This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In the data-driven world […] The post Monitoring DataQuality for Your Big DataPipelines Made Easy appeared first on Analytics Vidhya. Determine success by the precision of your charts, the equipment’s dependability, and your crew’s expertise. A single mistake, glitch, or slip-up could endanger the trip.
Accurate and secure data can help to streamline software engineering processes and lead to the creation of more powerful AI tools, but it has become a challenge to maintain the quality of the expansive volumes of data needed by the most advanced AI models.
Organizations require reliable data for robust AI models and accurate insights, yet the current technology landscape presents unparalleled dataquality challenges. ETL/ELT tools typically have two components: a design time (to design data integration jobs) and a runtime (to execute data integration jobs).
IBM Multicloud Data Integration helps organizations connect data from disparate sources, build datapipelines, remediate data issues, enrich data, and deliver integrated data to multicloud platforms where it can easily accessed by data consumers or built into a data product.
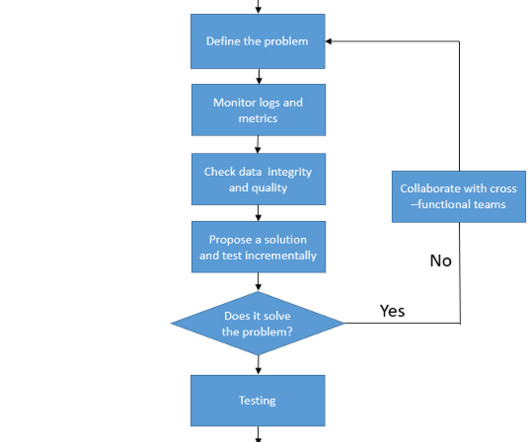
Big datapipelines are the backbone of modern data processing, enabling organizations to collect, process, and analyze vast amounts of data in real-time. Issues such as data inconsistencies, performance bottlenecks, and failures are inevitable.In Validate data format and schema compatibility.
Summary: This blog explains how to build efficient datapipelines, detailing each step from data collection to final delivery. Introduction Datapipelines play a pivotal role in modern data architecture by seamlessly transporting and transforming raw data into valuable insights.
Implementing a data fabric architecture is the answer. What is a data fabric? Data fabric is defined by IBM as “an architecture that facilitates the end-to-end integration of various datapipelines and cloud environments through the use of intelligent and automated systems.”
Key Takeaways By deploying technologies that can learn and improve over time, companies that embrace AI and machine learning can achieve significantly better results from their dataquality initiatives. Here are five dataquality best practices which business leaders should focus.
In part one of this article, we discussed how data testing can specifically test a data object (e.g., table, column, metadata) at one particular point in the datapipeline.
Poor dataquality is one of the top barriers faced by organizations aspiring to be more data-driven. Ill-timed business decisions and misinformed business processes, missed revenue opportunities, failed business initiatives and complex data systems can all stem from dataquality issues.
We also discuss different types of ETL pipelines for ML use cases and provide real-world examples of their use to help data engineers choose the right one. What is an ETL datapipeline in ML? This ensures that the data which will be used for ML is accurate, reliable, and consistent.
Data integration processes benefit from automated testing just like any other software. Yet finding a datapipeline project with a suitable set of automated tests is rare. Even when a project has many tests, they are often unstructured, do not communicate their purpose, and are hard to run.
“Quality over Quantity” is a phrase we hear regularly in life, but when it comes to the world of data, we often fail to adhere to this rule. DataQuality Monitoring implements quality checks in operational data processes to ensure that the data meets pre-defined standards and business rules.
Companies these days have multiple on-premise as well as cloud platforms to store their data. The data contained can be both structured and unstructured and available in a variety of formats such as files, database applications, SaaS applications, etc. Dataquality and governance.
Systems and data sources are more interconnected than ever before. A broken datapipeline might bring operational systems to a halt, or it could cause executive dashboards to fail, reporting inaccurate KPIs to top management. Is your data governance structure up to the task? Read What Is Data Observability?
Now, almost any company can build a solid, cost-effective data analytics or BI practice grounded in these new cloud platforms. eBook 4 Ways to Measure DataQuality To measure dataquality and track the effectiveness of dataquality improvement efforts you need data.
Dataquality control: Robust dataset labeling and annotation tools incorporate quality control mechanisms such as inter-annotator agreement analysis, review workflows, and data validation checks to ensure the accuracy and reliability of annotations. Dolt Dolt is an open-source relational database system built on Git.
There’s not much value in holding on to raw data without putting it to good use, yet as the cost of storage continues to decrease, organizations find it useful to collect raw data for additional processing. The raw data can be fed into a database or data warehouse. If it’s not done right away, then later.
Amazon DocumentDB is a fully managed native JSON document database that makes it straightforward and cost-effective to operate critical document workloads at virtually any scale without managing infrastructure. Enter a user name, password, and database name. For this post, we add our restaurant data. Choose Add connection.
The ability to effectively deploy AI into production rests upon the strength of an organization’s data strategy because AI is only as strong as the data that underpins it. This strategy helps organizations optimize data usage, expand into new markets, and increase revenue.
You can think of a data catalog as an enhanced Access database or library card catalog system. It helps you locate and discover data that fit your search criteria. With data catalogs, you won’t have to waste time looking for information you think you have. What Does a Data Catalog Do?
Effective data governance enhances quality and security throughout the data lifecycle. What is Data Engineering? Data Engineering is designing, constructing, and managing systems that enable data collection, storage, and analysis. This section explores essential aspects of Data Engineering.
Tools like Git and Jenkins are not suited for managing data. By capturing metadata, such as transformations, storage configurations, versions, owners, lineage, statistics, dataquality, and other relevant attributes of the data, a feature platform can address these issues. This is where a feature platform comes in handy.
