This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This lesson is the 1st of a 2-part series on Deploying Machine Learning using FastAPI and Docker: Getting Started with Python and FastAPI: A Complete Beginners Guide (this tutorial) Lesson 2 To learn how to set up FastAPI, create GET and POST endpoints, validate data with Pydantic, and test your API with TestClient, just keep reading.
For example, you can give users access permission to download popular packages and customize the development environment. However, this can also introduce potential risks of unauthorized access to your data. AWS CodeArtifact , which provides a private PyPI repository so that SageMaker can use it to download necessary packages.
However, many companies are struggling to figure out how to use data visualization effectively. One of the ways to accomplish this is with presentation templates that can use datamodeling. Taking Advantage of Data Visualization with Presentation Templates. Keep reading to learn more.
Researchers from many universities build open-source projects which contribute to the development of the Data Science domain. It is also called the second brain as it can store data that is not arranged according to a present datamodel or schema and, therefore, cannot be stored in a traditional relational database or RDBMS.
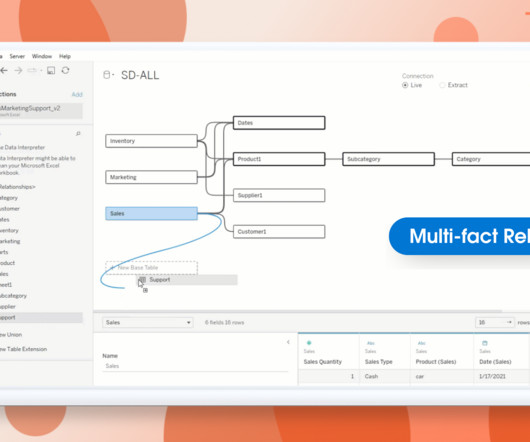
Spencer Czapiewski July 25, 2024 - 5:54pm Thomas Nhan Director, Product Management, Tableau Lari McEdward Technical Writer, Tableau Expand your datamodeling and analysis with Multi-fact Relationships, available with Tableau 2024.2. Sometimes data spans multiple base tables in different, unrelated contexts.
Some fantastic components of Power BI include: Power Query lets you merge data from different sources Power Pivot aids in datamodelling for creating datamodels Power View constructs interactive charts, graphs and maps. Data Processing, Data Integration, and Data Presenting form the nucleus of Power BI.
Besides easy access, using Trainium with Metaflow brings a few additional benefits: Infrastructure accessibility Metaflow is known for its developer-friendly APIs that allow ML/AI developers to focus on developing models and applications, and not worry about infrastructure. Complete the following steps: Download the CloudFormation template.
This will then give you a good grounding in a variety of business topics that you can apply to your own business, allowing you to see patterns and understand the data that you collect. Download the Right Data Analysis Software.
Complete the following steps for manual deployment: Download these assets directly from the GitHub repository. Make sure you’re updating the datamodel ( updateTrackListData function) to handle your custom fields. The assets (JavaScript and CSS files) are available in our GitHub repository. Host them in your own S3 bucket.
Walkthrough Download the pre-tokenized Wikipedia dataset as shown: export DATA_DIR=~/examples_datasets/gpt2 mkdir -p ${DATA_DIR} && cd ${DATA_DIR} wget [link] wget [link] aws s3 cp s3://neuron-s3/training_datasets/gpt/wikipedia/my-gpt2_text_document.bin. Each trn1.32xl has 16 accelerators with two workers per accelerator.
What if you could automatically shard your PostgreSQL database across any number of servers and get industry-leading performance at scale without any special datamodelling steps? Schema-based sharding has almost no datamodelling restrictions or special steps compared to unsharded PostgreSQL.
In addition to versioning code, teams can also version data, models, experiments and more. Released in 2022, DagsHub’s Direct Data Access (DDA for short) allows Data Scientists and Machine Learning engineers to stream files from DagsHub repository without needing to download them to their local environment ahead of time.
