This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Continuous Integration and Continuous Delivery (CI/CD) for DataPipelines: It is a Game-Changer with AnalyticsCreator! The need for efficient and reliable datapipelines is paramount in data science and data engineering. They transform data into a consistent format for users to consume.
In part one of this article, we discussed how data testing can specifically test a data object (e.g., table, column, metadata) at one particular point in the datapipeline.
Data engineering is a crucial field that plays a vital role in the datapipeline of any organization. It is the process of collecting, storing, managing, and analyzing large amounts of data, and data engineers are responsible for designing and implementing the systems and infrastructure that make this possible.
Summary: Time series databases (TSDBs) are built for efficiently storing and analyzing data that changes over time. This data, often from sensors or IoT devices, is typically collected at regular intervals. Buckle up as we navigate the intricacies of storing and analysing this dynamic data.
Based on Microsoft’s discussion of the topic, CDC makes it much easier for a data store to accept changes within a database as it only updates the changed records of the database instead of reloading the entire tables that were affected. The Second Problem – Quickly Querying Data.
Summary: The fundamentals of Data Engineering encompass essential practices like datamodelling, warehousing, pipelines, and integration. Understanding these concepts enables professionals to build robust systems that facilitate effective data management and insightful analysis. What is Data Engineering?
Leveraging Looker’s semantic layer will provide Tableau customers with trusted, governed data at every stage of their analytics journey. With its LookML modeling language, Looker provides a unique, modern approach to define governed and reusable datamodels to build a trusted foundation for analytics.
If you will ask data professionals about what is the most challenging part of their day to day work, you will likely discover their concerns around managing different aspects of data before they get to graduate to the datamodeling stage. This ensures that the data is accurate, consistent, and reliable.
Model versioning, lineage, and packaging : Can you version and reproduce models and experiments? Can you see the complete model lineage with data/models/experiments used downstream? Dolt Dolt is an open-source relational database system built on Git. Is it fast and reliable enough for your workflow?
Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. They create datapipelines, ETL processes, and databases to facilitate smooth data flow and storage. Data Warehousing: Amazon Redshift, Google BigQuery, etc.
The 4 Gen AI Architecture Pipelines The four pipelines are: 1. The DataPipeline The datapipeline is the foundation of any AI system. It's responsible for collecting and ingesting the data from various external sources, processing it and managing the data.
MongoDB for end-to-end AI data management MongoDB Atlas , an integrated suite of data services centered around a multi-cloud NoSQL database, enables developers to unify operational, analytical, and AI data services to streamline building AI-enriched applications.
It simplifies feature access for model training and inference, significantly reducing the time and complexity involved in managing datapipelines. Additionally, Feast promotes feature reuse, so the time spent on data preparation is reduced greatly.
Over the past few decades, the corporate data landscape has changed significantly. The shift from on-premise databases and spreadsheets to the modern era of cloud data warehouses and AI/ LLMs has transformed what businesses can do with data. This is where Fivetran and the Modern Data Stack come in.
DagsHub DagsHub is a centralized Github-based platform that allows Machine Learning and Data Science teams to build, manage and collaborate on their projects. In addition to versioning code, teams can also version data, models, experiments and more. It does not support the ‘dvc repro’ command to reproduce its datapipeline.
It is the process of converting raw data into relevant and practical knowledge to help evaluate the performance of businesses, discover trends, and make well-informed choices. Data gathering, data integration, datamodelling, analysis of information, and data visualization are all part of intelligence for businesses.
And you should have experience working with big data platforms such as Hadoop or Apache Spark. Additionally, data science requires experience in SQL database coding and an ability to work with unstructured data of various types, such as video, audio, pictures and text.
Leveraging Looker’s semantic layer will provide Tableau customers with trusted, governed data at every stage of their analytics journey. With its LookML modeling language, Looker provides a unique, modern approach to define governed and reusable datamodels to build a trusted foundation for analytics.
Elementl / Dagster Labs Elementl and Dagster Labs are both companies that provide platforms for building and managing datapipelines. Elementl’s platform is designed for data engineers, while Dagster Labs’ platform is designed for data scientists. However, there are some critical differences between the two companies.
Managing datapipelines efficiently is paramount for any organization. The Snowflake Data Cloud has introduced a groundbreaking feature that promises to simplify and supercharge this process: Snowflake Dynamic Tables. What are Snowflake Dynamic Tables?
Having gone public in 2020 with the largest tech IPO in history, Snowflake continues to grow rapidly as organizations move to the cloud for their data warehousing needs. Importing data allows you to ingest a copy of the source data into an in-memory database.
Many mistakenly equate tabular data with business intelligence rather than AI, leading to a dismissive attitude toward its sophistication. Standard data science practices could also be contributing to this issue. One might say that tabular datamodeling is the original data-centric AI!
That said, dbt provides the ability to generate data vault models and also allows you to write your data transformations using SQL and code-reusable macros powered by Jinja2 to run your datapipelines in a clean and efficient way. The most important reason for using DBT in Data Vault 2.0
Production App - Build resilient and modular production pipelines with automation, scale, testing, observability, versioning, security, risk handling, etc. Monitoring - Monitor all resources, data, model and application metrics to ensure performance. This helps cleanse the data.
