This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction Have you experienced the frustration of a well-performing model in training and evaluation performing worse in the production environment? It’s a common challenge faced in the production phase, and that is where Evidently.ai, a fantastic open-source tool, comes into play to make our MLmodel observable and easy to monitor.
Data, undoubtedly, is one of the most significant components making up a machine learning (ML) workflow, and due to this, data management is one of the most important factors in sustaining ML pipelines.
With access to a wide range of generative AI foundation models (FM) and the ability to build and train their own machine learning (ML) models in Amazon SageMaker , users want a seamless and secure way to experiment with and select the models that deliver the most value for their business.
Traditional vs vector databases Datamodels Traditional databases: They use a relational model that consists of a structured tabular form. Data is contained in tables divided into rows and columns. Hence, the data is well-organized and maintains a well-defined relationship between different entities.
Customers of every size and industry are innovating on AWS by infusing machine learning (ML) into their products and services. Recent developments in generative AI models have further sped up the need of ML adoption across industries.
Here are a few of the things that you might do as an AI Engineer at TigerEye: - Design, develop, and validate statistical models to explain past behavior and to predict future behavior of our customers’ sales teams - Own training, integration, deployment, versioning, and monitoring of ML components - Improve TigerEye’s existing metrics collection and (..)
As per the TDWI survey, more than a third (nearly 37%) of people has shown dissatisfaction with their ability to access and integrate complex data streams. Why is Data Integration a Challenge for Enterprises? As complexities in big data increase each day, data integration is becoming a challenge.
Unstructured data is information that doesn’t conform to a predefined schema or isn’t organized according to a preset datamodel. Text, images, audio, and videos are common examples of unstructured data. Additionally, we show how to use AWS AI/ML services for analyzing unstructured data.
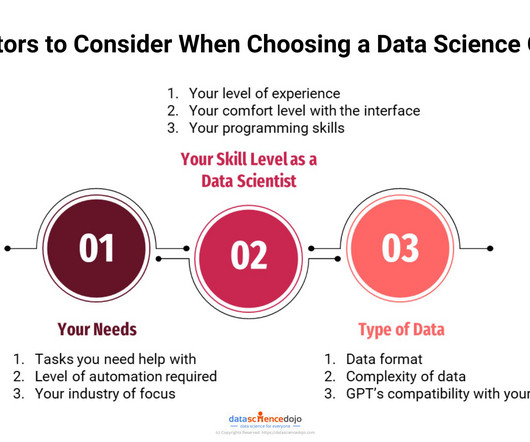
GPTs for Data science are the next step towards innovation in various data-related tasks. These are platforms that integrate the field of data analytics with artificial intelligence (AI) and machine learning (ML) solutions. Power BI Wizard It is a popular business intelligence tool that empowers you to explore data.
The machine learning systems developed by Machine Learning Engineers are crucial components used across various big data jobs in the data processing pipeline. Additionally, Machine Learning Engineers are proficient in implementing AI or ML algorithms. Is ML engineering a stressful job?
Growth Outlook: Companies like Google DeepMind, NASA’s Jet Propulsion Lab, and IBM Research actively seek research data scientists for their teams, with salaries typically ranging from $120,000 to $180,000. With the continuous growth in AI, demand for remote data science jobs is set to rise.
Be sure to check out her talk, “ Power trusted AI/ML Outcomes with Data Integrity ,” there! Due to the tsunami of data available to organizations today, artificial intelligence (AI) and machine learning (ML) are increasingly important to businesses seeking competitive advantage through digital transformation.
The onset of the pandemic has triggered a rapid increase in the demand and adoption of ML technology. Building ML team Following the surge in ML use cases that have the potential to transform business, the leaders are making a significant investment in ML collaboration, building teams that can deliver the promise of machine learning.
Article on Azure ML by Bethany Jepchumba and Josh Ndemenge of Microsoft In this article, I will cover how you can train a model using Notebooks in Azure Machine Learning Studio. At the end of this article, you will learn how to use Pytorch pretrained DenseNet 201 model to classify different animals into 48 distinct categories.
Using Azure ML to Train a Serengeti DataModel, Fast Option Pricing with DL, and How To Connect a GPU to a Container Using Azure ML to Train a Serengeti DataModel for Animal Identification In this article, we will cover how you can train a model using Notebooks in Azure Machine Learning Studio.
