This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
When we talk about data integrity, we’re referring to the overarching completeness, accuracy, consistency, accessibility, and security of an organization’s data. Together, these factors determine the reliability of the organization’s data.
Systems and data sources are more interconnected than ever before. A broken datapipeline might bring operational systems to a halt, or it could cause executive dashboards to fail, reporting inaccurate KPIs to top management. Is your data governance structure up to the task? Read What Is Data Observability?
As such, the quality of their data can make or break the success of the company. This article will guide you through the concept of a dataquality framework, its essential components, and how to implement it effectively within your organization. What is a dataquality framework?
“Quality over Quantity” is a phrase we hear regularly in life, but when it comes to the world of data, we often fail to adhere to this rule. DataQuality Monitoring implements quality checks in operational data processes to ensure that the data meets pre-defined standards and business rules.
Jacomo Corbo is a Partner and Chief Scientist, and Bryan Richardson is an Associate Partner and Senior Data Scientist, for QuantumBlack AI by McKinsey. They presented “Automating DataQuality Remediation With AI” at Snorkel AI’s The Future of Data-Centric AI Summit in 2022. That is still in flux and being worked out.
Dataquality control: Robust dataset labeling and annotation tools incorporate quality control mechanisms such as inter-annotator agreement analysis, review workflows, and data validation checks to ensure the accuracy and reliability of annotations. Data monitoring tools help monitor the quality of the data.
Jacomo Corbo is a Partner and Chief Scientist, and Bryan Richardson is an Associate Partner and Senior Data Scientist, for QuantumBlack AI by McKinsey. They presented “Automating DataQuality Remediation With AI” at Snorkel AI’s The Future of Data-Centric AI Summit in 2022. That is still in flux and being worked out.
Jacomo Corbo is a Partner and Chief Scientist, and Bryan Richardson is an Associate Partner and Senior Data Scientist, for QuantumBlack AI by McKinsey. They presented “Automating DataQuality Remediation With AI” at Snorkel AI’s The Future of Data-Centric AI Summit in 2022. That is still in flux and being worked out.
You can see our photos from the event here , and be sure to follow our YouTube for virtual highlights from the conference as well. Over in San Francisco, we had a keynote for each day of the event. Other Events Aside from networking events and all of our sessions, we had a few other special events. What’s next?
The goal of digital transformation remains the same as ever – to become more data-driven. We have learned how to gain a competitive advantage by capturing business events in data. Events are data snap-shots of complex activity sourced from the web, customer systems, ERP transactions, social media, […].
If the question was Whats the schedule for AWS events in December?, AWS usually announces the dates for their upcoming # re:Invent event around 6-9 months in advance. Rajesh Nedunuri is a Senior Data Engineer within the Amazon Worldwide Returns and ReCommerce Data Services team.
In this post, you will learn about the 10 best datapipeline tools, their pros, cons, and pricing. A typical datapipeline involves the following steps or processes through which the data passes before being consumed by a downstream process, such as an ML model training process.
Tools like Git and Jenkins are not suited for managing data. By capturing metadata, such as transformations, storage configurations, versions, owners, lineage, statistics, dataquality, and other relevant attributes of the data, a feature platform can address these issues. This is where a feature platform comes in handy.
Effective data governance enhances quality and security throughout the data lifecycle. What is Data Engineering? Data Engineering is designing, constructing, and managing systems that enable data collection, storage, and analysis. ETL is vital for ensuring dataquality and integrity.
In this post, we discuss how to bring data stored in Amazon DocumentDB into SageMaker Canvas and use that data to build ML models for predictive analytics. Without creating and maintaining datapipelines, you will be able to power ML models with your unstructured data stored in Amazon DocumentDB.
It enables a big-picture understanding of the health of your organization’s data through continuous AI/ML-enabled monitoring – detecting anomalies throughout the datapipeline and preventing data downtime. Why is data observability so important? Longer-term data trends also require attention.
