This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Continuous Integration and Continuous Delivery (CI/CD) for DataPipelines: It is a Game-Changer with AnalyticsCreator! The need for efficient and reliable datapipelines is paramount in data science and data engineering. They transform data into a consistent format for users to consume.
Data engineering tools are software applications or frameworks specifically designed to facilitate the process of managing, processing, and transforming large volumes of data. Spark offers a rich set of libraries for data processing, machine learning, graph processing, and stream processing.
In part one of this article, we discussed how data testing can specifically test a data object (e.g., table, column, metadata) at one particular point in the datapipeline.
Data engineering is a crucial field that plays a vital role in the datapipeline of any organization. It is the process of collecting, storing, managing, and analyzing large amounts of data, and data engineers are responsible for designing and implementing the systems and infrastructure that make this possible.
If you will ask data professionals about what is the most challenging part of their day to day work, you will likely discover their concerns around managing different aspects of data before they get to graduate to the datamodeling stage. This ensures that the data is accurate, consistent, and reliable.
Summary: The fundamentals of Data Engineering encompass essential practices like datamodelling, warehousing, pipelines, and integration. Understanding these concepts enables professionals to build robust systems that facilitate effective data management and insightful analysis. What is Data Engineering?
MongoDB for end-to-end AI data management MongoDB Atlas , an integrated suite of data services centered around a multi-cloud NoSQL database, enables developers to unify operational, analytical, and AI data services to streamline building AI-enriched applications.
The 4 Gen AI Architecture Pipelines The four pipelines are: 1. The DataPipeline The datapipeline is the foundation of any AI system. It's responsible for collecting and ingesting the data from various external sources, processing it and managing the data.
Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. They create datapipelines, ETL processes, and databases to facilitate smooth data flow and storage. Big Data Processing: Apache Hadoop, Apache Spark, etc.
Every company today is being asked to do more with less, and leaders need access to fresh, trusted KPIs and data-driven insights to manage their businesses, keep ahead of the competition, and provide unparalleled customer experiences. . But good data—and actionable insights—are hard to get. The power of the customer graph keeps going.
Every company today is being asked to do more with less, and leaders need access to fresh, trusted KPIs and data-driven insights to manage their businesses, keep ahead of the competition, and provide unparalleled customer experiences. . But good data—and actionable insights—are hard to get. The power of the customer graph keeps going.
Leveraging Looker’s semantic layer will provide Tableau customers with trusted, governed data at every stage of their analytics journey. With its LookML modeling language, Looker provides a unique, modern approach to define governed and reusable datamodels to build a trusted foundation for analytics.
Elementl / Dagster Labs Elementl and Dagster Labs are both companies that provide platforms for building and managing datapipelines. Elementl’s platform is designed for data engineers, while Dagster Labs’ platform is designed for data scientists. However, there are some critical differences between the two companies.
In order to fully leverage this vast quantity of collected data, companies need a robust and scalable data infrastructure to manage it. This is where Fivetran and the Modern Data Stack come in. Snowflake Data Cloud Replication Transferring data from a source system to a cloud data warehouse.
Model versioning, lineage, and packaging : Can you version and reproduce models and experiments? Can you see the complete model lineage with data/models/experiments used downstream? It could help you detect and prevent datapipeline failures, data drift, and anomalies.
It brings together business users, data scientists , data analysts, IT, and application developers to fulfill the business need for insights. DataOps then works to continuously improve and adjust datamodels, visualizations, reports, and dashboards to achieve business goals. The Agile Connection.
That said, dbt provides the ability to generate data vault models and also allows you to write your data transformations using SQL and code-reusable macros powered by Jinja2 to run your datapipelines in a clean and efficient way. The most important reason for using DBT in Data Vault 2.0
Managing datapipelines efficiently is paramount for any organization. The Snowflake Data Cloud has introduced a groundbreaking feature that promises to simplify and supercharge this process: Snowflake Dynamic Tables. What are Snowflake Dynamic Tables?
Because of the types of databases that made their way into adoption during the nascent days of Big Data, we now have the problem of streamlining databases running on Hive or NoSQL that were never meant to process data sets as large as what our data lake holds. The Third Problem – Preparation of Data.
In today’s landscape, AI is becoming a major focus in developing and deploying machine learning models. It isn’t just about writing code or creating algorithms — it requires robust pipelines that handle data, model training, deployment, and maintenance. Model Training: Running computations to learn from the data.
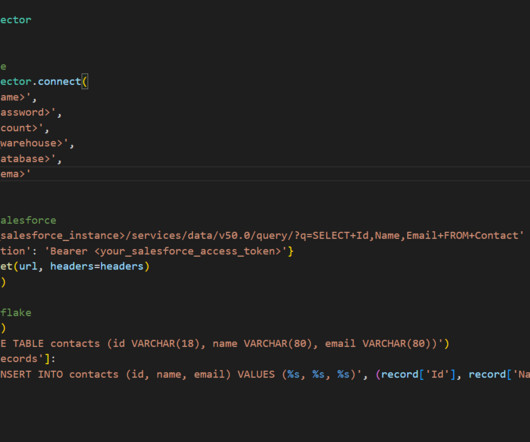
Third-Party Tools Third-party tools like Matillion or Fivetran can help streamline the process of ingesting Salesforce data into Snowflake. With these tools, businesses can quickly set up datapipelines that automatically extract data from Salesforce and load it into Snowflake.
Model Your Data Appropriately Once you have chosen the method to connect to your data (Import, DirectQuery, Composite), you will need to make sure that you create an efficient and optimized datamodel. Here are some of our best practices for building datamodels in Power BI to optimize your Snowflake experience: 1.
