This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
By Nate Rosidi , KDnuggets Market Trends & SQL Content Specialist on June 11, 2025 in Language Models Image by Author | Canva If you work in a data-related field, you should update yourself regularly. Data scientists use different tools for tasks like data visualization, datamodeling, and even warehouse systems.
Events Data + AI Summit Data + AI World Tour Data Intelligence Days Event Calendar Blog and Podcasts Databricks Blog Explore news, product announcements, and more Databricks Mosaic Research Blog Discover the latest in our Gen AI research Data Brew Podcast Let’s talk data!
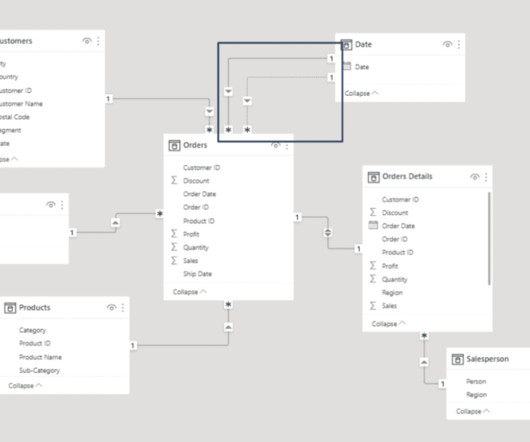
While the front-end report visuals are important and the most visible to end users, a lot goes on behind the scenes that contribute heavily to the end product, including datamodeling. In this blog, we’ll describe datamodeling and its significance in Power BI. What is DataModeling?
By narrowing down the search space to the most relevant documents or chunks, metadata filtering reduces noise and irrelevant information, enabling the LLM to focus on the most relevant content. By combining the capabilities of LLM function calling and Pydantic datamodels, you can dynamically extract metadata from user queries.
In the first post of this three-part series, we presented a solution that demonstrates how you can automate detecting document tampering and fraud at scale using AWS AI and machine learning (ML) services for a mortgage underwriting use case. The following diagram represents each stage in a mortgage document fraud detection pipeline.
Essential skills of a data steward To fulfill their responsibilities effectively, data stewards should possess a blend of technical and interpersonal skills: Technical expertise: Knowledge of programming and datamodeling is crucial. Regulatory compliance: Ensures adherence to data regulations, minimizing legal risks.
In contrast, unstructured data, such as text documents or images, lacks this formal structure, while semi-structured data sits somewhere in between, containing both organized elements and free-form content. These frameworks facilitate the organization and integrity of data across various applications.
Applications of UMAP Modern machine learning workloads demand high performance where repetitive training and hyper-parameter optimization cycles are essential for exploring high-dimensional data, model tuning, and improving model accuracy.
One of the key considerations while designing the chat assistant was to avoid responses from the default large language model (LLM) trained on generic data and only use the insurance policy documents. The policy documents contain the insurance policy information that needs to be ingested into the knowledge base.
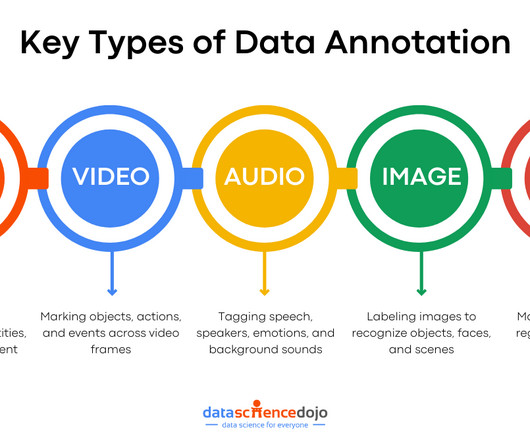
Below are a few reasons that make data annotation a critical component for language models. Improving Model Accuracy Since annotation helps LLMs make sense of words, it makes a model’s outputs more accurate. Without the use of annotated data, models can confuse similar words or misinterpret intent.
This capability enhances responses from generative AI applications by automatically creating embeddings for semantic search and generating a graph of the entities and relationships extracted from ingested documents. Without effectively mapping shared context across input data sources, responses risk being incomplete and inaccurate.