We couldn’t be more excited to announce two events that will be co-located with ODSC East in Boston this April: The Data Engineering Summit and the Ai X Innovation Summit. These two co-located events represent an opportunity to dive even deeper into the topics and trends shaping these disciplines. Learn more about them below.
The 4 Gen AI Architecture Pipelines The four pipelines are: 1. The DataPipeline The datapipeline is the foundation of any AI system. It's responsible for collecting and ingesting the data from various external sources, processing it and managing the data.
Not only does it involve the process of collecting, storing, and processing data so that it can be used for analysis and decision-making, but these professionals are responsible for building and maintaining the infrastructure that makes this possible; and so much more. Think of data engineers as the architects of the data ecosystem.
As a proud member of the Connect with Confluent program , we help organizations going through digital transformation and IT infrastructure modernization break down data silos and power their streaming datapipelines with trusted data. Let’s cover some additional information to know before attending.
Systems and data sources are more interconnected than ever before. A broken datapipeline might bring operational systems to a halt, or it could cause executive dashboards to fail, reporting inaccurate KPIs to top management. The application of this concept to data is relatively new. Complexity leads to risk.
Elementl / Dagster Labs Elementl and Dagster Labs are both companies that provide platforms for building and managing datapipelines. Elementl’s platform is designed for data engineers, while Dagster Labs’ platform is designed for data scientists. Interested in attending an ODSC event?
As the name suggests, real-time operating systems (RTOS) handle real-time applications that undertake data and event processing under a strict deadline. It is also important to establish dataquality standards and strict access controls.
The right data integration solution helps you streamline operations, enhance dataquality, reduce costs, and make better data-driven decisions. It synthesizes all the metadata around your organization’s data assets and arranges the information into a simple, easy-to-understand format.
Business managers are faced with plotting the optimal course in the face of these evolving events. Pipelines must have robust data integration capabilities that integrate data from multiple data silos, including the extensive list of applications used throughout the organization, databases and even mainframes.
If you’re not familiar with DGIQ, it’s the world’s most comprehensive event dedicated to, you guessed it, data governance and information quality. This year’s DGIQ West will host tutorials, workshops, seminars, general conference sessions, and case studies for global data leaders.
The DAGs can then be scheduled to run at specific intervals or triggered when an event occurs. It even offers a user-friendly interface to visualize the pipelines and monitor progress. The Data Source Tool can automate scanning DDL and profiling tables between source and target, comparing them, and then reporting findings.
Setting up the Information Architecture Setting up an information architecture during migration to Snowflake poses challenges due to the need to align existing data structures, types, and sources with Snowflake’s multi-cluster, multi-tier architecture. Moving historical data from a legacy system to Snowflake poses several challenges.
Horizon addresses key aspects of data governance, including: Compliance Security Access Privacy Interoperability Throughout the remainder of this blog, we will dive deeper into each of the above components and take a look at the ways in which Horizon can help. We will begin with compliance.
Methods that allow our customer data models to be as dynamic and flexible as the customers they represent. In this guide, we will explore concepts like transitional modeling for customer profiles, the power of event logs for customer behavior, persistent staging for raw customer data, real-time customer data capture, and much more.
A 2019 survey by McKinsey on global data transformation revealed that 30 percent of total time spent by enterprise IT teams was spent on non-value-added tasks related to poor dataquality and availability. It truly is an all-in-one data lake solution. Roxie then consolidates that data and presents the results.
Due to the convergence of events in the data analytics and AI landscape, many organizations are at an inflection point. From there, it can be easily accessed via dashboards by data consumers or those building into a data product.
