This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Tableau is a leader in the analytics market, known for helping organizations see and understand their data, but we recognize that gaps still exist: while many of our joint customers already benefit from dbt and trust the metrics that result from these workflows, they are often disconnected and obscured from Tableau’s analytics layer.
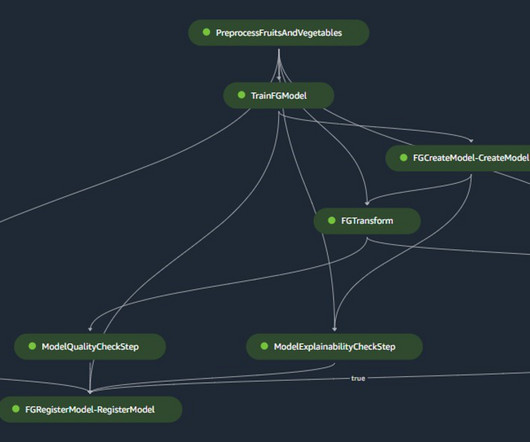
The SageMaker project template includes seed code corresponding to each step of the build and deploy pipelines (we discuss these steps in more detail later in this post) as well as the pipeline definition—the recipe for how the steps should be run. Workflow B corresponds to modelquality drift checks.
We’ve infused our values into our platform, which supports data fabric designs with a data management layer right inside our platform, helping you break down silos and streamline support for the entire data and analytics life cycle. . Analytics data catalog. Dataquality and lineage. Datamodeling.
We’ve infused our values into our platform, which supports data fabric designs with a data management layer right inside our platform, helping you break down silos and streamline support for the entire data and analytics life cycle. . Analytics data catalog. Dataquality and lineage. Datamodeling.
The practitioner asked me to add something to a presentation for his organization: the value of data governance for things other than data compliance and data security. Now to be honest, I immediately jumped onto dataquality. Dataquality is a very typical use case for data governance.
No single source of truth: There may be multiple versions or variations of similar data sets, but which is the trustworthy data set users should default to? Missing datadefinitions and formulas: People need to understand exactly what the data represents, in the context of the business, to use it effectively.
No single source of truth: There may be multiple versions or variations of similar data sets, but which is the trustworthy data set users should default to? Missing datadefinitions and formulas: People need to understand exactly what the data represents, in the context of the business, to use it effectively.
Additionally, Feast promotes feature reuse, so the time spent on data preparation is reduced greatly. It promotes a disciplined approach to datamodeling, making it easier to ensure dataquality and consistency across the ML pipelines. The following figure shows schema definition and model which reference it.
Access to high-qualitydata can help organizations start successful products, defend against digital attacks, understand failures and pivot toward success. Emerging technologies and trends, such as machine learning (ML), artificial intelligence (AI), automation and generative AI (gen AI), all rely on good dataquality.
Master Data Management (MDM) and data catalog growth are accelerating because organizations must integrate more systems, comply with privacy regulations, and address dataquality concerns. What Is Master Data Management (MDM)? Implementing a data catalog first will make MDM more successful.
Reichental describes data governance as the overarching layer that empowers people to manage data well ; as such, it is focused on roles & responsibilities, policies, definitions, metrics, and the lifecycle of the data. In this way, data governance is the business or process side. This is a very good thing.
According to a 2023 study from the LeBow College of Business , data enrichment and location intelligence figured prominently among executives’ top 5 priorities for data integrity. 53% of respondents cited missing information as a critical challenge impacting dataquality. What is data integrity?
Additionally, it addresses common challenges and offers practical solutions to ensure that fact tables are structured for optimal dataquality and analytical performance. Introduction In today’s data-driven landscape, organisations are increasingly reliant on Data Analytics to inform decision-making and drive business strategies.
They collaborate with IT professionals, business stakeholders, and data analysts to design effective data infrastructure aligned with the organization’s goals. Their broad range of responsibilities include: Design and implement data architecture. Maintain datamodels and documentation.
Understanding Data Lakes A data lake is a centralized repository that stores structured, semi-structured, and unstructured data in its raw format. Unlike traditional data warehouses or relational databases, data lakes accept data from a variety of sources, without the need for prior data transformation or schema definition.
Hierarchies align datamodelling with business processes, making it easier to analyse data in a context that reflects real-world operations. Designing Hierarchies Designing effective hierarchies requires careful consideration of the business requirements and the datamodel.
