This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
With access to a wide range of generative AI foundation models (FM) and the ability to build and train their own machine learning (ML) models in Amazon SageMaker , users want a seamless and secure way to experiment with and select the models that deliver the most value for their business.
In 2024, however, organizations are using large language models (LLMs), which require relatively little focus on NLP, shifting research and development from modeling to the infrastructure needed to support LLM workflows. Metaflow’s coherent APIs simplify the process of building real-world ML/AI systems in teams.
Researchers from many universities build open-source projects which contribute to the development of the Data Science domain. It is also called the second brain as it can store data that is not arranged according to a present datamodel or schema and, therefore, cannot be stored in a traditional relational database or RDBMS.
Amazon Forecast is a fully managed service that uses statistical and machine learning (ML) algorithms to deliver highly accurate time series forecasts. With SageMaker Canvas, you get faster model building , cost-effective predictions, advanced features such as a model leaderboard and algorithm selection, and enhanced transparency.
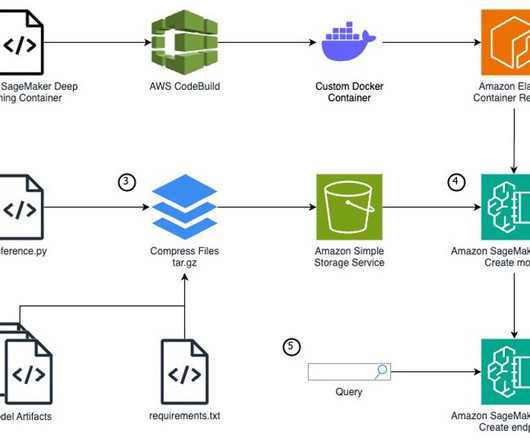
Hugging Face is a popular open source hub for machine learning (ML) models. Create a model function for accessing PyAnnote speaker diarization from Hugging Face You can use the Hugging Face Hub to access the desired pre-trained PyAnnote speaker diarization model. and requirements.txt files and save it as model.tar.gz : !
Alignment to other tools in the organization’s tech stack Consider how well the MLOps tool integrates with your existing tools and workflows, such as data sources, data engineering platforms, code repositories, CI/CD pipelines, monitoring systems, etc. and Pandas or Apache Spark DataFrames.
You could further optimize the time for training in the following graph by using a SageMaker managed warm pool and accessing pre-downloadedmodels using Amazon Elastic File System (Amazon EFS). Challenges with fine-tuning LLMs Generative AI models offer many promising business use cases. 8b-lora.yaml on an ml.p4d.24xlarge
We live in a world where vast amounts of data are being collected, and unprecedented compute power is available to extract value. The advancement of technology in large language models (LLMs), machine learning (ML), and data science can truly transform industries through insights and predictions.
In this post, we’ll summarize training procedure of GPT NeoX on AWS Trainium , a purpose-built machine learning (ML) accelerator optimized for deep learning training. M tokens/$) trained such models with AWS Trainium without losing any model quality. We’ll outline how we cost-effectively (3.2
Complete the following steps for manual deployment: Download these assets directly from the GitHub repository. Make sure you’re updating the datamodel ( updateTrackListData function) to handle your custom fields. The assets (JavaScript and CSS files) are available in our GitHub repository. Host them in your own S3 bucket.
Creating high-performance machine learning (ML) solutions relies on exploring and optimizing training parameters, also known as hyperparameters. It provides key functionality that allows you to focus on the ML problem at hand while automatically keeping track of the trials and results. We use a Random Forest from SkLearn.
AutoML allows you to derive rapid, general insights from your data right at the beginning of a machine learning (ML) project lifecycle. Understanding up front which preprocessing techniques and algorithm types provide best results reduces the time to develop, train, and deploy the right model.
As an ML engineer you’re in charge of some code/model. MLOps cover all of the rest, how to track your experiments, how to share your work, how to version your models etc (Full list in the previous post. ). Not having a local model is not an excuse to throw organization, versioning and just good ol’ clean code patterns for.
Data scientists drive business outcomes. Many implement machine learning and artificial intelligence to tackle challenges in the age of Big Data. They develop and continuously optimize AI/MLmodels , collaborating with stakeholders across the enterprise to inform decisions that drive strategic business value.
Simple methods for time series forecasting use historical values of the same variable whose future values need to be predicted, whereas more complex, machine learning (ML)-based methods use additional information, such as the time series data of related variables. You should see the data imports in progress.
