This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Anomaly detection can assist in seeing surges in partially completed or fully completed transactions in sectors like e-commerce, marketing, and others, allowing for aligning to shifts in demand or spotting […] The post Anomaly Detection in ECG Signals: Identifying Abnormal Heart Patterns Using DeepLearning appeared first on Analytics Vidhya. (..)
Key Skills: Mastery in machine learning frameworks like PyTorch or TensorFlow is essential, along with a solid foundation in unsupervised learning methods. Stanford AI Lab recommends proficiency in deeplearning, especially if working in experimental or cutting-edge areas.
The machine learning systems developed by Machine Learning Engineers are crucial components used across various big data jobs in the data processing pipeline. Additionally, Machine Learning Engineers are proficient in implementing AI or ML algorithms. Is ML engineering a stressful job?
Photo by RetroSupply on Unsplash Introduction Deeplearning has been widely used in various fields, such as computer vision, NLP, and robotics. The success of deeplearning is largely due to its ability to learn complex representations from data using deep neural networks.
In the first post of this three-part series, we presented a solution that demonstrates how you can automate detecting document tampering and fraud at scale using AWS AI and machine learning (ML) services for a mortgage underwriting use case. Under Labels – optional , for Labels , choose Create new labels.
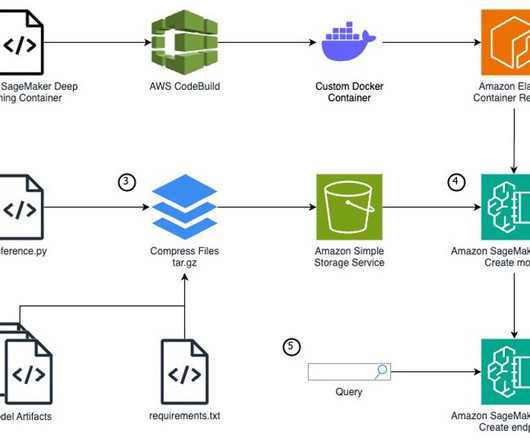
Amazon SageMake r provides a seamless experience for building, training, and deploying machine learning (ML) models at scale. You use an AWS DeepLearning SageMaker framework container as the base image because it includes required dependencies such as SageMaker libraries, PyTorch, and CUDA.
Article on Azure ML by Bethany Jepchumba and Josh Ndemenge of Microsoft In this article, I will cover how you can train a model using Notebooks in Azure Machine Learning Studio. At the end of this article, you will learn how to use Pytorch pretrained DenseNet 201 model to classify different animals into 48 distinct categories.
Using Azure ML to Train a Serengeti DataModel, Fast Option Pricing with DL, and How To Connect a GPU to a Container Using Azure ML to Train a Serengeti DataModel for Animal Identification In this article, we will cover how you can train a model using Notebooks in Azure Machine Learning Studio.
To get started, see Understanding intelligent prompt routing in Amazon Bedrock About the authors Shreyas Subramanian is a Principal Data Scientist and helps customers by using generative AI and deeplearning to solve their business challenges using AWS services.
Summary: Hydra simplifies process configuration in Machine Learning by dynamically managing parameters, organising configurations hierarchically, and enabling runtime overrides. It enhances scalability, experimentation, and reproducibility, allowing ML teams to focus on innovation. billion in 2022, is expected to soar to USD 505.42
As with many burgeoning fields and disciplines, we don’t yet have a shared canonical infrastructure stack or best practices for developing and deploying data-intensive applications. What does a modern technology stack for streamlined ML processes look like? Why: Data Makes It Different. All ML projects are software projects.
Alignment to other tools in the organization’s tech stack Consider how well the MLOps tool integrates with your existing tools and workflows, such as data sources, data engineering platforms, code repositories, CI/CD pipelines, monitoring systems, etc. and Pandas or Apache Spark DataFrames.
What Zeta has accomplished in AI/ML In the fast-evolving landscape of digital marketing, Zeta Global stands out with its groundbreaking advancements in artificial intelligence. Zeta’s AI innovation is powered by a proprietary machine learning operations (MLOps) system, developed in-house.
In order to improve our equipment reliability, we partnered with the Amazon Machine Learning Solutions Lab to develop a custom machine learning (ML) model capable of predicting equipment issues prior to failure. We first highlight how we use AWS Glue for highly parallel data processing.
When machine learning (ML) models are deployed into production and employed to drive business decisions, the challenge often lies in the operation and management of multiple models. They swiftly began to work on AI/ML capabilities by building image recognition models using Amazon SageMaker.
In 2024, however, organizations are using large language models (LLMs), which require relatively little focus on NLP, shifting research and development from modeling to the infrastructure needed to support LLM workflows. Metaflow’s coherent APIs simplify the process of building real-world ML/AI systems in teams.
In this post, we’ll summarize training procedure of GPT NeoX on AWS Trainium , a purpose-built machine learning (ML) accelerator optimized for deeplearning training. M tokens/$) trained such models with AWS Trainium without losing any model quality. models on AWS Trn1 with Neuron NeMo library.
How to Use Machine Learning (ML) for Time Series Forecasting — NIX United The modern market pace calls for a respective competitive edge. Data forecasting has come a long way since formidable data processing-boosting technologies such as machine learning were introduced.
Utilizing data streamed through LnW Connect, L&W aims to create better gaming experience for their end-users as well as bring more value to their casino customers. Predictive maintenance is a common ML use case for businesses with physical equipment or machinery assets. We used AutoGluon to explore several classic ML algorithms.
Hugging Face is a popular open source hub for machine learning (ML) models. He has helped launch and scale the AI/ML powered Amazon SageMaker service and has implemented several proofs of concept using Amazon AI services. Kiran Challapalli is a deep tech business developer with the AWS public sector.
