This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
MongoDB for end-to-end AI data management MongoDB Atlas , an integrated suite of data services centered around a multi-cloud NoSQL database, enables developers to unify operational, analytical, and AI data services to streamline building AI-enriched applications. Atlas Vector Search lets you search unstructured data.
User support arrangements Consider the availability and quality of support from the provider or vendor, including documentation, tutorials, forums, customer service, etc. Kubeflow integrates with popular ML frameworks, supports versioning and collaboration, and simplifies the deployment and management of ML pipelines on Kubernetes clusters.
Leveraging Looker’s semantic layer will provide Tableau customers with trusted, governed data at every stage of their analytics journey. With its LookML modeling language, Looker provides a unique, modern approach to define governed and reusable datamodels to build a trusted foundation for analytics.
That said, dbt provides the ability to generate data vault models and also allows you to write your data transformations using SQL and code-reusable macros powered by Jinja2 to run your datapipelines in a clean and efficient way. The most important reason for using DBT in Data Vault 2.0
Elementl / Dagster Labs Elementl and Dagster Labs are both companies that provide platforms for building and managing datapipelines. Elementl’s platform is designed for data engineers, while Dagster Labs’ platform is designed for data scientists. However, there are some critical differences between the two companies.
It includes processes that trace and document the origin of data, models and associated metadata and pipelines for audits. A data store lets a business connect existing data with new data and discover new insights with real-time analytics and business intelligence. Increase trust in AI outcomes.
In addition, MLOps practices like building data, experting tracking, versioning, artifacts and others, also need to be part of the GenAI productization process. For example, when indexing a new version of a document, it’s important to take care of versioning in the ML pipeline. This helps cleanse the data.
Machine Learning projects evolve rapidly, frequently introducing new data , models, and hyperparameters. Use Cases in ML Workflows Hydra excels in scenarios requiring frequent parameter tuning, such as hyperparameter optimisation, multi-environment testing, and orchestrating pipelines.
With proper unstructured data management, you can write validation checks to detect multiple entries of the same data. Continuous learning: In a properly managed unstructured datapipeline, you can use new entries to train a production ML model, keeping the model up-to-date.
Even with a composite model, the same respective considerations for Import and DirectQuery hold true. For more information on composite models, check out Microsoft’s official documentation. Creating an efficient datamodel can be the difference between having good or bad performance, especially when using DirectQuery.
Leveraging Looker’s semantic layer will provide Tableau customers with trusted, governed data at every stage of their analytics journey. With its LookML modeling language, Looker provides a unique, modern approach to define governed and reusable datamodels to build a trusted foundation for analytics.
Unconstrained, long, open-ended generation that may expose harmful or biased content to users, like legal document creation. This includes management vision and strategy, resource commitment, data and tech and operating model alignment, robust risk management and change management. Let’s dive into the data management pipeline.
Version control systems (VCS) play a key role in this area by offering a structured method to track changes made to models and handle versions of data and code used in these ML projects. With weak version control, teams could face problems like inconsistent data, model drift , and clashes in their code.
DataModeling, dbt has gradually emerged as a powerful tool that largely simplifies the process of building and handling datapipelines. dbt is an open-source command-line tool that allows data engineers to transform, test, and document the data into one single hub which follows the best practices of software engineering.
Open-Source Community: Airflow benefits from an active open-source community and extensive documentation. IBM Infosphere DataStage IBM Infosphere DataStage is an enterprise-level ETL tool that enables users to design, develop, and run datapipelines. Read Further: Azure Data Engineer Jobs.
It is the process of converting raw data into relevant and practical knowledge to help evaluate the performance of businesses, discover trends, and make well-informed choices. Data gathering, data integration, datamodelling, analysis of information, and data visualization are all part of intelligence for businesses.
dbt offers a SQL-first transformation workflow that lets teams build data transformation pipelines while following software engineering best practices like CI/CD, modularity, and documentation. Aside from migrations, Data Source is also great for data quality checks and can generate datapipelines.
DagsHub DagsHub is a centralized Github-based platform that allows Machine Learning and Data Science teams to build, manage and collaborate on their projects. In addition to versioning code, teams can also version data, models, experiments and more. It does not support the ‘dvc repro’ command to reproduce its datapipeline.
This will require investing resources in the entire AI and ML lifecycle, including building the datapipeline, scaling, automation, integrations, addressing risk and data privacy, and more. By doing so, you can ensure quality and production-ready models.
