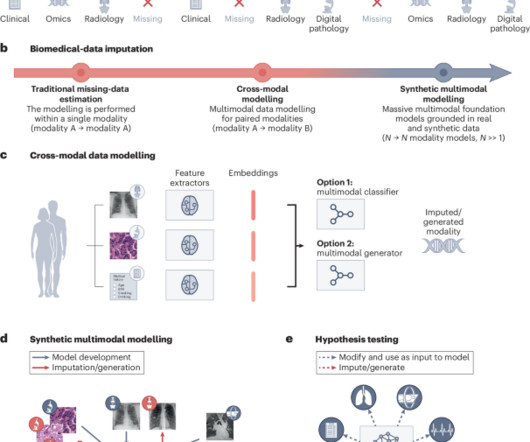
Nature Biomedical Engineering - Foundation models can be advantageously harnessed to estimate missing data in multimodal biomedical datasets and to generate realistic synthetic samples.
Whether you’re located anywhere in the world or belong to any profession, you can still develop the expertise needed to be a skilled data analyst. Who are data analysts? Data analysts are professionals who use data to identify patterns, trends, and insights that help organizations make informed decisions.
Understanding how data warehousing works and how to design and implement a data warehouse is an important skill for a data engineer. Learn about datamodeling: Datamodeling is the process of creating a conceptual representation of data.
Data vault is not just a method; its an innovative approach to datamodeling and integration tailored for modern data warehouses. As businesses continue to evolve, the complexity of managing data efficiently has grown. As businesses continue to evolve, the complexity of managing data efficiently has grown.
Specialized Industry Knowledge The University of California, Berkeley notes that remote data scientists often work with clients across diverse industries. Whether it’s finance, healthcare, or tech, each sector has unique data requirements.
You can upload your data files to this GPT that it can then analyze. Once you provide relevant prompts of focus to the GPT, it can generate appropriate data visuals based on the information from the uploaded files. Other than the advanced data analysis, it can also deal with image conversions.
DAX formulas include functions, operators, and values to perform advanced calculations and queries on data in related tables and columns in tabular datamodels. The Basics of DAX for Data Analysis DAX is a powerful language that can be used to create dynamic and informative reports that can help you make better decisions.
DAX formulas include functions, operators, and values to perform advanced calculations and queries on data in related tables and columns in tabular datamodels. The Basics of DAX for Data Analysis DAX is a powerful language that can be used to create dynamic and informative reports that can help you make better decisions.
Here are a few of the things that you might do as an AI Engineer at TigerEye: - Design, develop, and validate statistical models to explain past behavior and to predict future behavior of our customers’ sales teams - Own training, integration, deployment, versioning, and monitoring of ML components - Improve TigerEye’s existing metrics collection and (..)
This requires a strategic approach, in which CxOs should define business objectives, prioritize data quality, leverage technology, build a data-driven culture, collaborate with […] The post Facing a Big Data Blank Canvas: How CxOs Can Avoid Getting Lost in DataModeling Concepts appeared first on DATAVERSITY.
The purpose of NLQ The main goal of NLQ is to democratize access to analytical tools, making it easier for users without a deep understanding of data management to derive insights. By simplifying the querying process, NLQ allows for quicker and more efficient information retrieval.
Forbes reports that global data production increased from 2 zettabytes in 2010 to 44 ZB in 2020, with projections exceeding 180 ZB by 2025 – a staggering 9,000% growth in just 15 years, partly driven by artificial intelligence. However, raw data alone doesn’t equate to actionable insights.
To address the bias-variance trade-off: Regularization: Techniques like L1 and L2 regularization can help prevent overfitting by penalizing complex models. Ensemble methods: Combining multiple models can reduce variance and improve generalization. Model selection: Carefully selecting the appropriate model complexity for the given task.
From data discovery and cleaning to report creation and sharing, we will delve into the key steps that can be taken to turn data into decisions. A data analyst is a professional who uses data to inform business decisions. Check out this course and learn Power BI today!