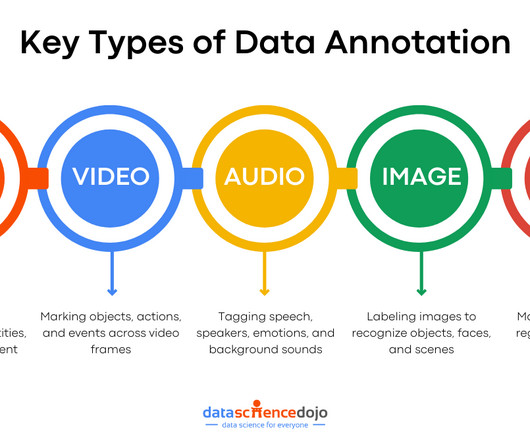
Here’s a complete guide to understanding all about LLMs What is Data Annotation? Data annotation is the process of labeling data to make it understandable and usable for machine learning (ML) models. Below are a few reasons that make data annotation a critical component for language models.
Data exploration and model development were conducted using well-known machine learning (ML) tools such as Jupyter or Apache Zeppelin notebooks. Apache Hive was used to provide a tabular interface to data stored in HDFS, and to integrate with Apache Spark SQL. HBase is employed to offer real-time key-based access to data.
Introduction: The Customer DataModeling Dilemma You know, that thing we’ve been doing for years, trying to capture the essence of our customers in neat little profile boxes? For years, we’ve been obsessed with creating these grand, top-down customer datamodels. Yeah, that one.
In the first post of this three-part series, we presented a solution that demonstrates how you can automate detecting document tampering and fraud at scale using AWS AI and machine learning (ML) services for a mortgage underwriting use case. Under Labels – optional , for Labels , choose Create new labels.
An AI database is not merely a repository of information but a dynamic and specialized system meticulously crafted to cater to the intricate demands of AI and ML applications. Herein lies the crux of the AI database’s significance: it is tailored to meet the intricate requirements that underpin the success of AI and ML endeavors.
It enhances scalability, experimentation, and reproducibility, allowing ML teams to focus on innovation. This blog highlights the importance of organised, flexible configurations in ML workflows and introduces Hydra. Machine Learning projects evolve rapidly, frequently introducing new data , models, and hyperparameters.
As with many burgeoning fields and disciplines, we don’t yet have a shared canonical infrastructure stack or best practices for developing and deploying data-intensive applications. What does a modern technology stack for streamlined ML processes look like? Why: Data Makes It Different. All ML projects are software projects.
For example, the Impute library package handles the imputation of missing values, MinMaxScaler scales datasets, or uses Autumunge to prepare table data for machine learning algorithms. Besides, Python allows creating datamodels, systematizing data sets, and developing web services for proficient data processing.
Data scientists often lack focus, time, or knowledge about software engineering principles. As a result, poor code quality and reliance on manual workflows are two of the main issues in ML development processes. You need to think about and improve the data, the model, and the code, which adds layers of complexity.
In this post, we share how Axfood, a large Swedish food retailer, improved operations and scalability of their existing artificial intelligence (AI) and machine learning (ML) operations by prototyping in close collaboration with AWS experts and using Amazon SageMaker. This is a guest post written by Axfood AB.
The ZMP analyzes billions of structured and unstructured data points to predict consumer intent by using sophisticated artificial intelligence (AI) to personalize experiences at scale. Hosted on Amazon ECS with tasks run on Fargate, this platform streamlines the end-to-end ML workflow, from data ingestion to model deployment.
Performance metrics in machine learning can even be used at the early stages of MLmodel development such as model prediction ( Image credit ) Step 3: Model prediction The model prediction is the pinnacle of a machine learning journey, where the rubber meets the road and the model’s abilities are put to the test.
GPTs for Data science are the next step towards innovation in various data-related tasks. These are platforms that integrate the field of data analytics with artificial intelligence (AI) and machine learning (ML) solutions. Power BI Wizard It is a popular business intelligence tool that empowers you to explore data.
When machine learning (ML) models are deployed into production and employed to drive business decisions, the challenge often lies in the operation and management of multiple models. That is where Provectus , an AWS Premier Consulting Partner with competencies in Machine Learning, Data & Analytics, and DevOps, stepped in.