It simplifies feature access for model training and inference, significantly reducing the time and complexity involved in managing datapipelines. Additionally, Feast promotes feature reuse, so the time spent on data preparation is reduced greatly.
DagsHub is a centralized platform to host and manage machine learning projects, including code, data, models, experiments, annotations, model registry, and more! Intermediate DataPipeline : Build datapipelines using DVC for automation and versioning of Open Source Machine Learning projects.
By analyzing datasets, data scientists can better understand their potential use in an algorithm or machine learning model. The data science lifecycle Data science is iterative, meaning data scientists form hypotheses and experiment to see if a desired outcome can be achieved using available data.
Production App - Build resilient and modular production pipelines with automation, scale, testing, observability, versioning, security, risk handling, etc. Monitoring - Monitor all resources, data, model and application metrics to ensure performance. This helps cleanse the data.
Machine Learning projects evolve rapidly, frequently introducing new data , models, and hyperparameters. Use Cases in ML Workflows Hydra excels in scenarios requiring frequent parameter tuning, such as hyperparameter optimisation, multi-environment testing, and orchestrating pipelines.
Leveraging Looker’s semantic layer will provide Tableau customers with trusted, governed data at every stage of their analytics journey. With its LookML modeling language, Looker provides a unique, modern approach to define governed and reusable datamodels to build a trusted foundation for analytics.
It is the process of converting raw data into relevant and practical knowledge to help evaluate the performance of businesses, discover trends, and make well-informed choices. Data gathering, data integration, datamodelling, analysis of information, and data visualization are all part of intelligence for businesses.
DataModeling, dbt has gradually emerged as a powerful tool that largely simplifies the process of building and handling datapipelines. dbt is an open-source command-line tool that allows data engineers to transform, test, and document the data into one single hub which follows the best practices of software engineering.
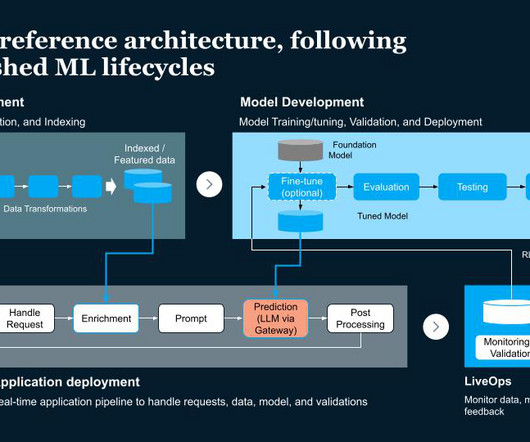
This includes management vision and strategy, resource commitment, data and tech and operating model alignment, robust risk management and change management. The required architecture includes a datapipeline, ML pipeline, application pipeline and a multi-stage pipeline. Read more here.
Generative AI can be used to automate the datamodeling process by generating entity-relationship diagrams or other types of datamodels and assist in UI design process by generating wireframes or high-fidelity mockups. GPT-4 DataPipelines: Transform JSON to SQL Schema Instantly Blockstream’s public Bitcoin API.
Data Engineering Career: Unleashing The True Potential of Data Problem-Solving Skills Data Engineers are required to possess strong analytical and problem-solving skills to navigate complex data challenges. Understanding these fundamentals is essential for effective problem-solving in data engineering.
IBM Infosphere DataStage IBM Infosphere DataStage is an enterprise-level ETL tool that enables users to design, develop, and run datapipelines. Key Features: Graphical Framework: Allows users to design datapipelines with ease using a graphical user interface. Read Further: Azure Data Engineer Jobs.
It includes processes that trace and document the origin of data, models and associated metadata and pipelines for audits. A data store lets a business connect existing data with new data and discover new insights with real-time analytics and business intelligence.
Many mistakenly equate tabular data with business intelligence rather than AI, leading to a dismissive attitude toward its sophistication. Standard data science practices could also be contributing to this issue. One might say that tabular datamodeling is the original data-centric AI!
Every company today is being asked to do more with less, and leaders need access to fresh, trusted KPIs and data-driven insights to manage their businesses, keep ahead of the competition, and provide unparalleled customer experiences. But good data—and actionable insights—are hard to get. What is Salesforce Data Cloud for Tableau?
I consciously chose to pivot away from general software development and specialize in Data Engineering. I’ve moved from building user interfaces and backend systems to designing datamodels, creating datapipelines, and gaining valuable insights from complex datasets.
DagsHub DagsHub is a centralized Github-based platform that allows Machine Learning and Data Science teams to build, manage and collaborate on their projects. In addition to versioning code, teams can also version data, models, experiments and more. It does not support the ‘dvc repro’ command to reproduce its datapipeline.
What does a modern data architecture do for your business? A modern data architecture like Data Mesh and Data Fabric aims to easily connect new data sources and accelerate development of use case specific datapipelines across on-premises, hybrid and multicloud environments.
The Data Source Tool can automate scanning DDL and profiling tables between source and target, comparing them, and then reporting findings. Aside from migrations, Data Source is also great for data quality checks and can generate datapipelines. But you still want to start building out the datamodel.
Companies at this stage will likely have a team of ML engineers dedicated to creating datapipelines, versioning data, and maintaining operations monitoring data, models & deployments. By now, data scientists have witnessed success optimizing internal operations and external offerings through AI.
With proper unstructured data management, you can write validation checks to detect multiple entries of the same data. Continuous learning: In a properly managed unstructured datapipeline, you can use new entries to train a production ML model, keeping the model up-to-date.
By maintaining historical data from disparate locations, a data warehouse creates a foundation for trend analysis and strategic decision-making. Microsoft Azure Synapse Analytics Microsoft Azure Synapse Analytics is an integrated analytics service that combines data warehousing and big data capabilities into a unified platform.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content