MLOps cover all of the rest, how to track your experiments, how to share your work, how to version your models etc (Full list in the previous post. ). Also same expertise rule applies for an ML engineer, the more versed you are in MLOps the better you can foresee issues, fix data/model bugs and be a valued team member.
Create a model function for accessing PyAnnote speaker diarization from Hugging Face You can use the Hugging Face Hub to access the desired pre-trained PyAnnote speaker diarization model. You use the same script for downloading the model file when creating the SageMaker endpoint.
Just click this button and fill out the form to download it. Model Your Data Appropriately Once you have chosen the method to connect to your data (Import, DirectQuery, Composite), you will need to make sure that you create an efficient and optimized datamodel. Want to Save This Guide for Later? No problem!
You can grab the ReGraph file from the ‘downloads’ page of the SDK site, once you’ve started your trial. cp ~/Downloads/regraph-1.5.0.tgz. The datamodel Our Sandbox contains a subset of Neo4j-related Stack Overflow questions. Then we add ReGraph as a dependency. yarn add file:regraph-1.5.0.tgz
Neo4j Browser is great for developers who want to explore their datamodel The data visualization toolkits Our graph visualization toolkits are KeyLines and ReGraph – the only difference is that KeyLines is for JavaScript developers and ReGraph is designed for React apps.
Platforms like DataRobot AI Cloud support business analysts and data scientists by simplifying data prep, automating model creation, and easing ML operations ( MLOps ). These features reduce the need for a large workforce of data professionals. Download Now. Download Now. BARC ANALYST REPORT.
You should see the data imports in progress. When the state machine for Import-Dataset is complete, you can proceed to the next step to build your time series datamodel. Create AutoPredictor (train a time series model) This section describes how to train an initial predictor with Forecast. Choose View datasets.
Shadow data, shadow models, shadow AI With gen AI as the new gold rush nowadays, various stakeholders in the organization can easily expose it to unmanaged risk linked with unsanctioned data, models, and overall use of AI. It also helps teams better manage their risk profiles and security investments.
We document these custom models in Alation Data Catalog and publish common queries that other teams can use for operational use cases or reporting needs. Contact title mappings, which are buiilt in some of datamodels, are documented within our data catalog. Jason: How do you use these models?
To learn how to effectively deploy a Vision Transformer model with FastAPI and perform inference via exposed APIs, just keep reading. Jump Right To The Downloads Section What Is FastAPI? Start by accessing the “ Downloads ” section of this tutorial to retrieve the source code and example images. file paths and model names).
Now, to download Mixtral, you must login into your account using an access token: huggingface-cli login --token YOUR_TOKEN We then need access to an IAM Role with the required permissions for Sagemaker. After finishing it, we can acces the model using from_pretrained method from transformers library. You can find here more about it.
This begins the process of converting the data stored in the S3 bucket into vector embeddings in your OpenSearch Serverless vector collection. Note: The syncing operation can take minutes to hours to complete, based on the size of the dataset stored in your S3 bucket.
Nowadays, with the advent of deep learning and convolutional neural networks, this process can be automated, allowing the model to learn the most relevant features directly from the data. Model Training: With the labeled data and identified features, the next step is to train a machine learning model.
It installs and imports all the required dependencies, instantiates a SageMaker session and client, and sets the default Region and S3 bucket for storing data. Data preparation Download the California Housing dataset and prepare it by running the DownloadData section of the notebook.
It provides a single platform for building custom automation pipelines that can easily build models, track experiments, and then directly deploy them into a production-ready hosted environment. Under Need Authorization, add the secret credentials you downloaded from step 3b above Add a name to the repository.
A key finding of the survey is that the ability to find data contributes greatly to the success of BI initiatives. In the study, 75% of the 770 survey respondents indicated having difficulty in locating and accessing analytic content including data, models, and metadata. Subscribe to Alation's Blog.
Many people use the term to describe a data quality metric. Technical users, including database administrators, might tell you that data integrity concerns whether or not the data conforms to a pre-defined datamodel. Download Now, let’s consider a somewhat less obvious example.