Power BI Wizard It is a popular business intelligence tool that empowers you to explore data. The data exploration allows you to create reports, use DAX formulas for data manipulation, and suggest best practices for datamodeling. The learning assistance provides deeper insights and improved accuracy.
The key reasons that influenced this decision were: Managed service – Amazon Bedrock is a fully serverless offering that offers a choice of industry leading FMs without provisioning infrastructure, procuring GPUs around the clock, or configuring ML frameworks.
As they strive to improve models, data scientists continually try new approaches to refine their predictions. To help data scientists experiment faster, DataRobot has added Composable ML to automated machine learning. Composable ML then lets you add new types of feature engineering or build entirely new models.
For data science practitioners, productization is key, just like any other AI or ML technology. However, it's important to contextualize generative AI within the broader landscape of AI and ML technologies. By doing so, you can ensure quality and production-ready models. Here’s to a successful 2024!
Fortunately, there are many tools for ML evaluation and frameworks designed to support responsible AI development and evaluation. But let’s first take a look at some of the tools for ML evaluation that are popular for responsible AI. It includes methods for addressing fairness issues by adjusting training data, models, or outputs.
Explore ML architectural patterns in Azure for classic and evolving needs – streaming data, model monitoring, and multiple models pipeline Continue reading on MLearning.ai »
Amazon Forecast is a fully managed service that uses statistical and machine learning (ML) algorithms to deliver highly accurate time series forecasts. With SageMaker Canvas, you get faster model building , cost-effective predictions, advanced features such as a model leaderboard and algorithm selection, and enhanced transparency.
In the machine learning (ML) and artificial intelligence (AI) domain, managing, tracking, and visualizing model training processes is a significant challenge due to the scale and complexity of managed data, models, and resources.
Researchers from many universities build open-source projects which contribute to the development of the Data Science domain. It is also called the second brain as it can store data that is not arranged according to a present datamodel or schema and, therefore, cannot be stored in a traditional relational database or RDBMS.
Alignment to other tools in the organization’s tech stack Consider how well the MLOps tool integrates with your existing tools and workflows, such as data sources, data engineering platforms, code repositories, CI/CD pipelines, monitoring systems, etc. and Pandas or Apache Spark DataFrames.
The IDP Well-Architected Custom Lens follows the AWS Well-Architected Framework, reviewing the solution with six pillars with the granularity of a specific AI or machine learning (ML) use case, and providing the guidance to tackle common challenges. Model monitoring The performance of MLmodels is monitored for degradation over time.
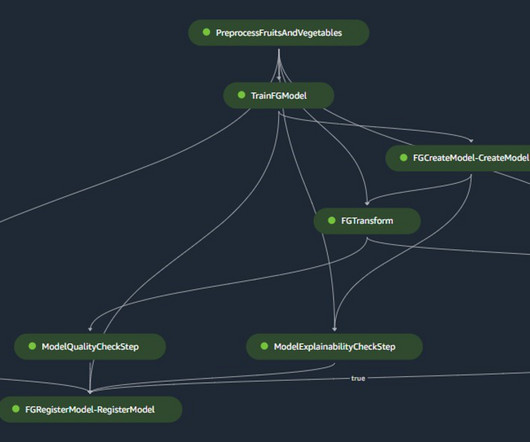
Source: Author Introduction Machine learning (ML) models, like other software, are constantly changing and evolving. Version control systems (VCS) play a key role in this area by offering a structured method to track changes made to models and handle versions of data and code used in these ML projects.
April 2018), which focused on users who do understand joins and curating federated data sources. May 2020) shifted sheets to a multiple-table datamodel, where the sheet’s fields allow the computer to write much more efficient queries to the data sources. Visual encoding is key to explaining MLmodels to humans.
During the Keynote talk Responsible AI @ Kumo AI , Hema Raghavan (Kumo AI Co-Founder & Head of Engineering) showcased platform solutions that make machine learning on relational data simple, performant, and scalable.
Hugging Face is a popular open source hub for machine learning (ML) models. He has helped launch and scale the AI/ML powered Amazon SageMaker service and has implemented several proofs of concept using Amazon AI services. client("s3") o = urlparse(s3_file, allow_fragments=False) bucket = o.netloc key = o.path.lstrip("/") s3.download_file(bucket,
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content