This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Whereas a datawarehouse will need rigid datamodeling and definitions, a data lake can store different types and shapes of data. In a data lake, the schema of the data can be inferred when it’s read, providing the aforementioned flexibility.
Want to create a robust datawarehouse architecture for your business? The sheer volume of data that companies are now gathering is incredible, and understanding how best to store and use this information to extract top performance can be incredibly overwhelming.
In this article, we will delve into the concept of data lakes, explore their differences from datawarehouses and relational databases, and discuss the significance of data version control in the context of large-scale data management. Before we address the questions, ‘ What is data version control ?’
This new approach has proven to be much more effective, so it is a skill set that people must master to become data scientists. Definition: Data Mining vs Data Science. Data mining is an automated data search based on the analysis of huge amounts of information. Data Mining Techniques and Data Visualization.
This article is an excerpt from the book Expert DataModeling with Power BI, Third Edition by Soheil Bakhshi, a completely updated and revised edition of the bestselling guide to Power BI and datamodeling. in an enterprise datawarehouse. in an enterprise datawarehouse. What is a Datamart?
Introduction: The Customer DataModeling Dilemma You know, that thing we’ve been doing for years, trying to capture the essence of our customers in neat little profile boxes? For years, we’ve been obsessed with creating these grand, top-down customer datamodels. Yeah, that one.
Monitor data sources according to policies you customize to help users know if fresh, quality data is ready for use. Shine a light on who or what is using specific data to speed up collaboration or reduce disruption when changes happen. Datamodeling. Data preparation. Data integration. Orchestration.
While there isn’t an authoritative definition for the term, it shares its ethos with its predecessor, the DevOps movement in software engineering: by adopting well-defined processes, modern tooling, and automated workflows, we can streamline the process of moving from development to robust production deployments. Why did something break?
Monitor data sources according to policies you customize to help users know if fresh, quality data is ready for use. Shine a light on who or what is using specific data to speed up collaboration or reduce disruption when changes happen. Datamodeling. Data preparation. Data integration. Orchestration.
Consider factors such as data volume, query patterns, and hardware constraints. Document and Communicate Maintain thorough documentation of fact table designs, including definitions, calculations, and relationships. Establish data governance policies and processes to ensure consistency in definitions, calculations, and data sources.
MDM is a discipline that helps organize critical information to avoid duplication, inconsistency, and other data quality issues. Transactional systems and datawarehouses can then use the golden records as the entity’s most current, trusted representation. Data Catalog and Master Data Management.
Hierarchies align datamodelling with business processes, making it easier to analyse data in a context that reflects real-world operations. Designing Hierarchies Designing effective hierarchies requires careful consideration of the business requirements and the datamodel.
One of the easiest ways for Snowflake to achieve this is to have analytics solutions query their datawarehouse in real-time (also known as DirectQuery). Creating an efficient datamodel can be the difference between having good or bad performance, especially when using DirectQuery.
Data Ingestion with Fivetran Fivetran is used to move your source(s) into a centralized space for storage. Data Storage with Snowflake Snowflake is the main datawarehouse, the foundation. Storing all the collected data sent from Fivetran Once in Snowflake, the data is ready to be accessed and analyzed.
It is a process for moving and managing data from various sources to a central datawarehouse. This process ensures that data is accurate, consistent, and usable for analysis and reporting. Definition and Explanation of the ETL Process ETL is a data integration method that combines data from multiple sources.
Definitions: Foundation Models, Gen AI, and LLMs Before diving into the practice of productizing LLMs, let’s review the basic definitions of GenAI elements: Foundation Models (FMs) - Large deep learning models that are pre-trained with attention mechanisms on massive datasets.
In this blog, we have covered Data Management and its examples along with its benefits. What is Data Management? Before delving deeper into the process of Data Management and its significance, let’s scratch the surface of the Data Management definition. The Data Steward is responsible for the same.
A truly governed self-service analytics model puts datamodeling responsibilities in the hands of IT and report generation and analysis in the hands of business users who will actually be doing the analysis. Business users build reports on an IT-owned and IT-created datamodel that is focused on reporting solutions.
Summary: A datawarehouse is a central information hub that stores and organizes vast amounts of data from different sources within an organization. Unlike operational databases focused on daily tasks, datawarehouses are designed for analysis, enabling historical trend exploration and informed decision-making.
Additionally, Feast promotes feature reuse, so the time spent on data preparation is reduced greatly. It promotes a disciplined approach to datamodeling, making it easier to ensure data quality and consistency across the ML pipelines. The following figure shows schema definition and model which reference it.
With the birth of cloud datawarehouses, data applications, and generative AI , processing large volumes of data faster and cheaper is more approachable and desired than ever. First up, let’s dive into the foundation of every Modern Data Stack, a cloud-based datawarehouse.
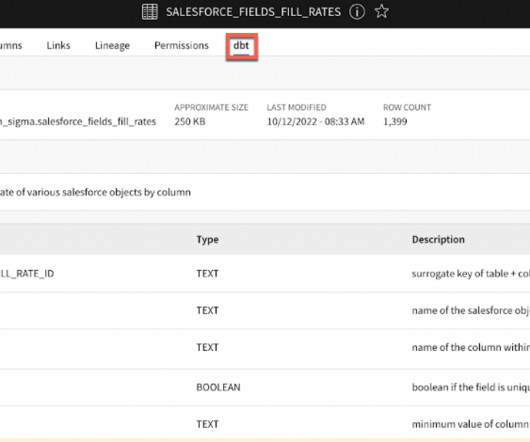
Sidebar Navigation: Provides a catalog sidebar for browsing resources by type, package, file tree, or database schema, reflecting the structure of both dbt projects and the data platform. Version Tracking: Displays version information for models, indicating whether they are prerelease, latest, or outdated.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



























Let's personalize your content