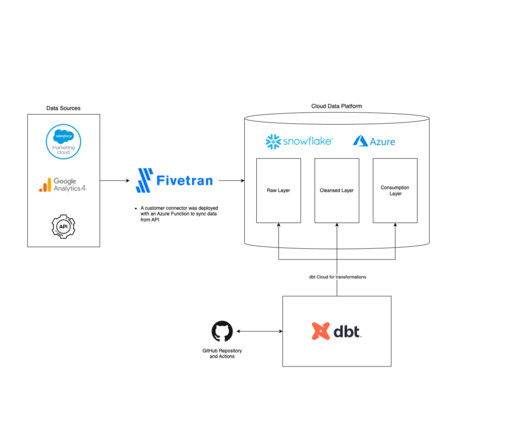
In addition to the Application type, Fivetran provides connectors for databases, files, events, and functions. Salesforce – The Salesforce (SFDC) connector streamlines customer relationship management (CRM) data integration. Scalability Considerations: Ensure your data integration setup is scalable and ready for future growth.
Snorkel AI wrapped the second day of our The Future of Data-Centric AI virtual conference by showcasing how Snorkel’s data-centric platform has enabled customers to succeed, taking a deep look at Snorkel Flow’s capabilities, and announcing two new solutions. You need to find a place to park your data.
Snorkel AI wrapped the second day of our The Future of Data-Centric AI virtual conference by showcasing how Snorkel’s data-centric platform has enabled customers to succeed, taking a deep look at Snorkel Flow’s capabilities, and announcing two new solutions. You need to find a place to park your data.
With proper unstructured data management, you can write validation checks to detect multiple entries of the same data. Continuous learning: In a properly managed unstructured datapipeline, you can use new entries to train a production ML model, keeping the model up-to-date.
For small-scale/low-value deployments, there might not be many items to focus on, but as the scale and reach of deployment go up, data governance becomes crucial. This includes dataquality, privacy, and compliance. The datapipelines can be scheduled as event-driven or be run at specific intervals the users choose.
Data Engineer Data engineers are the authors of the infrastructure that stores, processes, and manages the large volumes of data an organization has. The main aspect of their profession is the building and maintenance of datapipelines, which allow for data to move between sources. Well then, you’re in luck.
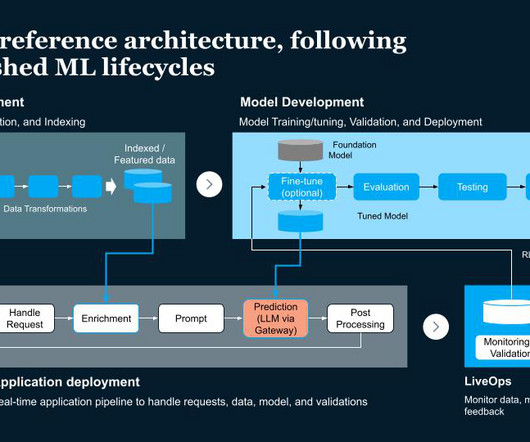
Continuous monitoring of resources, data, and metrics. DataPipeline - Manages and processes various data sources. ML Pipeline - Focuses on training, validation and deployment. Application Pipeline - Manages requests and data/model validations. Collecting feedback for further tuning.
This step includes: Identifying Data Sources: Determine where data will be sourced from (e.g., Ensuring Time Consistency: Ensure that the data is organized chronologically, as time order is crucial for time series analysis. This is vital for agriculture, disaster management, and event planning.
Similar Audio: Audio recordings of the same event or sound but with different microphone placements or background noise. It would help to improve the process in future by creating a clear audit trail of how duplicate records are identified and handled throughout the datapipeline.
You don’t need massive data sets because “dataquality scales better than data size.” ” Small models with good data are better than massive models because “in the long run, the best models are the ones which can be iterated upon quickly.”
Internally within Netflix’s engineering team, Meson was built to manage, orchestrate, schedule, and execute workflows within ML/Datapipelines. Meson managed the lifecycle of ML pipelines, providing functionality such as recommendations and content analysis, and leveraged the Single Leader Architecture.
Monday’s sessions will cover a wide range of topics, from Generative AI and LLMs to MLOps and Data Visualization. Finally, get ready for some All Hallows Eve fun with Halloween Data After Dark , featuring a costume contest, candy, and more. There will also be an in-person career expo where you can find your next job in data science!
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content