This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In the contemporary age of Big Data, DataWarehouse Systems and Data Science Analytics Infrastructures have become an essential component for organizations to store, analyze, and make data-driven decisions. So why using IaC for Cloud Data Infrastructures?
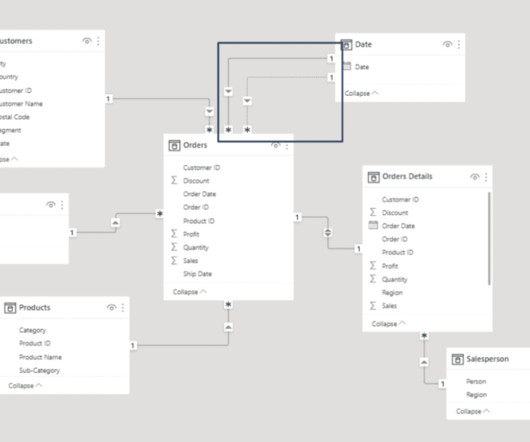
While the front-end report visuals are important and the most visible to end users, a lot goes on behind the scenes that contribute heavily to the end product, including datamodeling. In this blog, we’ll describe datamodeling and its significance in Power BI. What is DataModeling?
However, to fully harness the potential of a data lake, effective datamodeling methodologies and processes are crucial. Datamodeling plays a pivotal role in defining the structure, relationships, and semantics of data within a data lake. Consistency of data throughout the data lake.
Key features of cloud analytics solutions include: Datamodels , Processing applications, and Analytics models. Datamodels help visualize and organize data, processing applications handle large datasets efficiently, and analytics models aid in understanding complex data sets, laying the foundation for business intelligence.
It includes processes that trace and document the origin of data, models and associated metadata and pipelines for audits. How to scale AL and ML with built-in governance A fit-for-purpose data store built on an open lakehouse architecture allows you to scale AI and ML while providing built-in governance tools.
Additionally, Feast promotes feature reuse, so the time spent on data preparation is reduced greatly. It promotes a disciplined approach to datamodeling, making it easier to ensure data quality and consistency across the ML pipelines.
The ultimate need for vast storage spaces manifests in datawarehouses: specialized systems that aggregate data coming from numerous sources for centralized management and consistency. In this article, you’ll discover what a Snowflake datawarehouse is, its pros and cons, and how to employ it efficiently.
Hierarchies align datamodelling with business processes, making it easier to analyse data in a context that reflects real-world operations. Designing Hierarchies Designing effective hierarchies requires careful consideration of the business requirements and the datamodel.
With the birth of cloud datawarehouses, data applications, and generative AI , processing large volumes of data faster and cheaper is more approachable and desired than ever. First up, let’s dive into the foundation of every Modern Data Stack, a cloud-based datawarehouse.
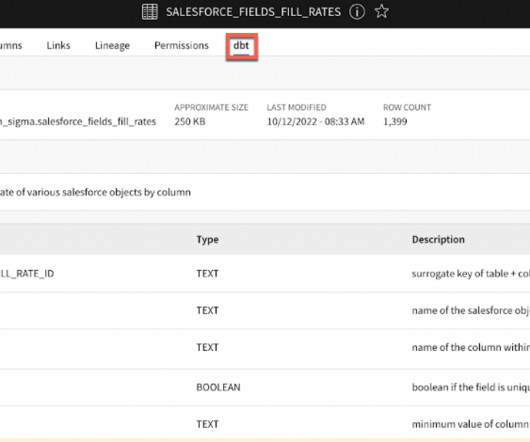
Few actors in the modern data stack have inspired the enthusiasm and fervent support as dbt. This data transformation tool enables data analysts and engineers to transform, test and documentdata in the cloud datawarehouse. This graph is an example of one analysis, documented in our internal catalog.
Data Vault - Data Lifecycle Architecturally, let’s understand the data lifecycle in the data vault into the following layers, which play a key role in choosing the right pattern and tools to implement. Data Acquisition: Extracting data from source systems and making it accessible.
One of the easiest ways for Snowflake to achieve this is to have analytics solutions query their datawarehouse in real-time (also known as DirectQuery). For more information on composite models, check out Microsoft’s official documentation. This ensures the maximum amount of Snowflake consumption possible.
