This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
So why using IaC for Cloud Data Infrastructures? This ensures that the datamodels and queries developed by data professionals are consistent with the underlying infrastructure. Enhanced Security and Compliance Data Warehouses often store sensitive information, making security a paramount concern.
The issue is that it is difficult to manage data without the right infrastructure. NoSQL databases are the alternative to SQL databases. They come in different types and provide flexible schemas, allowing them to easily scale with high user loads and large data amounts. The four main types are: Document databases.
In this post, we provide an overview of the Meta Llama 3 models available on AWS at the time of writing, and share best practices on developing Text-to-SQL use cases using Meta Llama 3 models. Meta Llama 3’s capabilities enhance accuracy and efficiency in understanding and generating SQL queries from natural language inputs.
Data is driving most business decisions. In this, datamodeling tools play a crucial role in developing and maintaining the information system. Moreover, it involves the creation of a conceptual representation of data and its relationship. Datamodeling tools play a significant role in this.
I’ve found that while calculating automation benefits like time savings is relatively straightforward, users struggle to estimate the value of insights, especially when dealing with previously unavailable data. We were developing a datamodel to provide deeper insights into logistics contracts.
However, to fully harness the potential of a data lake, effective datamodeling methodologies and processes are crucial. Datamodeling plays a pivotal role in defining the structure, relationships, and semantics of data within a data lake. Consistency of data throughout the data lake.
These formats play a significant role in how data is processed, analyzed, and used to develop AI models. Structured data is organized in a highly organized and predefined manner. It follows a clear datamodel, where each data entry has specific fields and attributes with well-defined data types.
That said, dbt provides the ability to generate data vault models and also allows you to write your data transformations using SQL and code-reusable macros powered by Jinja2 to run your data pipelines in a clean and efficient way. The most important reason for using DBT in Data Vault 2.0
My approach to graph-based Retrieval Augmented Generation The approach is a bit more rooted in traditional methods, I parse the DataModel (an SQL-based relational system) into Nodes and Relationships in a graph database and then provide an endpoint where those relationships can be queried to provide a source of truth.
This allows you to explore features spanning more than 40 Tableau releases, including links to release documentation. . A diamond mark can be selected to list the features in that release, and selecting a colored square in the feature list will open release documentation in your browser. The Salesforce purchase in 2019.
A common problem solved by phData is the migration from an existing data platform to the Snowflake Data Cloud , in the best possible manner. The necessary access is granted so data flows without issue. SQL Server Agent jobs). Either way, it’s important to understand what data is transformed, and how so.
What Are Their Ranges of DataModels? MongoDB has a wider range of datatypes than DynamoDB, even though both databases can store binary data. DynamoDB is limited to 400KB for documents and MongoDB can support up to 16MB file sizes. It is compatible with a laptop to mainframe and on-premise through a hybrid cloud.
Cassandra excels in high write throughput and availability, while MongoDB offers flexible document storage and powerful querying capabilities. Both databases are designed to handle large volumes of data, but they cater to different use cases and exhibit distinct architectural designs. What is Apache Cassandra? What is MongoDB?
Among other features, Azure Cosmos DB is notable in that it supports multiple datamodels and APIs. When you create a new Cosmos DB account, you specify which API you want to use: SQL/core API, which lets you use a dialect of T-SQL to query and manage tables and documents; MongoDB; Azure table storage; Cassandra; or Gremlin (graph).
The June 2021 release of Power BI Desktop introduced Custom SQL queries to Snowflake in DirectQuery mode. In 2021, Microsoft enabled Custom SQL queries to be run to Snowflake in DirectQuery mode further enhancing the connection capabilities between the platforms.
Summary: Relational Database Management Systems (RDBMS) are the backbone of structured data management, organising information in tables and ensuring data integrity. This article explores RDBMS’s features, advantages, applications across industries, the role of SQL, and emerging trends shaping the future of data management.
Additionally, Feast promotes feature reuse, so the time spent on data preparation is reduced greatly. It promotes a disciplined approach to datamodeling, making it easier to ensure data quality and consistency across the ML pipelines.
Leveraging Looker’s semantic layer will provide Tableau customers with trusted, governed data at every stage of their analytics journey. With its LookML modeling language, Looker provides a unique, modern approach to define governed and reusable datamodels to build a trusted foundation for analytics.
It is the process of converting raw data into relevant and practical knowledge to help evaluate the performance of businesses, discover trends, and make well-informed choices. Data gathering, data integration, datamodelling, analysis of information, and data visualization are all part of intelligence for businesses.
Gen AI can automate microservice generation within a low-code platform by interpreting user-defined requirements and generating service interfaces, datamodels, and even testing scripts. User experience (UX) design AI-driven prototyping and UI generation So, it is usually the bottle-neck in development: intuitive and attractive UIs.
It is open-source and uses Structured Query Language (SQL) to manage and manipulate data. Its simplicity, reliability, and performance have made it popular for web applications, data warehousing , and e-commerce platforms. PostgreSQLs architecture is highly flexible, supporting many datamodels and workloads.
Functional and non-functional requirements need to be documented clearly, which architecture design will be based on and support. GPT-4 Data Pipelines: Transform JSON to SQL Schema Instantly Blockstream’s public Bitcoin API. The data would be interesting to analyze.
Some of the most popular relational databases include Oracle, MySQL, and Microsoft SQL Server. Document Databases Document databases organize data in the form of documents instead of rows and columns. These databases are intended to accommodate unstructured data like texts, images, and videos.