Data is driving most business decisions. In this, datamodeling tools play a crucial role in developing and maintaining the information system. Moreover, it involves the creation of a conceptual representation of data and its relationship. Datamodeling tools play a significant role in this.
This makes it ideal for high-performance use cases like real-time chat applications or APIs for machine learning models. Figure 3: FastAPI vs Django: Async capabilities | by Nanda Gopal Pattanayak | Medium Automatic Interactive API Documentation Out of the box, FastAPI generates Swagger UI and ReDoc documentation for all API endpoints.
In the contemporary business environment, the integration of datamodeling and business structure is not only advantageous but crucial. This dynamic pair of documents serves as the foundation for strategic decision-making, providing organizations with a distinct pathway toward success.
ArangoDB is a multi-model database designed for modern applications, combining graph, document, key/value, and full-text search capabilities. Key features include ArangoGraph Cloud for scalable deployment, ArangoDB Visualizer for data navigation, and ArangoGraphML for machine learning applications.
Big data architecture lays out the technical specifics of processing and analyzing larger amounts of data than traditional database systems can handle. According to the Microsoft documentation page, big data usually helps business intelligence with many objectives. How to Find a Quality Translation Company.
Key features of cloud analytics solutions include: Datamodels , Processing applications, and Analytics models. Datamodels help visualize and organize data, processing applications handle large datasets efficiently, and analytics models aid in understanding complex data sets, laying the foundation for business intelligence.
I’ve found that while calculating automation benefits like time savings is relatively straightforward, users struggle to estimate the value of insights, especially when dealing with previously unavailable data. We were developing a datamodel to provide deeper insights into logistics contracts.
However, to fully harness the potential of a data lake, effective datamodeling methodologies and processes are crucial. Datamodeling plays a pivotal role in defining the structure, relationships, and semantics of data within a data lake. Consistency of data throughout the data lake.
NoSQL databases became possible fairly recently, in the late 2000s, all thanks to the decrease in the price of data storage. Just like that, the need for complex and difficult-to-manage datamodels has dissipated to give way to better developer productivity. The four main types are: Document databases. Flexible schemas.
For instance, creating use cases require meticulous planning and documentation, often involving multiple stakeholders and iterations. Designing datamodels and generating Entity-Relationship Diagrams (ERDs) demand significant effort and expertise. In summary, traditional SDLC can be riddled with inefficiencies.
When a customer has a production-ready intelligent document processing (IDP) workload, we often receive requests for a Well-Architected review. To follow along with this post, you should be familiar with the previous posts in this series ( Part 1 and Part 2 ) and the guidelines in Guidance for Intelligent Document Processing on AWS.
Database standards are common practices and procedures that are documented and […]. Rigidly adhering to a standard, any standard, without being reasonable and using your ability to think through changing situations and circumstances is itself a bad standard.
You can now register machine learning (ML) models in Amazon SageMaker Model Registry with Amazon SageMaker Model Cards , making it straightforward to manage governance information for specific model versions directly in SageMaker Model Registry in just a few clicks. Also, you can update the model’s deploy status.
This ensures that the datamodels and queries developed by data professionals are consistent with the underlying infrastructure. Enhanced Security and Compliance Data Warehouses often store sensitive information, making security a paramount concern. IaC allows these teams to collaborate more effectively.
Many organizations have mapped out the systems and applications of their data landscape. Many have documented their most critical business processes. Many have modeled their data domains and key attributes. But only very few have succeeded in connecting the knowledge of these three efforts.
Researchers from many universities build open-source projects which contribute to the development of the Data Science domain. It is also called the second brain as it can store data that is not arranged according to a present datamodel or schema and, therefore, cannot be stored in a traditional relational database or RDBMS.
You can find instructions on how to do this in the AWS documentation for your chosen SDK. AWS credentials – Configure your AWS credentials in your development environment to authenticate with AWS services. We walk through a Python example in this post.
Make sure you’re updating the datamodel ( updateTrackListData function) to handle your custom fields. documentation. community provides excellent documentation and support for implementing additional features. . // Example: Adding a custom dropdown for speaker identification var speakerDropdown = $(' ').attr({
What Are Their Ranges of DataModels? MongoDB has a wider range of datatypes than DynamoDB, even though both databases can store binary data. DynamoDB is limited to 400KB for documents and MongoDB can support up to 16MB file sizes. It is compatible with a laptop to mainframe and on-premise through a hybrid cloud.