This complexity hinders customers from making informed decisions. As a result, customers face challenges in selecting the right insurance coverage, while insurance aggregators and agents struggle to provide clear and accurate information.
Data management software helps in reducing the cost of maintaining the data by helping in the management and maintenance of the data stored in the database. It also helps in providing visibility to data and thus enables the users to make informed decisions. They are a part of the data management system.
As data science evolves and grows, the demand for skilled data scientists is also rising. A data scientist’s role is to extract insights and knowledge from data and to use this information to inform decisions and drive business growth.
One of the most important questions about using AI responsibly has very little to do with data, models, or anything technical. How can […] The post Ask a Data Ethicist: How Can We Set Realistic Expectations About AI? It has to do with the power of a captivating story about magical thinking.
Cloud analytics is the art and science of mining insights from data stored in cloud-based platforms. By tapping into the power of cloud technology, organizations can efficiently analyze large datasets, uncover hidden patterns, predict future trends, and make informed decisions to drive their businesses forward.
Fairness aims to prevent discrimination and bias in AI models, addressing risks where AI might reinforce harmful stereotypes or create unequal opportunities in areas like hiring, lending, or law enforcement. Security is about safeguarding AI systems from threats like adversarial attacks, model theft, and data tampering.
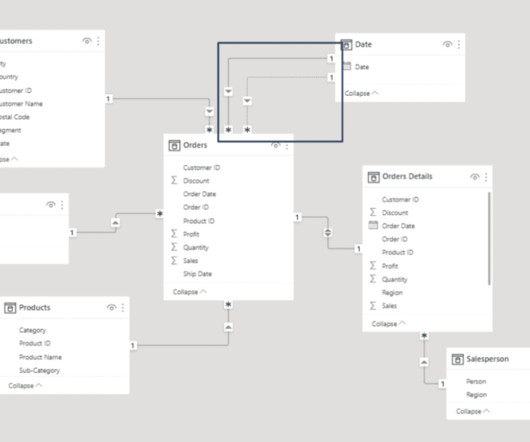
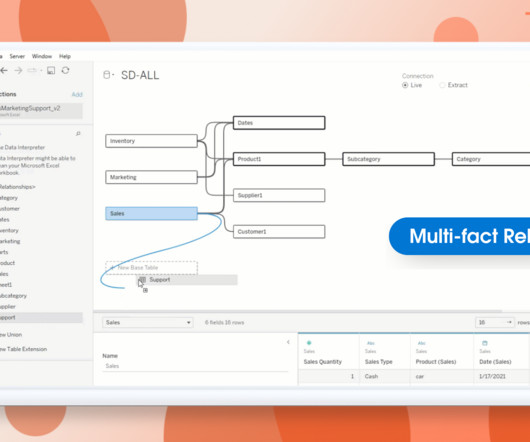
Spencer Czapiewski July 25, 2024 - 5:54pm Thomas Nhan Director, Product Management, Tableau Lari McEdward Technical Writer, Tableau Expand your datamodeling and analysis with Multi-fact Relationships, available with Tableau 2024.2. You may have heard of Multi-fact Relationships informally referred to as “shared dimensions.”
Location Based RLS An organization wants specific subsets of users only to see information about locations that are specific to them (City/State/Region/Country, etc.) Ex: We are the VP of Finance for the Western region and should only see data for that specific area. a regional sales team needs to view data for their region).
SageMaker with MLflow now supports AWS PrivateLink , which enables you to transfer critical data from your VPC to MLflow Tracking Servers through a VPC endpoint. We specify the security group and subnets information in VpcConfig. We specify the security group and subnets information in VpcConfig.
NoSQL databases became possible fairly recently, in the late 2000s, all thanks to the decrease in the price of data storage. Just like that, the need for complex and difficult-to-manage datamodels has dissipated to give way to better developer productivity. Databases of this type store data in edges and nodes.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content