Hierarchies align datamodelling with business processes, making it easier to analyse data in a context that reflects real-world operations. Designing Hierarchies Designing effective hierarchies requires careful consideration of the business requirements and the datamodel.
The answer probably depends more on the complexity of your queries than the connectedness of your data. Relational databases (with recursive SQL queries), document stores, key-value stores, etc., Multi-model databases combine graphs with two other NoSQL datamodels – document and key-value stores.
DagsHub DagsHub is a centralized Github-based platform that allows Machine Learning and Data Science teams to build, manage and collaborate on their projects. In addition to versioning code, teams can also version data, models, experiments and more. Most developers are familiar with Git for source code versioning.
Challenges and considerations with RAG architectures Typical RAG architecture at a high level involves three stages: Source data pre-processing Generating embeddings using an embedding LLM Storing the embeddings in a vector store. Vector embeddings include the numeric representations of text data within your documents.
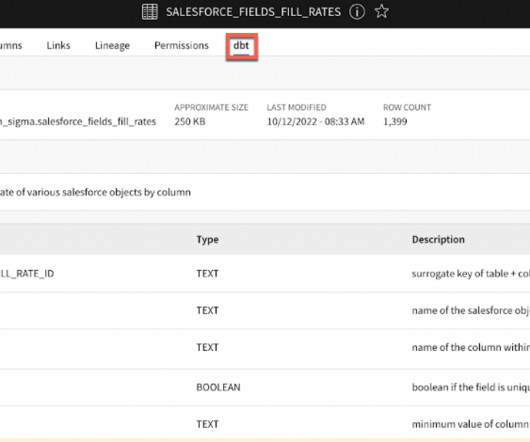
Few actors in the modern data stack have inspired the enthusiasm and fervent support as dbt. This data transformation tool enables data analysts and engineers to transform, test and documentdata in the cloud data warehouse. This graph is an example of one analysis, documented in our internal catalog.
This allows you to explore features spanning more than 40 Tableau releases, including links to release documentation. . A diamond mark can be selected to list the features in that release, and selecting a colored square in the feature list will open release documentation in your browser. The Salesforce purchase in 2019.
What do machine learning engineers do: They implement and train machine learning modelsDatamodeling One of the primary tasks in machine learning is to analyze unstructured datamodels, which requires a solid foundation in datamodeling.
Leveraging Looker’s semantic layer will provide Tableau customers with trusted, governed data at every stage of their analytics journey. With its LookML modeling language, Looker provides a unique, modern approach to define governed and reusable datamodels to build a trusted foundation for analytics.
dbt allows the data transformation to be modular, testable, and well-documented, and here we leverage it to deliver rapid, high-quality, and cost-efficient solutions with accurate and accessible data for data-driven decisions. Best Practices: We want our clients to own their data and to take care of it.
Below are five of our most popular dbt resources: Is dbt a Good Tool for Implementing DataModels? dbt allows data transformations to be modular, testable, and well-documented, and at phData, we leverage it to deliver rapid, high-quality, and cost-efficient solutions with accurate and accessible data for data-driven decisions.
Using SQL-centric transformations to modeldata to be deployed. dbt is also great for data lineage and documentation to empower business analysts to make informed decisions on their data. Is dbt an Ideal Fit for YOUR Organization’s Data Stack? It is a compiler and a runner. Proceed as you see fit.
The traditional data science workflow , as defined by Joe Blitzstein and Hanspeter Pfister of Harvard University, contains 5 key steps: Ask a question. Get the data. Explore the data. Model the data. A data catalog can assist directly with every step, but model development.
User support arrangements Consider the availability and quality of support from the provider or vendor, including documentation, tutorials, forums, customer service, etc. Check out the Kubeflow documentation. Metaflow Metaflow helps data scientists and machine learning engineers build, manage, and deploy data science projects.
dbt offers a SQL-first transformation workflow that lets teams build data transformation pipelines while following software engineering best practices like CI/CD, modularity, and documentation. But you still want to start building out the datamodel. The Translation Tool takes care of all of that for you.
DataModeling, dbt has gradually emerged as a powerful tool that largely simplifies the process of building and handling data pipelines. dbt is an open-source command-line tool that allows data engineers to transform, test, and document the data into one single hub which follows the best practices of software engineering.
Data warehousing is a vital constituent of any business intelligence operation. Companies can build Snowflake databases expeditiously and use them for ad-hoc analysis by making SQL queries. Machine Learning Integration Opportunities Organizations harness machine learning (ML) algorithms to make forecasts on the data.
Here’s the structured equivalent of this same data in tabular form: With structured data, you can use query languages like SQL to extract and interpret information. In contrast, such traditional query languages struggle to interpret unstructured data. Storage Tools To work with unstructured data, you need to store it.
External Data Sources: These can be market research data, social media feeds, or third-party databases that provide additional insights. Data can be structured (e.g., documents and images). The diversity of data sources allows organizations to create a comprehensive view of their operations and market conditions.
Open-Source Community: Airflow benefits from an active open-source community and extensive documentation. IBM Infosphere DataStage IBM Infosphere DataStage is an enterprise-level ETL tool that enables users to design, develop, and run data pipelines. Scalability: Designed to handle large volumes of data efficiently.
Be very careful about documents that require any sort of precision. Still, I would want a human lawyer to review anything it produced; legal documents require precision. Applications built on top of models like ChatGPT have to watch for prompt injection, an attack first described by Riley Goodside. What Is the Future?
The database would need to be highly available and resilient, with features like automatic failover and data replication to ensure that the system remains up and running even in the face of hardware or software failures. This could be achieved through the use of a NoSQL datamodel, such as document or key-value stores.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content