In this post, we show you how to train the 7-billion-parameter BloomZ model using just a single graphics processing unit (GPU) on Amazon SageMaker , Amazon’s machine learning (ML) platform for preparing, building, training, and deploying high-quality MLmodels. Then, it starts the training job.
In addition to versioning code, teams can also version data, models, experiments and more. Released in 2022, DagsHub’s Direct Data Access (DDA for short) allows Data Scientists and Machine Learning engineers to stream files from DagsHub repository without needing to download them to their local environment ahead of time.
Introducing MLOps Machine learning (ML) is an essential tool for businesses of all sizes. However, deploying MLmodels in production can be complex and challenging. MLOps encompasses the entire ML lifecycle, from data preparation to model deployment and monitoring. Second, MLmodels are constantly evolving.
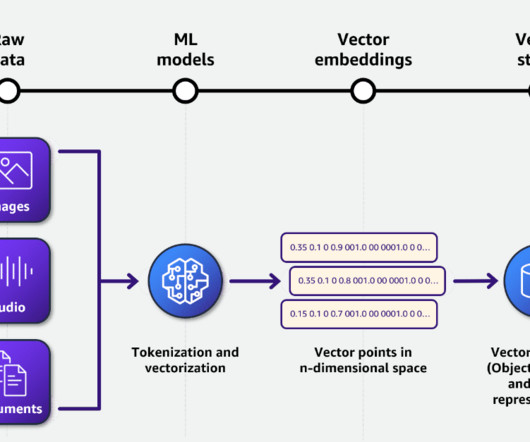
This begins the process of converting the data stored in the S3 bucket into vector embeddings in your OpenSearch Serverless vector collection. Note: The syncing operation can take minutes to hours to complete, based on the size of the dataset stored in your S3 bucket.
As an MLOps engineer on your team, you are often tasked with improving the workflow of your data scientists by adding capabilities to your ML platform or by building standalone tools for them to use. And since you are reading this article, the data scientists you support have probably reached out for help.
Managing unstructured data is essential for the success of machine learning (ML) projects. Without structure, data is difficult to analyze and extracting meaningful insights and patterns is challenging. This article will discuss managing unstructured data for AI and ML projects. What is Unstructured Data?
Now, to download Mixtral, you must login into your account using an access token: huggingface-cli login --token YOUR_TOKEN We then need access to an IAM Role with the required permissions for Sagemaker. After finishing it, we can acces the model using from_pretrained method from transformers library. You can find here more about it.
If you will ask data professionals about what is the most challenging part of their day to day work, you will likely discover their concerns around managing different aspects of data before they get to graduate to the datamodeling stage. You can learn more about the benefits of having a data pipeline in place here.
The machine learning (ML) lifecycle defines steps to derive values to meet business objectives using ML and artificial intelligence (AI). Here are some details about these packages: jupyterlab is for model building and data exploration. catboost is the machine learning algorithm for model building. Flask==2.1.2
Why Migrate to a Modern Data Stack? Data teams can focus on delivering higher-value data tasks with better organizational visibility. Move Beyond One-off Analytics: The Modern Data Stack empowers you to elevate your data for advanced analytics and integration of AI/ML, enabling faster generation of actionable business insights.
Then can download the neuron model and tokenizer config files from the above step and store them in the model directory, e.g script by overwriting the model_fn to load our neuron model and the predict_fn to create a text-classification pipeline. ! into the code/ directory of the model directory. ! copy inference.py
Embedding is usually performed by a machine learning (ML) model. The language model then generates a SQL query that incorporates the enterprise knowledge. Streamlit This open source Python library makes it straightforward to create and share beautiful, custom web apps for ML and data science. streamlit run app.py
Although QLoRA reduces computational requirements and memory footprint, FSDP, a data/model parallelism technique, will help shard the model across all eight GPUs (one ml.p4d.24xlarge 24xlarge ), enabling training the model even more efficiently. Nishant Karve is a Sr.
Download the notebook file to use in this post. data # Assing local directory path to a python variable local_data_path = "./data/" data/" # Assign S3 bucket name to a python variable. . This enables you to use Aurora for generative AI RAG-based use cases by storing vectors with the rest of the data.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






























Let's personalize your content