How can we build up toward our vision in terms of solvable data problems and specific data products? data sources or simpler datamodels) of the data products we want to build? Start by making a data science strategy document. What are we working towards? What are the dependencies (e.g.
DataPipeline - Manages and processes various data sources. ML Pipeline - Focuses on training, validation and deployment. Application Pipeline - Manages requests and data/model validations. Multi-Stage Pipeline - Ensures correct model behavior and incorporates feedback loops.
Thus, the solution allows for scaling data workloads independently from one another and seamlessly handling data warehousing, data lakes , data sharing, and engineering. Therefore, you’ll be empowered to truncate and reprocess data if bugs are detected and provide an excellent raw data source for data scientists.
This will require investing resources in the entire AI and ML lifecycle, including building the datapipeline, scaling, automation, integrations, addressing risk and data privacy, and more. By doing so, you can ensure quality and production-ready models.
It is specially designed for monitoring highly dynamic containerized environments such as Kubernetes and provides powerful features for collecting, querying, visualizing, and alerting on time-series data. Apache Airflow Apache Airflow is an open-source workflow orchestration tool that can manage complex workflows and datapipelines.
Business Analyst Though in many respects, quite similar to data analysts, you’ll find that business analysts most often work with a greater focus on industries such as finance, marketing, retail, and consulting. The main aspect of their profession is the building and maintenance of datapipelines, which allow for data to move between sources.
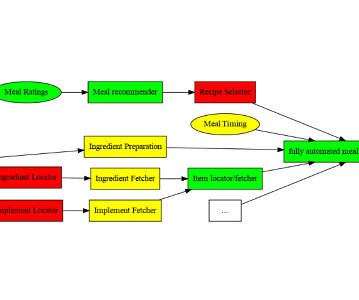
A typical machine learning pipeline with various stages highlighted | Source: Author Common types of machine learning pipelines In line with the stages of the ML workflow (data, model, and production), an ML pipeline comprises three different pipelines that solve different workflow stages.
Below is a breakdown of the areas where the dbt project evaluator validates your project: Modeling: Direct Join to Source : Models should not reference both a source and another model. Downstream Models Dependent on Source : Downstream models (marts or intermediate) should not directly depend on source nodes.
It simplifies feature access for model training and inference, significantly reducing the time and complexity involved in managing datapipelines. Additionally, Feast promotes feature reuse, so the time spent on data preparation is reduced greatly.
Functional and non-functional requirements need to be documented clearly, which architecture design will be based on and support. A typical SDLC has following stages: Stage1: Planning and requirement analysis, defining Requirements Gather requirement from end customer. Then software development phases are planned to deliver the software.
It leads to gaps in communicating the requirements, which are neither understood well nor documented properly. Team composition The team comprises datapipeline engineers, ML engineers, full-stack engineers, and data scientists.
How do you get executives to understand the value of data governance? First, document your successes of good data, and how it happened. Share stories of data in good times and in bad (pictures help!). We’re planning data governance that’s primarily focused on compliance, data privacy, and protection.
Transformation tools of old often lacked easy orchestration, were difficult to test/verify, required specialized knowledge of the tool, and the documentation of your transformations dependent on the willingness of the developer to document. It should also enable easy sharing of insights across the organization.
Summary: Data engineering tools streamline data collection, storage, and processing. Learning these tools is crucial for building scalable datapipelines. offers Data Science courses covering these tools with a job guarantee for career growth. Below are 20 essential tools every data engineer should know.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











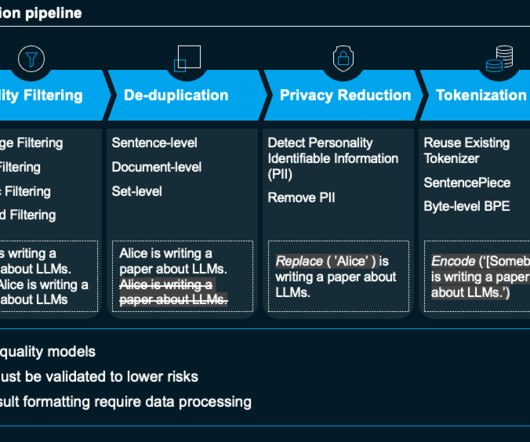


























Let's personalize your content