Before a bank can start the process of certifying a risk model, they first need to understand what data is being used and how it changes as it moves from a database to a model. The value of data lineage applies across all industries, but there are three key focuses when you consider it for banking use cases: 1.
There are many well-known libraries and platforms for data analysis such as Pandas and Tableau, in addition to analytical databases like ClickHouse, MariaDB, Apache Druid, Apache Pinot, Google BigQuery, Amazon RedShift, etc. With these data exploration tools, you can determine if your data is accurate, consistent, and reliable.
In this post, you will learn about the 10 best datapipeline tools, their pros, cons, and pricing. A typical datapipeline involves the following steps or processes through which the data passes before being consumed by a downstream process, such as an ML model training process.
Data observability is a key element of data operations (DataOps). It enables a big-picture understanding of the health of your organization’s data through continuous AI/ML-enabled monitoring – detecting anomalies throughout the datapipeline and preventing data downtime. Is Data Observability Right for You?
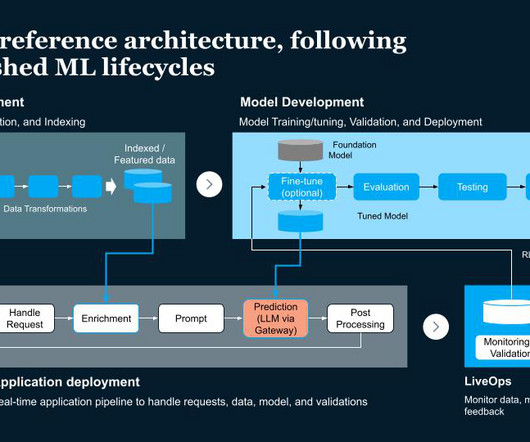
The 4 Gen AI Architecture Pipelines The four pipelines are: 1. The DataPipeline The datapipeline is the foundation of any AI system. It's responsible for collecting and ingesting the data from various external sources, processing it and managing the data.
Collecting, storing, and processing large datasets Data engineers are also responsible for collecting, storing, and processing large volumes of data. This involves working with various data storage technologies, such as databases and data warehouses, and ensuring that the data is easily accessible and can be analyzed efficiently.
Data Engineer: A data engineer sets the foundation of building any generating AI app by preparing, cleaning and validating data required to train and deploy AI models. They design datapipelines that integrate different datasets to ensure the quality, reliability, and scalability needed for AI applications.
Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. They create datapipelines, ETL processes, and databases to facilitate smooth data flow and storage. Data Warehousing: Amazon Redshift, Google BigQuery, etc.
Systems and data sources are more interconnected than ever before. A broken datapipeline might bring operational systems to a halt, or it could cause executive dashboards to fail, reporting inaccurate KPIs to top management. Schema refers to the way data is organized or defined within a database.
Easy-to-experiment data development environment. Automated testing to ensure dataquality. There are many inefficiencies that riddle a datapipeline and DataOps aims to deal with that. DataOps makes processes more efficient by automating as much of the datapipeline as possible.
Not only does it involve the process of collecting, storing, and processing data so that it can be used for analysis and decision-making, but these professionals are responsible for building and maintaining the infrastructure that makes this possible; and so much more. Think of data engineers as the architects of the data ecosystem.
Top contenders like Apache Airflow and AWS Glue offer unique features, empowering businesses with efficient workflows, high dataquality, and informed decision-making capabilities. Introduction In today’s business landscape, data integration is vital. Transformation Transformation is the second step in the ETL process.
Introduction ETL plays a crucial role in Data Management. This process enables organisations to gather data from various sources, transform it into a usable format, and load it into data warehouses or databases for analysis. The goal is to retrieve the required data efficiently without overwhelming the source systems.
Building a Trusted Single View of Critical Data Most organizations are at least somewhat aware of problems with dataquality and accuracy. As they mature, technology teams tend to shift from a narrow focus on dataquality to a big-picture aspiration to build trust in their data. Real-time data is the goal.
Separately, the company uses AWS data services, such as Amazon Simple Storage Service (Amazon S3), to store data related to patients, such as patient information, device ownership details, and clinical telemetry data obtained from the wearables. For Analysis type , choose DataQuality and Insights Report.
Summary: Data ingestion is the process of collecting, importing, and processing data from diverse sources into a centralised system for analysis. This crucial step enhances dataquality, enables real-time insights, and supports informed decision-making. Files: Data stored in flat files, CSVs, or Excel sheets.
The primary goal of Data Engineering is to transform raw data into a structured and usable format that can be easily accessed, analyzed, and interpreted by Data Scientists, analysts, and other stakeholders. Future of Data Engineering The Data Engineering market will expand from $18.2
An enterprise data catalog does all that a library inventory system does – namely streamlining data discovery and access across data sources – and a lot more. For example, data catalogs have evolved to deliver governance capabilities like managing dataquality and data privacy and compliance.
According to the 2023 Data Integrity Trends and Insights Report , dataquality is the #1 barrier to achieving data integrity. And poor address quality is the top challenge preventing business leaders from effectively using location data to add context and multidimensional value to their decision-making processes.
Why start with a data source and build a visualization, if you can just find a visualization that already exists, complete with metadata about it? Data scientists went beyond database tables to data lakes and cloud data stores. Data scientists want to catalog not just information sources, but models.
Setting up the Information Architecture Setting up an information architecture during migration to Snowflake poses challenges due to the need to align existing data structures, types, and sources with Snowflake’s multi-cluster, multi-tier architecture. Moving historical data from a legacy system to Snowflake poses several challenges.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content