Testing and Monitoring Data Pipelines: Part Two
Dataversity
JUNE 19, 2023
In part one of this article, we discussed how data testing can specifically test a data object (e.g., table, column, metadata) at one particular point in the data pipeline.
 Data Models Data Pipeline Information
Data Models Data Pipeline Information 
Dataversity
JUNE 19, 2023
In part one of this article, we discussed how data testing can specifically test a data object (e.g., table, column, metadata) at one particular point in the data pipeline.

Data Science Connect
JANUARY 27, 2023
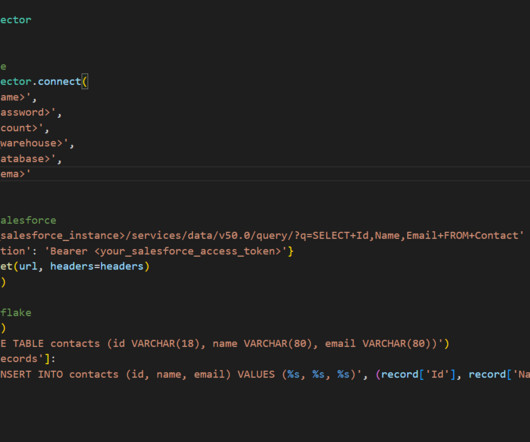
Data engineering is a crucial field that plays a vital role in the data pipeline of any organization. It is the process of collecting, storing, managing, and analyzing large amounts of data, and data engineers are responsible for designing and implementing the systems and infrastructure that make this possible.
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.
Iguazio
JULY 22, 2024
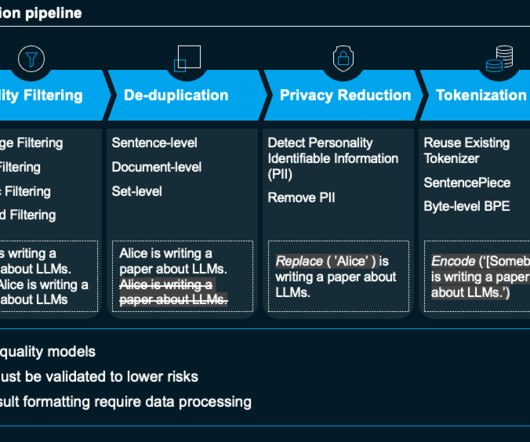
AI offers a transformative approach by automating the interpretation of regulations, supporting data cleansing, and enhancing the efficacy of surveillance systems. AI-powered systems can analyze transactions in real-time and flag suspicious activities more accurately, which helps institutions take informed actions to prevent financial losses.

Pickl AI
NOVEMBER 4, 2024
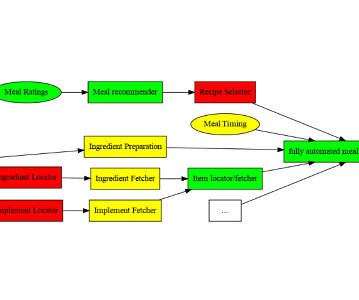
Summary: The fundamentals of Data Engineering encompass essential practices like data modelling, warehousing, pipelines, and integration. Understanding these concepts enables professionals to build robust systems that facilitate effective data management and insightful analysis. What is Data Engineering?

The MLOps Blog
MARCH 15, 2023
If you will ask data professionals about what is the most challenging part of their day to day work, you will likely discover their concerns around managing different aspects of data before they get to graduate to the data modeling stage. This ensures that the data is accurate, consistent, and reliable.

Tableau
DECEMBER 7, 2022
But good data—and actionable insights—are hard to get. Traditionally, organizations built complex data pipelines to replicate data. Those data architectures were brittle, complex, and time intensive to build and maintain, requiring data duplication and bloated data warehouse investments.

Tableau
DECEMBER 7, 2022
But good data—and actionable insights—are hard to get. Traditionally, organizations built complex data pipelines to replicate data. Those data architectures were brittle, complex, and time intensive to build and maintain, requiring data duplication and bloated data warehouse investments.

Expert insights. Personalized for you.







































Let's personalize your content