Based on our experience from proof-of-concept (PoC) projects with clients, here are the best ways to leverage generative AI in the data layer: Understanding vendor data : Generative AI can process extensive vendor documentation to extract critical information about individual parameters.
Cassandra excels in high write throughput and availability, while MongoDB offers flexible document storage and powerful querying capabilities. Both databases are designed to handle large volumes of data, but they cater to different use cases and exhibit distinct architectural designs. What is Apache Cassandra? What is MongoDB?
MongoDB for end-to-end AI data management MongoDB Atlas , an integrated suite of data services centered around a multi-cloud NoSQL database, enables developers to unify operational, analytical, and AI data services to streamline building AI-enriched applications. Atlas Vector Search lets you search unstructured data.
This datamodel is well-suited for financial transactions, inventory, ticketing, or utility metering. To make that single node as fast as possible, TigerBeetle makes extensive use of batching, IO parallelization, a fixed schema, and hardware-friendly optimizationsâsuch as fixed-size, cache-aligned data structures.
Unstructured data is information that doesn’t conform to a predefined schema or isn’t organized according to a preset datamodel. Text, images, audio, and videos are common examples of unstructured data. Amazon Textract – You can use this ML service to extract metadata from scanned documents and images.
My approach to graph-based Retrieval Augmented Generation The approach is a bit more rooted in traditional methods, I parse the DataModel (an SQL-based relational system) into Nodes and Relationships in a graph database and then provide an endpoint where those relationships can be queried to provide a source of truth.
Additionally, Feast promotes feature reuse, so the time spent on data preparation is reduced greatly. It promotes a disciplined approach to datamodeling, making it easier to ensure data quality and consistency across the ML pipelines.
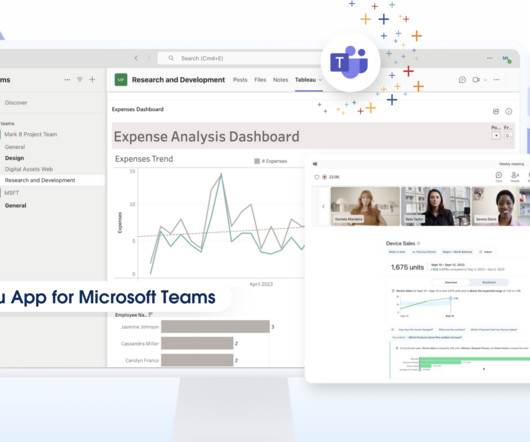
And with Tableau’s centralized permissions and datamodels, the app streamlines your data access and management by eliminating the need to replicate permission requests. Please refer to our detailed GitHub documentation for step-by-step guidance on setting up the app for Tableau Server. September 23, 2024
Claims adjusters pour hours into reviewing claims documents, verifying information, coordinating with customers, and making decisions about payments. AI can expedite tasks like data entry , document review , trend forecasting, and fraud detection. Claims data is often noisy, unstructured, and multi-modal.
These formats play a significant role in how data is processed, analyzed, and used to develop AI models. Structured data is organized in a highly organized and predefined manner. It follows a clear datamodel, where each data entry has specific fields and attributes with well-defined data types.
For example, in the following figure, we attached a 10K document from Amazon.com and asked a specific question about the cost of sales. Choose the router metrics icon (next to the refresh icon) to see which model the request was routed to. His interest includes generative models and sequential datamodeling.
Claims adjusters pour hours into reviewing claims documents, verifying information, coordinating with customers, and making decisions about payments. AI can expedite tasks like data entry , document review , trend forecasting, and fraud detection. Claims data is often noisy, unstructured, and multi-modal.
Document Databases Document databases organize data in the form of documents instead of rows and columns. These databases are intended to accommodate unstructured data like texts, images, and videos. with each document representing a file and each folder symbolizing a group of files. Document DBs 3.
Leverage dbt’s `test` macros within your models and add constraints to ensure data integrity between data vault entities. Maintain lineage and documentation: Data Vault emphasizes documenting the data lineage and providing clear documentation for each model.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content