With proper unstructured data management, you can write validation checks to detect multiple entries of the same data. Continuous learning: In a properly managed unstructured datapipeline, you can use new entries to train a production ML model, keeping the model up-to-date. mp4,webm, etc.),
It involves retrieving data from various sources, such as databases, spreadsheets, or even cloud storage. The goal is to collect relevant data without affecting the source system’s performance. Compatibility with Existing Systems and Data Sources Compatibility is critical. How to drop a database in SQL server?
It consolidates data from various systems, such as transactional databases, CRM platforms, and external data sources, enabling organizations to perform complex queries and derive insights.
DataModeling, dbt has gradually emerged as a powerful tool that largely simplifies the process of building and handling datapipelines. dbt is an open-source command-line tool that allows data engineers to transform, test, and document the data into one single hub which follows the best practices of software engineering.
Data Engineering Career: Unleashing The True Potential of Data Problem-Solving Skills Data Engineers are required to possess strong analytical and problem-solving skills to navigate complex data challenges. Understanding these fundamentals is essential for effective problem-solving in data engineering.
It includes processes that trace and document the origin of data, models and associated metadata and pipelines for audits. This type of next-generation data store combines a data lake’s flexibility with a data warehouse’s performance and lets you scale AI workloads no matter where they reside.
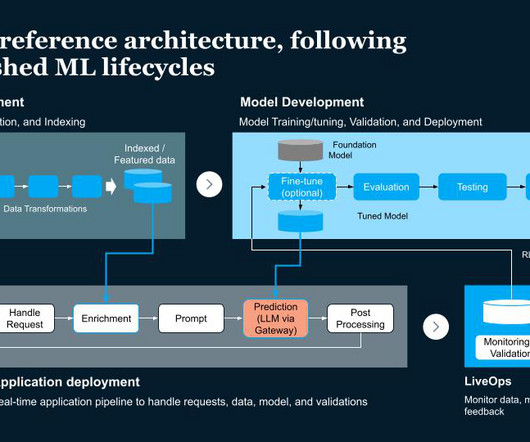
This includes management vision and strategy, resource commitment, data and tech and operating model alignment, robust risk management and change management. The required architecture includes a datapipeline, ML pipeline, application pipeline and a multi-stage pipeline. Read more here.
Thus, the solution allows for scaling data workloads independently from one another and seamlessly handling data warehousing, data lakes , data sharing, and engineering. Snowflake Database Pros Extensive Storage Opportunities Snowflake provides affordability, scalability, and a user-friendly interface.
Under this category, tools with pre-built connectors for popular data sources and visual tools for data transformation are better choices. Integration: How well does the tool integrate with your existing infrastructure, databases, cloud platforms, and analytics tools? What is Fivetran?
What does a modern data architecture do for your business? A modern data architecture like Data Mesh and Data Fabric aims to easily connect new data sources and accelerate development of use case specific datapipelines across on-premises, hybrid and multicloud environments.
Generative AI can be used to automate the datamodeling process by generating entity-relationship diagrams or other types of datamodels and assist in UI design process by generating wireframes or high-fidelity mockups. GPT-4 DataPipelines: Transform JSON to SQL Schema Instantly Blockstream’s public Bitcoin API.
Must Read Blogs: Exploring the Power of Data Warehouse Functionality. Data Lakes Vs. Data Warehouse: Its significance and relevance in the data world. Exploring Differences: Database vs Data Warehouse. Its clear structure and ease of use facilitate efficient data analysis and reporting.
The Data Source Tool can automate scanning DDL and profiling tables between source and target, comparing them, and then reporting findings. Aside from migrations, Data Source is also great for data quality checks and can generate datapipelines. But you still want to start building out the datamodel.
Data Engineer Data engineers are the authors of the infrastructure that stores, processes, and manages the large volumes of data an organization has. The main aspect of their profession is the building and maintenance of datapipelines, which allow for data to move between sources.
Team composition The team comprises datapipeline engineers, ML engineers, full-stack engineers, and data scientists. Large organizations have geographically spread out data science teams that are generally not aware of what their peers are working on.
DagsHub MLflow By using DagsHub’s MLflow implementation, the remote setup is done for us, eliminating the need to store experiment data locally or host the server ourselves. It additionally covers features such as live logging, experiment database, artifact storage, model registry, and deployment.
First up, let’s dive into the foundation of every Modern Data Stack, a cloud-based data warehouse. Central Source of Truth for Analytics A Cloud Data Warehouse (CDW) is a type of database that provides analytical data processing and storage capabilities within a cloud-based infrastructure.
It is specially designed for monitoring highly dynamic containerized environments such as Kubernetes and provides powerful features for collecting, querying, visualizing, and alerting on time-series data. Apache Airflow Apache Airflow is an open-source workflow orchestration tool that can manage complex workflows and datapipelines.
Introduction: The Customer DataModeling Dilemma You know, that thing we’ve been doing for years, trying to capture the essence of our customers in neat little profile boxes? For years, we’ve been obsessed with creating these grand, top-down customer datamodels. Yeah, that one.
An example of naming intermediate sub-directory and model file name Models The example below illustrates that intermediate models do not need to be physically present in the target database. Downstream Models Dependent on Source : Downstream models (marts or intermediate) should not directly depend on source nodes.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content