
5 Free Platforms to Collaborate on Machine Learning Projects
Machine Learning Mastery
JUNE 10, 2024
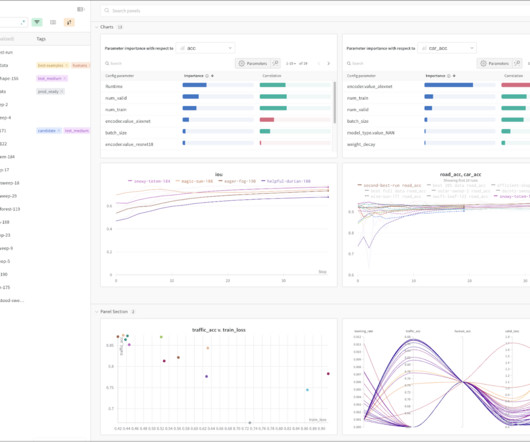
Collaborating on a machine learning project is a bit different from collaborating on a traditional software project. In a machine learning project, engineers are working with data, models, and source code. Additionally, they are also sharing features, model experiment results, and pipelines.









































Let's personalize your content