This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
To unlock the potential of generative AI technologies, however, there’s a key prerequisite: your data needs to be appropriately prepared. In this post, we describe how use generative AI to update and scale your datapipeline using Amazon SageMaker Canvas for data prep.
Machine learning (ML) helps organizations to increase revenue, drive business growth, and reduce costs by optimizing core business functions such as supply and demand forecasting, customer churn prediction, credit risk scoring, pricing, predicting late shipments, and many others. Let’s learn about the services we will use to make this happen.
With that, the need for data scientists and machine learning (ML) engineers has grown significantly. Data scientists and ML engineers require capable tooling and sufficient compute for their work. Data scientists and ML engineers require capable tooling and sufficient compute for their work.
With all this packaged into a well-governed platform, Snowflake continues to set the standard for data warehousing and beyond. Snowflake supports data sharing and collaboration across organizations without the need for complex datapipelines. One of the standout features of Dataiku is its focus on collaboration.
Amazon SageMaker is a fully managed machine learning (ML) service. With SageMaker, data scientists and developers can quickly and easily build and train ML models, and then directly deploy them into a production-ready hosted environment. We add this data to Snowflake as a new table.
Amazon Redshift is the most popular cloud data warehouse that is used by tens of thousands of customers to analyze exabytes of data every day. SageMaker Studio is the first fully integrated development environment (IDE) for ML. Solution overview The following diagram illustrates the solution architecture for each option.
Automate and streamline our ML inference pipeline with SageMaker and Airflow Building an inference datapipeline on large datasets is a challenge many companies face. The Batch job automatically launches an ML compute instance, deploys the model, and processes the input data in batches, producing the output predictions.
Alignment to other tools in the organization’s tech stack Consider how well the MLOps tool integrates with your existing tools and workflows, such as data sources, data engineering platforms, code repositories, CI/CD pipelines, monitoring systems, etc. and Pandas or Apache Spark DataFrames.
Statistical methods and machine learning (ML) methods are actively developed and adopted to maximize the LTV. In this post, we share how Kakao Games and the Amazon Machine Learning Solutions Lab teamed up to build a scalable and reliable LTV prediction solution by using AWS data and ML services such as AWS Glue and Amazon SageMaker.
Machine learning (ML) is becoming increasingly complex as customers try to solve more and more challenging problems. This complexity often leads to the need for distributed ML, where multiple machines are used to train a single model. SageMaker is a fully managed service for building, training, and deploying ML models.
Instead, businesses tend to rely on advanced tools and strategies—namely artificial intelligence for IT operations (AIOps) and machine learning operations (MLOps)—to turn vast quantities of data into actionable insights that can improve IT decision-making and ultimately, the bottom line.
The ZMP analyzes billions of structured and unstructured data points to predict consumer intent by using sophisticated artificial intelligence (AI) to personalize experiences at scale. Hosted on Amazon ECS with tasks run on Fargate, this platform streamlines the end-to-end ML workflow, from data ingestion to model deployment.
MLOps accelerates the ML model deployment process to make it more efficient and scalable. In this blog post, we detail the steps you need to take to build and run a successful MLOps pipeline. An extension of DevOps, MLOps streamlines and monitors ML workflows. MLOps pipelines support a production-first approach.
Purina used artificial intelligence (AI) and machine learning (ML) to automate animal breed detection at scale. The solution focuses on the fundamental principles of developing an AI/ML application workflow of datapreparation, model training, model evaluation, and model monitoring.
Despite the challenges, Afri-SET, with limited resources, envisions a comprehensive data management solution for stakeholders seeking sensor hosting on their platform, aiming to deliver accurate data from low-cost sensors. With AWS Glue custom connectors, it’s effortless to transfer data between Amazon S3 and other applications.
In the following sections, we provide a detailed, step-by-step guide on implementing these new capabilities, covering everything from datapreparation to job submission and output analysis. This use case serves to illustrate the broader potential of the feature for handling diverse data processing tasks.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python MLPipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python MLPipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
Data Scientists and AI experts: Historically we have seen Data Scientists build and choose traditional ML models for their use cases. Data Scientists will typically help with training, validating, and maintaining foundation models that are optimized for data tasks.
Both computer scientists and business leaders have taken note of the potential of the data. Machine learning (ML), a subset of artificial intelligence (AI), is an important piece of data-driven innovation. MLOps is the next evolution of data analysis and deep learning. What is MLOps?
These activities cover disparate fields such as basic data processing, analytics, and machine learning (ML). ML is often associated with PBAs, so we start this post with an illustrative figure. The ML paradigm is learning followed by inference. The union of advances in hardware and ML has led us to the current day.
