This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Conventional ML development cycles take weeks to many months and requires sparse data science understanding and ML development skills. Business analysts’ ideas to use ML models often sit in prolonged backlogs because of data engineering and data science team’s bandwidth and datapreparation activities.
AWS Glue is a serverless data integration service that makes it easy to discover, prepare, and combine data for analytics, ML, and application development. Deploy the CloudFormation template Complete the following steps to deploy the CloudFormation template: Save the CloudFormation template sm-redshift-demo-vpc-cfn-v1.yaml
Many announcements at Strata centered on product integrations, with vendors closing the loop and turning tools into solutions, most notably: A Paxata-HDInsight solution demo, where Paxata showcased the general availability of its Adaptive Information Platform for Microsoft Azure. 3) Data professionals come in all shapes and forms.
See also Thoughtworks’s guide to Evaluating MLOps Platforms End-to-end MLOps platforms End-to-end MLOps platforms provide a unified ecosystem that streamlines the entire ML workflow, from datapreparation and model development to deployment and monitoring. Flyte Flyte is a platform for orchestrating ML pipelines at scale.
What’s really important in the before part is having production-grade machine learning datapipelines that can feed your model training and inference processes. And that’s really key for taking data science experiments into production. Let’s go and talk about machine learning pipelining.
What’s really important in the before part is having production-grade machine learning datapipelines that can feed your model training and inference processes. And that’s really key for taking data science experiments into production. Let’s go and talk about machine learning pipelining.
Continuous monitoring of resources, data, and metrics. DataPipeline - Manages and processes various data sources. ML Pipeline - Focuses on training, validation and deployment. Application Pipeline - Manages requests and data/model validations. Collecting feedback for further tuning.
Again, what goes on in this component is subjective to the data scientist’s initial (manual) datapreparation process, the problem, and the data used. Kedro Kedro is a Python library for building modular data science pipelines. Pre-requisites In this demo, you will use MiniKF to set up Kubeflow on AWS.
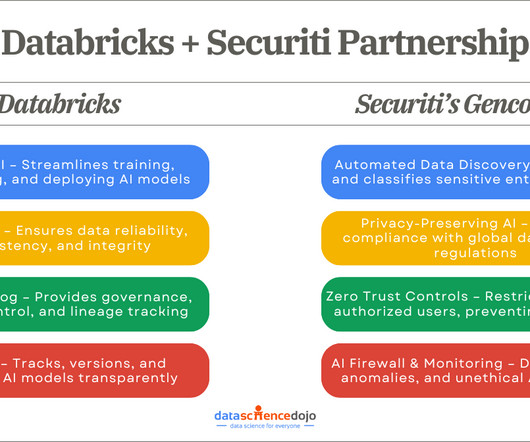
The partnership between Databricks and Gencore AI enables enterprises to develop AI applications with robust security measures, optimized datapipelines, and comprehensive governance. Optimized DataPipelines for AI Readiness AI models are only as good as the data they process.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















Let's personalize your content