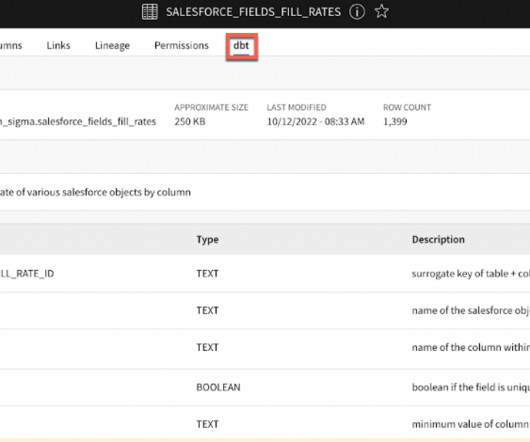
Now that your data is loaded in using dbt, one can see the data displayed in Sigma itself, allowing the user to verify how up-to-date their data is. DataQuality View dbt quality tests on columns and models, providing precision and transparency into your dataquality questions and concerns – What a relief.
They offer a focused selection of data, allowing for faster analysis tailored to departmental goals. Metadata This acts like the data dictionary, providing crucial information about the data itself. Metadata details the source of the data, its definition, and how it relates to other data points within the warehouse.
Top contenders like Apache Airflow and AWS Glue offer unique features, empowering businesses with efficient workflows, high dataquality, and informed decision-making capabilities. Introduction In today’s business landscape, data integration is vital. More For You To Read: 10 DataModeling Tools You Should Know.
Data governance and security Like a fortress protecting its treasures, data governance, and security form the stronghold of practical Data Intelligence. Think of data governance as the rules and regulations governing the kingdom of information. It ensures dataquality , integrity, and compliance.
A truly governed self-service analytics model puts datamodeling responsibilities in the hands of IT and report generation and analysis in the hands of business users who will actually be doing the analysis. Business users build reports on an IT-owned and IT-created datamodel that is focused on reporting solutions.
Data should be designed to be easily accessed, discovered, and consumed by other teams or users without requiring significant support or intervention from the team that created it. Data should be created using standardized datamodels, definitions, and quality requirements. What is Data Mesh?
In this blog, we have covered Data Management and its examples along with its benefits. What is Data Management? Before delving deeper into the process of Data Management and its significance, let’s scratch the surface of the Data Management definition.
The capabilities of Lake Formation simplify securing and managing distributed data lakes across multiple accounts through a centralized approach, providing fine-grained access control. Solution overview We demonstrate this solution with an end-to-end use case using a sample dataset, the TPC datamodel. compute.internal.
By combining data from disparate systems, HCLS companies can perform better data analysis and make more informed decisions. See how phData created a solution for ingesting and interpreting HL7 data 4. DataQuality Inaccurate data can have negative impacts on patient interactions or loss of productivity for the business.
Sidebar Navigation: Provides a catalog sidebar for browsing resources by type, package, file tree, or database schema, reflecting the structure of both dbt projects and the data platform. Version Tracking: Displays version information for models, indicating whether they are prerelease, latest, or outdated.
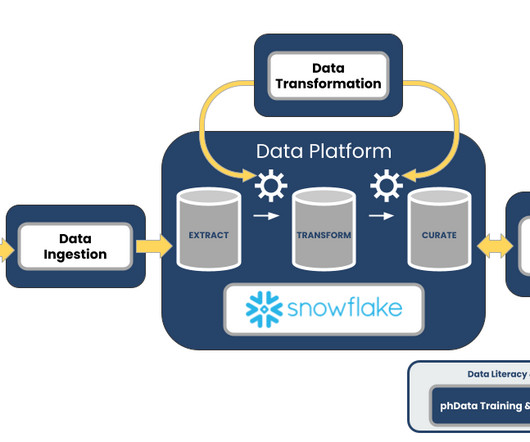
Enter dbt dbt provides SQL-centric transformations for your datamodeling and transformations, which is efficient for scrubbing and transforming your data while being an easy skill set to hire for and develop within your teams. It should also enable easy sharing of insights across the organization. Read more here.
Here are some challenges you might face while managing unstructured data: Storage consumption: Unstructured data can consume a large volume of storage. For instance, if you are working with several high-definition videos, storing them would take a lot of storage space, which could be costly.
GP has intrinsic advantages in datamodeling, given its construction in the framework of Bayesian hierarchical modeling and no requirement for a priori information of function forms in Bayesian reference. Taking things step by step here is crucial for smooth, high-quality predictive time modeling and resulting forecasting.
For example, GDPR requires your organization to collect and keep track of metadata about the datasets and to document and report how the resulting model(s) from experiments work. You don’t want to end up in a situation where you need to rewrite a system due to some shortcuts you took early on when only one data scientist was using it.
Introduction: The Customer DataModeling Dilemma You know, that thing we’ve been doing for years, trying to capture the essence of our customers in neat little profile boxes? For years, we’ve been obsessed with creating these grand, top-down customer datamodels. Yeah, that one.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



































Let's personalize your content