This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
What if you could automatically shard your PostgreSQL database across any number of servers and get industry-leading performance at scale without any special datamodelling steps? If you skip one of these steps, performance might be poor due to network overhead, or you might run into distributed SQL limitations.
With the enhancements to View Data, you can remove and add fields as well as adjust the number of rows to cover the breadth and depth that your analysis needs. Once you have achieved your desired data configuration, you can download the data as a CSV in your customized layout. . Easily swap root tables in your datamodel.
With the enhancements to View Data, you can remove and add fields as well as adjust the number of rows to cover the breadth and depth that your analysis needs. Once you have achieved your desired data configuration, you can download the data as a CSV in your customized layout. . Easily swap root tables in your datamodel.
In addition to versioning code, teams can also version data, models, experiments and more. Released in 2022, DagsHub’s Direct Data Access (DDA for short) allows Data Scientists and Machine Learning engineers to stream files from DagsHub repository without needing to download them to their local environment ahead of time.
Just click this button and fill out the form to download it. The June 2021 release of Power BI Desktop introduced Custom SQL queries to Snowflake in DirectQuery mode. In 2021, Microsoft enabled Custom SQL queries to be run to Snowflake in DirectQuery mode further enhancing the connection capabilities between the platforms.
MLOps cover all of the rest, how to track your experiments, how to share your work, how to version your models etc (Full list in the previous post. ). Also same expertise rule applies for an ML engineer, the more versed you are in MLOps the better you can foresee issues, fix data/model bugs and be a valued team member.
You can also transform Facebook Ads or AdWords spend data into a consistent format and keep the data segregated. You can generate SQL code to unite two relations and create surrogate keys or pivot columns. Use it to download various dbt packages into your own dbt project. Use it to reference a private package.
Select the uploaded file and from Actions dropdown and choose the Query with S3 Select option to query the.csv data using SQL if the data was loaded correctly. In this demonstration, let’s assume that you need to remove the data related to a particular customer.
CreateImportDatasetStateMachine – Imports source data from Amazon S3 into a dataset group for training. AthenaConnectorStateMachine – Enables you to write SQL queries with the Amazon Athena connector to land data in Amazon S3. You should see the data imports in progress. Choose View datasets.
We document these custom models in Alation Data Catalog and publish common queries that other teams can use for operational use cases or reporting needs. Contact title mappings, which are buiilt in some of datamodels, are documented within our data catalog. Jason: How do you use these models?
A key finding of the survey is that the ability to find data contributes greatly to the success of BI initiatives. In the study, 75% of the 770 survey respondents indicated having difficulty in locating and accessing analytic content including data, models, and metadata. Subscribe to Alation's Blog.
If you will ask data professionals about what is the most challenging part of their day to day work, you will likely discover their concerns around managing different aspects of data before they get to graduate to the datamodeling stage. Uses secure protocols for data security. Cons Limited connectors.
Advanced Analytics: Snowflake’s platform is purposefully engineered to cater to the demands of machine learning and AI-driven data science applications in a cost-effective manner. Enterprises can effortlessly prepare data and construct ML models without the burden of complex integrations while maintaining the highest level of security.
Model versioning, lineage, and packaging : Can you version and reproduce models and experiments? Can you see the complete model lineage with data/models/experiments used downstream? Soda Core Soda Core is an open-source data quality management framework for SQL, Spark, and Pandas-accessible data.
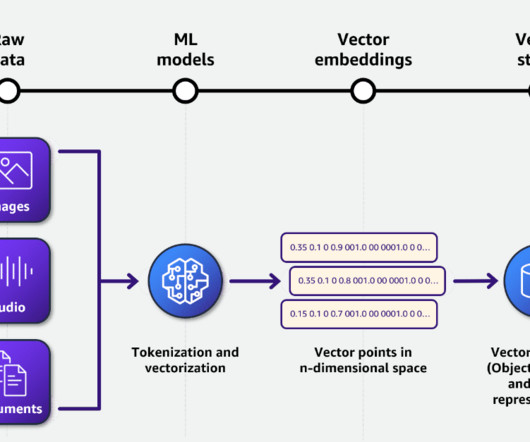
Here’s the structured equivalent of this same data in tabular form: With structured data, you can use query languages like SQL to extract and interpret information. In contrast, such traditional query languages struggle to interpret unstructured data. This text has a lot of information, but it is not structured.
SQL is one of the key languages widely used across businesses, and it requires an understanding of databases and table metadata. This can be overwhelming for nontechnical users who lack proficiency in SQL. This application allows users to ask questions in natural language and then generates a SQL query for the users request.
They are responsible for the design, build, and maintenance of the data infrastructure that powers the analytics platform. In this blog, we will cover the essentials around how to connect to popular data connections in ThoughtSpot, datamodeling, and setting up your business users for success.
You should have at least Contributor access to the workspace DownloadSQL Server Management Studio Step-by-Step Guide for Refreshing a Single Table in Power BI Semantic Model Using a demo datamodel, let’s walk through how to refresh a single table in a Power BI semantic model.
Download the notebook file to use in this post. data # Assing local directory path to a python variable local_data_path = "./data/" data/" # Assign S3 bucket name to a python variable. . This will open a new browser tab for SageMaker Studio Classic. Run the SageMaker Studio application. JupyterLab will open in a new tab.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.























Let's personalize your content