This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Feature engineering: Creating informative features can help improve model performance and reduce overfitting. Technical Skills Implement a simple linear regression model from scratch. Python Explain the steps involved in training a decisiontree.
Data Sourcing. Fundamental to any aspect of data science, it’s difficult to develop accurate predictions or craft a decisiontree if you’re garnering insights from inadequate data sources. Objectives and Usage.
Machine Learning models play a crucial role in this process, serving as the backbone for various applications, from image recognition to natural language processing. In this blog, we will delve into the fundamental concepts of datamodel for Machine Learning, exploring their types. What is Machine Learning?
Using different machine learning algorithms for performance optimization: Several machine learning algorithms can be used for performance optimization, including regression, clustering, and decisiontrees. Decisiontree algorithms can be used to identify performance bottlenecks and suggest optimization strategies.
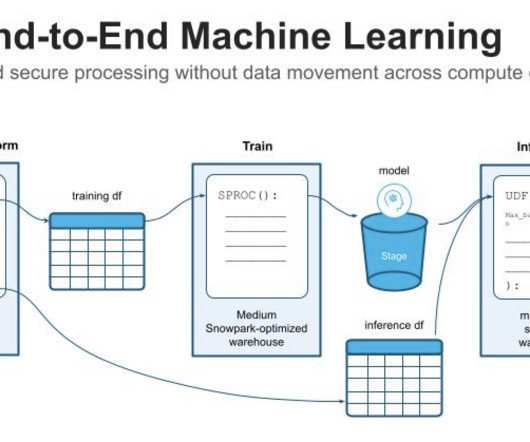
In today’s landscape, AI is becoming a major focus in developing and deploying machine learning models. It isn’t just about writing code or creating algorithms — it requires robust pipelines that handle data, model training, deployment, and maintenance. Model Training: Running computations to learn from the data.
Significantly, Supervised Learning is practical in two types of tasks- Classification: the goal is to predict a categorical label for each input data point Regression: the goal is to predict a continuous value. It includes various algorithms like linear regression, logistic regression, decisiontrees, bayesian logic, etc.
It constructs a hyperplane to separate different classes during training and uses it to make predictions on new data. DecisionTrees : DecisionTrees are another example of Eager Learning algorithms that recursively split the data based on feature values during training to create a tree-like structure for prediction.
With a modeled estimation of the applicant’s credit risk, lenders can make more informed decisions and reduce the occurrence of bad loans, thereby protecting their bottom line. The model learns from these labels to predict the outcome of new, unseen data. loan default or not).
GP has intrinsic advantages in datamodeling, given its construction in the framework of Bayesian hierarchical modeling and no requirement for a priori information of function forms in Bayesian reference. DecisionTrees ML-based decisiontrees are used to classify items (products) in the database.
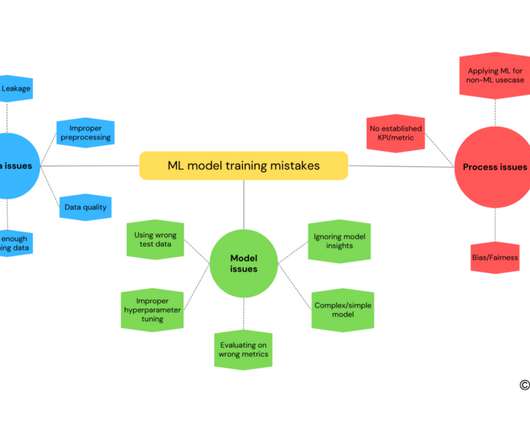
Metrics for ML — Not looking at the model — Explaining a ML model can help in understanding how it works and makes predictions. Techniques such as feature importance and decisiontrees can help you gain insights into the inner workings of a model.
Hyperparameter Tuning Hyperparameters are configuration settings that are external to the model and whose values cannot estimate from the data. They control the learning process of the model and can significantly impact its performance. Train the Model: Fit the model to the training data.
It uses advanced tools to look at raw data, gather a data set, process it, and develop insights to create meaning. Areas making up the data science field include mining, statistics, data analytics, datamodeling, machine learning modeling and programming.
FREE: Managing fraud The ultimate guide to fraud detection, investigation and prevention using data visualization GET YOUR FREE GUIDE The role of new & existing technology For many years, credit card companies have relied on analytics, algorithms and decisiontrees to power their fraud strategy.
AutoGluon is easy-to-use AutoML tool that uses automatic data processing, hyperparameter tuning, and model ensemble. The best baseline was achieved with a weighted ensemble of gradient boosted decisiontreemodels. His interest includes generative models and sequential datamodeling.
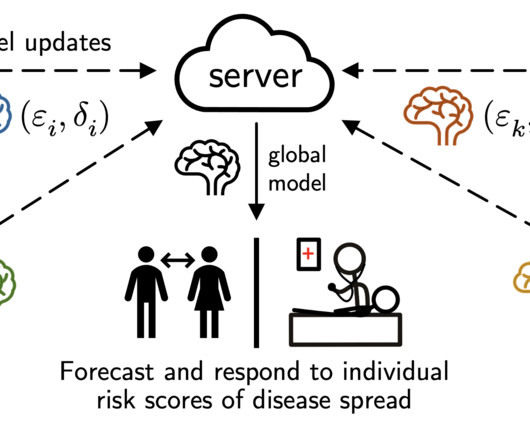
This is certainly not perfect as it ignores population-level modeling (e.g. denser areas have higher risks of infection), but it makes the ML problem very simple: just plug-in existing tabular datamodeling approaches! Scalable, private, and federated trees for tabular data.
Ensure the data is cleaned, formatted, and free from inconsistencies, as accurate predictions heavily depend on the quality of input data. Model Selection and Evaluation Experiment with different Machine Learning algorithms for stock price prediction, such as linear regression, decisiontrees , random forests, and neural networks.
For example, an experiment name like 'ResNet50-augmented-imagenet-exp-01' provides more information about the model architecture, dataset, and experiment number. DVC Data Version Control (DVC) is an open-source version control system that is specially designed to track not just code, but also data, models, and machine learning pipelines.
DecisionTrees These trees split data into branches based on feature values, providing clear decision rules. Model Evaluation and Tuning After building a Machine Learning model, it is crucial to evaluate its performance to ensure it generalises well to new, unseen data.
DataModeling: Developing predictive models using machine learning algorithms like regression, decisiontrees, and neural networks. Data Cleansing: Ensuring data quality and removing outliers to improve model accuracy. Key Features: i.
Hybrid machine learning techniques excel in model selection by amalgamating the strengths of multiple models. By combining, for example, a decisiontree with a support vector machine (SVM), these hybrid models leverage the interpretability of decisiontrees and the robustness of SVMs to yield superior predictions in medicine.
Scikit-learn provides a consistent API for training and using machine learning models, making it easy to experiment with different algorithms and techniques. It also provides tools for model evaluation , including cross-validation, hyperparameter tuning, and metrics such as accuracy, precision, recall, and F1-score.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.























Let's personalize your content