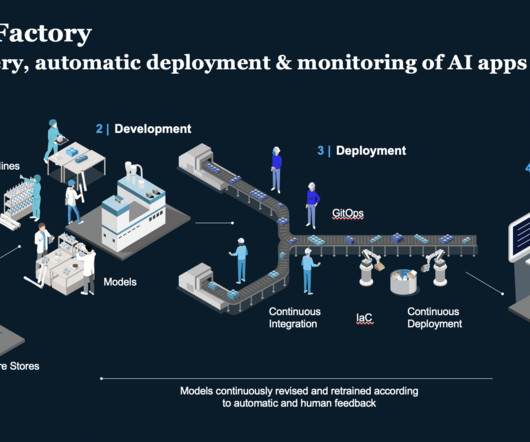
Understanding the MLOps Lifecycle The MLOps lifecycle consists of several critical stages, each with its unique challenges: Data Ingestion: Collecting data from various sources and ensuring it’s available for analysis. DataPreparation: Cleaning and transforming raw data to make it usable for machine learning.
They are characterized by their enormous size, complexity, and the vast amount of data they process. These elements need to be taken into consideration when managing, streamlining and deploying LLMs in MLpipelines, hence the specialized discipline of LLMOps. Continuous monitoring of resources, data, and metrics.
A traditional machine learning (ML) pipeline is a collection of various stages that include data collection, datapreparation, model training and evaluation, hyperparameter tuning (if needed), model deployment and scaling, monitoring, security and compliance, and CI/CD. What is MLOps?
is our enterprise-ready next-generation studio for AI builders, bringing together traditional machine learning (ML) and new generative AI capabilities powered by foundation models. Automated development: Automates datapreparation, model development, feature engineering and hyperparameter optimization using AutoAI. .”
Today’s data management and analytics products have infused artificial intelligence (AI) and machine learning (ML) algorithms into their core capabilities. These modern tools will auto-profile the data, detect joins and overlaps, and offer recommendations. 2) Line of business is taking a more active role in data projects.
On the client side, Snowpark consists of libraries, including the DataFrame API and native Snowpark machine learning (ML) APIs for model development (public preview) and deployment (private preview). Machine Learning Training machine learning (ML) models can sometimes be resource-intensive.
DataRobot now delivers both visual and code-centric datapreparation and datapipelines, along with automated machine learning that is composable, and can be driven by hosted notebooks or a graphical user experience. Finally, I’m excited to announce nearly 100 new features in DataRobot 7.2
Automation Automation plays a pivotal role in streamlining ETL processes, reducing the need for manual intervention, and ensuring consistent data availability. By automating key tasks, organisations can enhance efficiency and accuracy, ultimately improving the quality of their datapipelines.
Alteryx provides organizations with an opportunity to automate access to data, analytics , data science, and process automation all in one, end-to-end platform. Its capabilities can be split into the following topics: automating inputs & outputs, datapreparation, data enrichment, and data science.
I am Ali Arsanjani, and I lead partner engineering for Google Cloud, specializing in the area of AI-ML, and I’m very happy to be here today with everyone. Then we’re going to talk about adapting foundation models for the enterprise and how that affects the ML lifecycle, and what we need to potentially add to the lifecycle.
I am Ali Arsanjani, and I lead partner engineering for Google Cloud, specializing in the area of AI-ML, and I’m very happy to be here today with everyone. Then we’re going to talk about adapting foundation models for the enterprise and how that affects the ML lifecycle, and what we need to potentially add to the lifecycle.
We then go over all the project components and processes, from datapreparation, model training, and experiment tracking to model evaluation, to equip you with the skills to construct your own emotion recognition model. BECOME a WRITER at MLearning.ai // FREE ML Tools // Clearview AI Mlearning.ai
One of the most prevalent complaints we hear from ML engineers in the community is how costly and error-prone it is to manually go through the ML workflow of building and deploying models. Building end-to-end machine learning pipelines lets ML engineers build once, rerun, and reuse many times.
AI engineering - AI is being democratized for developers and engineers, expanding beyond the limited pool of data scientists. Companies are building AI tools and frameworks that empower engineers to integrate AI into applications without needing deep expertise in ML. AI Agents and multi-agent systems.
With a vision to build a large language model (LLM) trained on Italian data, Fastweb embarked on a journey to make this powerful AI capability available to third parties. Fine-tuning Mistral 7B on AWS Fastweb recognized the importance of developing language models tailored to the Italian language and culture.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content