It needed a project structure, a datamodel, valid movements for the pieces, and tests. I downloaded a repo from Github with some initial code. Of the live coding assignments, I passed three and failed two. In the first one I failed, I had to write a limited chess program, that only supported two kinds of pieces.
This report underscores the growing need at enterprises for a catalog to drive key use cases, including self-service BI , data governance , and cloud data migration. You can download a copy of the report here. But do they empower many user types to quickly find trusted data for a business decision or datamodel?
Use it to download various dbt packages into your own dbt project. FAQs What are dbt models? A dbt model is how you want to create a table or view in your datamodel. You can use the SQL Select statement to write a model. A dbt python model is a model that uses the Python language and is defined using the.py
Just click this button and fill out the form to download it. In terms of AI capabilities and technologies, you’ll want to think about a few key components: Data Platform and Feature Store : Where will your data scientists source their data? Want to Save This Guide for Later? No problem!
Then can download the neuron model and tokenizer config files from the above step and store them in the model directory, e.g script by overwriting the model_fn to load our neuron model and the predict_fn to create a text-classification pipeline. ! into the code/ directory of the model directory. ! copy inference.py
For instance, convolutional layers excel at image processing tasks, while recurrent layers are designed for sequence data like time series. By stacking multiple layers, developers can create deep networks capable of capturing complex patterns in data. Ensure Python is installed: It works with Python 3.7
Load and prepare the data As a first step, we make sure the downloaded digits data we need for training is accessible to SageMaker. Refer to the notebook for the complete source code and feel free to adapt it with your own data. So, please check it out. Amazon S3 allows us to do this in a safe and scalable way.
You don’t want to end up in a situation where you need to rewrite a system due to some shortcuts you took early on when only one data scientist was using it. Some will want to track entire pipelines of data transformations, and others will monitor models in production. model weights, configuration files, etc.
How can we build up toward our vision in terms of solvable data problems and specific data products? data sources or simpler datamodels) of the data products we want to build? What are we working towards? What are the dependencies (e.g. How can we resolve those dependencies step-by-step?
Comet enables you to log essential information such as data, model architecture, hyperparameters, confusion matrices, graphs, etc. Class Labels: 5 (business, entertainment, politics, sport, tech) Download the data here. Without proper tracking, your workflow can become convoluted and challenging to navigate.
If you will ask data professionals about what is the most challenging part of their day to day work, you will likely discover their concerns around managing different aspects of data before they get to graduate to the datamodeling stage. Pricing It is free to use and is licensed under Apache License Version 2.0.
NoSQL Databases NoSQL databases do not follow the traditional relational database structure, which makes them ideal for storing unstructured data. They allow flexible datamodels such as document, key-value, and wide-column formats, which are well-suited for large-scale data management.
Model versioning, lineage, and packaging : Can you version and reproduce models and experiments? Can you see the complete model lineage with data/models/experiments used downstream? It enables transfer learning by making various ML models freely available as libraries or web API calls.
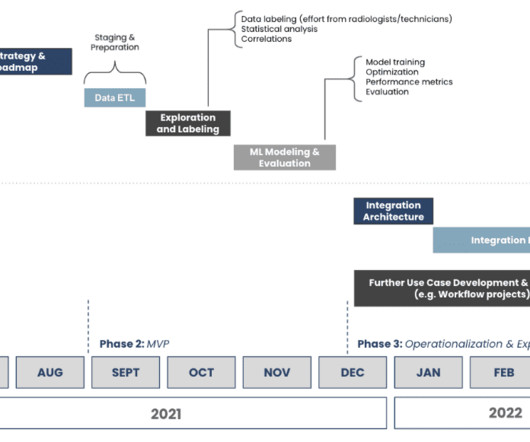
These steps include defining business and project objectives, acquiring and exploring data, modeling the data with various algorithms, interpreting and communicating the project outcome, and implementing and maintaining the project.
With the enhancements to View Data, you can remove and add fields as well as adjust the number of rows to cover the breadth and depth that your analysis needs. Once you have achieved your desired data configuration, you can download the data as a CSV in your customized layout. . Easily swap root tables in your datamodel.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content