The traditional data science workflow , as defined by Joe Blitzstein and Hanspeter Pfister of Harvard University, contains 5 key steps: Ask a question. Get the data. Explore the data. Model the data. A data catalog can assist directly with every step, but model development.
External Data Sources: These can be market research data, social media feeds, or third-party databases that provide additional insights. Data can be structured (e.g., documents and images). The diversity of data sources allows organizations to create a comprehensive view of their operations and market conditions.
Consider factors such as data volume, query patterns, and hardware constraints. Document and Communicate Maintain thorough documentation of fact table designs, including definitions, calculations, and relationships. Use indexing and partitioning strategies to improve query performance.
A common problem solved by phData is the migration from an existing data platform to the Snowflake Data Cloud , in the best possible manner. This allows you to potentially build out a new datamodel , reduce any complexity from the existing architecture, and plan for the long-term future use cases.
DataModeling, dbt has gradually emerged as a powerful tool that largely simplifies the process of building and handling data pipelines. dbt is an open-source command-line tool that allows data engineers to transform, test, and document the data into one single hub which follows the best practices of software engineering.
It is the process of converting raw data into relevant and practical knowledge to help evaluate the performance of businesses, discover trends, and make well-informed choices. Data gathering, data integration, datamodelling, analysis of information, and data visualization are all part of intelligence for businesses.
dbt offers a SQL-first transformation workflow that lets teams build data transformation pipelines while following software engineering best practices like CI/CD, modularity, and documentation. But you still want to start building out the datamodel.
Also Read: Top 10 Data Science tools for 2024. It is a process for moving and managing data from various sources to a central datawarehouse. This process ensures that data is accurate, consistent, and usable for analysis and reporting. This process helps organisations manage large volumes of data efficiently.
In addition, MLOps practices like building data, experting tracking, versioning, artifacts and others, also need to be part of the GenAI productization process. For example, when indexing a new version of a document, it’s important to take care of versioning in the ML pipeline. This also makes indexing more efficient.
MDM is a discipline that helps organize critical information to avoid duplication, inconsistency, and other data quality issues. Transactional systems and datawarehouses can then use the golden records as the entity’s most current, trusted representation. Data Catalog and Master Data Management.
Using SQL-centric transformations to modeldata to be deployed. dbt is also great for data lineage and documentation to empower business analysts to make informed decisions on their data. Data Ingestion with Fivetran Fivetran is used to move your source(s) into a centralized space for storage.
A truly governed self-service analytics model puts datamodeling responsibilities in the hands of IT and report generation and analysis in the hands of business users who will actually be doing the analysis. Business users build reports on an IT-owned and IT-created datamodel that is focused on reporting solutions.
With Snowflake, data stewards have a choice to leverage Snowflake’s governance policies. First, stewards are dependent on datawarehouse admins to provide information and to create and edit enforcement policies in Snowflake. Operationalize data governance at scale. Two problems arise. In Summary.
Their tasks encompass: Data Collection and Extraction Identify relevant data sources and gather data from various internal and external systems Extract, transform, and load data into a centralized datawarehouse or analytics platform Data Cleaning and Preparation Cleanse and standardize data to ensure accuracy, consistency, and completeness.
When a new entrant to ETL development reads this article, they could easily have mastered Matillion Designer’s methods or read through the Matillion Versioning Documentation to develop their own approach to ZDLC. One scenario could be multiple team members who will each work on ingesting and processing data from one of the source systems.
In this article, we’ll explore how AI can transform unstructured data into actionable intelligence, empowering you to make informed decisions, enhance customer experiences, and stay ahead of the competition. What is Unstructured Data? These AI models use multimedia data to understand and improve more complicated information.
Structuring the dbt Project The most important aspect of any dbt project is its structural design, which organizes project files and code in a way that supports scalability for large datawarehouses. Downstream Models Dependent on Source : Downstream models (marts or intermediate) should not directly depend on source nodes.
It is widely used for storing and managing structured data, making it an essential tool for data engineers. MongoDB MongoDB is a NoSQL database that stores data in flexible, JSON-like documents. Apache Spark Apache Spark is a powerful data processing framework that efficiently handles Big Data.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


































Let's personalize your content