What Does a Credit Score or Decisioning ML Pipeline Look Like? Now that we have a firm grasp on the underlying business case, we will now define a machine learning pipeline in the context of credit models. Data Preparation The first step in the process is data collection and preparation. Want to learn more?
These days enterprises are sitting on a pool of data and increasingly employing machine learning and deeplearning algorithms to forecast sales, predict customer churn and fraud detection, etc., MLmodel versioning: where are we at? The short answer is we are in the middle of a data revolution.
Model Performance Monitoring includes measuring the model’s accuracy and other performance metrics over time. Feedback Monitoring gathers feedback from users and stakeholders to ensure the model meets their needs and expectations. This article will cover the challenges you can face with Machine Learningmodels in production.
SageMaker Training is a comprehensive, fully managed ML service that enables scalable model training. It provides flexible compute resource selection, support for custom libraries, a pay-as-you-go pricing model, and self-healing capabilities. GB saved to /opt/ml/input/data/model/quantized/meta_model_0-8da4w.pt.
Understanding Machine Learning algorithms and effective data handling are also critical for success in the field. Introduction Machine Learning ( ML ) is revolutionising industries, from healthcare and finance to retail and manufacturing. This growth signifies Python’s increasing role in ML and related fields.
Model fine-tuning Model training: Once the data is prepared, the LLM is trained. This is done by using a machine learning algorithm to learn the patterns in the data. Model evaluation: Once the LLM is trained, it needs to be evaluated to see how well it performs.
In today’s landscape, AI is becoming a major focus in developing and deploying machine learningmodels. It isn’t just about writing code or creating algorithms — it requires robust pipelines that handle data, model training, deployment, and maintenance. Model Training: Running computations to learn from the data.
and train models with a single click of a button. Advanced users will appreciate tunable parameters and full access to configuring how DataRobot processes data and builds models with composable ML. Access the full potential of your models by using DataRobot with your text data.
But its status as the go-between for programming and data professionals isn’t its only power. Within SQL you can also filter data, aggregate it and create valuations, manipulate data, update it, and even do datamodeling.
Based on our experience, manufacturing customers have the most success (in terms of adopting AI) with the following applications: Demand Forecasting Whether building better demand forecasts , optimizing logistics, scheduling production, or improving inventory management, ML-driven demand forecasting delivers real predictive value.
It removes the undifferentiated heavy lifting involved in building and optimizing machine learning (ML) infrastructure for training foundation models (FMs). In this post, we share an ML infrastructure architecture that uses SageMaker HyperPod to support research team innovation in video generation.
This is where ML experiment tracking comes into play! What is ML Experiment Tracking? ML experiment tracking is the process of recording, organizing, and analyzing the results of ML experiments. It helps data scientists keep track of their experiments, reproduce their results, and collaborate with others effectively.
Thomson Reuters , a global content and technology-driven company, has been using artificial intelligence and machine learning (AI/ML) in its professional information products for decades. It provides resilient and persistent clusters for large-scale deeplearning training of FMs on long-running compute clusters.
Source: [link] Similarly, while building any machine learning-based product or service, training and evaluating the model on a few real-world samples does not necessarily mean the end of your responsibilities. You need to make that model available to the end users, monitor it, and retrain it for better performance if needed.
Data scientists drive business outcomes. Many implement machine learning and artificial intelligence to tackle challenges in the age of Big Data. They develop and continuously optimize AI/MLmodels , collaborating with stakeholders across the enterprise to inform decisions that drive strategic business value.
It uses advanced tools to look at raw data, gather a data set, process it, and develop insights to create meaning. Areas making up the data science field include mining, statistics, data analytics, datamodeling, machine learningmodeling and programming. What is machine learning?
LLM models are large deeplearningmodels that are trained on vast datasets, are adaptable to various tasks and specialize in NLP tasks. They are characterized by their enormous size, complexity, and the vast amount of data they process. Data Pipeline - Manages and processes various data sources.
Introduction Welcome to the step-by-step guide on efficiently managing TensorFlow/Keras model development with Comet. TensorFlow and Keras have emerged as powerful frameworks for building and training deeplearningmodels. Introducing MLOps Machine learning (ML) is an essential tool for businesses of all sizes.
With these several trials, it is quite common to lose track of all the combinations that you might have tried out in pursuit of a better MLmodel. Why is ML Experiment Tracking Important? This is one of the most important reasons why you need to keep track of all the experiments (including minor ones) in the modeling phase.
Unsurprisingly, Machine Learning (ML) has seen remarkable progress, revolutionizing industries and how we interact with technology. The emergence of Large Language Models (LLMs) like OpenAI's GPT , Meta's Llama , and Google's BERT has ushered in a new era in this field. Their mission?
By utilizing Snowflake as its central repository for user data and integrating it with various machine-learning tools, the service would be able to store and analyze petabytes of data efficiently, providing accurate recommendations at scale. Many datasets are produced and sold on the Marketplace to enrich datamodels.
As an ML engineer you’re in charge of some code/model. MLOps cover all of the rest, how to track your experiments, how to share your work, how to version your models etc (Full list in the previous post. ). Not having a local model is not an excuse to throw organization, versioning and just good ol’ clean code patterns for.
Moreover, you can easily opt for 6 month certification program that pays well in the field that will allow you to gain perfection in ML. Learn the techniques in Machine Learning Use different tools for applications of ML and NLP Salary of the ML Engineer in India ranges between 3 Lakhs to 20.8 Lakhs annually.
Definitions: Foundation Models, Gen AI, and LLMs Before diving into the practice of productizing LLMs, let’s review the basic definitions of GenAI elements: Foundation Models (FMs) - Large deeplearningmodels that are pre-trained with attention mechanisms on massive datasets.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content