This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
With the increasing use of large models, requiring a large number of accelerated compute instances, observability plays a critical role in ML operations, empowering you to improve performance, diagnose and fix failures, and optimize resource utilization. This data makes sure models are being trained smoothly and reliably.
Businesses are under pressure to show return on investment (ROI) from AI use cases, whether predictive machine learning (ML) or generative AI. Only 54% of ML prototypes make it to production, and only 5% of generative AI use cases make it to production. Using SageMaker, you can build, train and deploy ML models.
From data processing to quick insights, robust pipelines are a must for any ML system. Often the Data Team, comprising Data and ML Engineers , needs to build this infrastructure, and this experience can be painful. However, efficient use of ETL pipelines in ML can help make their life much easier.
Organizations require reliable data for robust AI models and accurate insights, yet the current technology landscape presents unparalleled dataquality challenges. ETL/ELT tools typically have two components: a design time (to design data integration jobs) and a runtime (to execute data integration jobs).
Key skills and qualifications for machine learning engineers include: Strong programming skills: Proficiency in programming languages such as Python, R, or Java is essential for implementing machine learning algorithms and building datapipelines.
Alignment to other tools in the organization’s tech stack Consider how well the MLOps tool integrates with your existing tools and workflows, such as data sources, data engineering platforms, code repositories, CI/CD pipelines, monitoring systems, etc. and Pandas or Apache Spark DataFrames.
Summary: This blog explains how to build efficient datapipelines, detailing each step from data collection to final delivery. Introduction Datapipelines play a pivotal role in modern data architecture by seamlessly transporting and transforming raw data into valuable insights.
The growth of the AI and Machine Learning (ML) industry has continued to grow at a rapid rate over recent years. Hidden Technical Debt in Machine Learning Systems More money, more problems — Rise of too many ML tools 2012 vs 2023 — Source: Matt Turck People often believe that money is the solution to a problem. Spark, Flink, etc.)
As such, the quality of their data can make or break the success of the company. This article will guide you through the concept of a dataquality framework, its essential components, and how to implement it effectively within your organization. What is a dataquality framework?
Jacomo Corbo is a Partner and Chief Scientist, and Bryan Richardson is an Associate Partner and Senior Data Scientist, for QuantumBlack AI by McKinsey. They presented “Automating DataQuality Remediation With AI” at Snorkel AI’s The Future of Data-Centric AI Summit in 2022. The macro view will not be surprising.
Jacomo Corbo is a Partner and Chief Scientist, and Bryan Richardson is an Associate Partner and Senior Data Scientist, for QuantumBlack AI by McKinsey. They presented “Automating DataQuality Remediation With AI” at Snorkel AI’s The Future of Data-Centric AI Summit in 2022. The macro view will not be surprising.
Jacomo Corbo is a Partner and Chief Scientist, and Bryan Richardson is an Associate Partner and Senior Data Scientist, for QuantumBlack AI by McKinsey. They presented “Automating DataQuality Remediation With AI” at Snorkel AI’s The Future of Data-Centric AI Summit in 2022. The macro view will not be surprising.
We are excited to announce the launch of Amazon DocumentDB (with MongoDB compatibility) integration with Amazon SageMaker Canvas , allowing Amazon DocumentDB customers to build and use generative AI and machine learning (ML) solutions without writing code. On the Analyses tab, choose DataQuality and Insights Report.
Evaluating ML model performance is essential for ensuring the reliability, quality, accuracy and effectiveness of your ML models. In this blog post, we dive into all aspects of ML model performance: which metrics to use to measure performance, best practices that can help and where MLOps fits in.
Key Takeaways Dataquality ensures your data is accurate, complete, reliable, and up to date – powering AI conclusions that reduce costs and increase revenue and compliance. Data observability continuously monitors datapipelines and alerts you to errors and anomalies. What does “quality” data mean, exactly?
In this post, you will learn about the 10 best datapipeline tools, their pros, cons, and pricing. A typical datapipeline involves the following steps or processes through which the data passes before being consumed by a downstream process, such as an ML model training process.
Its goal is to help with a quick analysis of target characteristics, training vs testing data, and other such data characterization tasks. Apache Superset GitHub | Website Apache Superset is a must-try project for any ML engineer, data scientist, or data analyst. You can watch it on demand here.
Previously, he was a Data & Machine Learning Engineer at AWS, where he worked closely with customers to develop enterprise-scale data infrastructure, including data lakes, analytics dashboards, and ETL pipelines. He specializes in designing, building, and optimizing large-scale data solutions.
The 4 Gen AI Architecture Pipelines The four pipelines are: 1. The DataPipeline The datapipeline is the foundation of any AI system. It's responsible for collecting and ingesting the data from various external sources, processing it and managing the data.
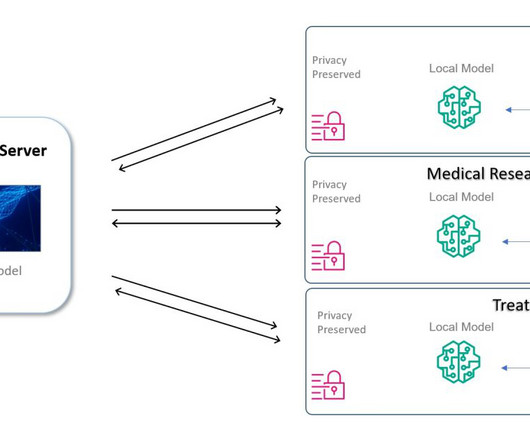
Medical data restrictions You can use machine learning (ML) to assist doctors and researchers in diagnosis tasks, thereby speeding up the process. However, the datasets needed to build the ML models and give reliable results are sitting in silos across different healthcare systems and organizations.
Data observability is a key element of data operations (DataOps). It enables a big-picture understanding of the health of your organization’s data through continuous AI/ML-enabled monitoring – detecting anomalies throughout the datapipeline and preventing data downtime.
Over time, we called the “thing” a data catalog , blending the Google-style, AI/ML-based relevancy with more Yahoo-style manual curation and wikis. Thus was born the data catalog. In our early days, “people” largely meant data analysts and business analysts. ML and DataOps teams). datapipelines) to support.
Data Scientists and AI experts: Historically we have seen Data Scientists build and choose traditional ML models for their use cases. Data Scientists will typically help with training, validating, and maintaining foundation models that are optimized for data tasks.
Systems and data sources are more interconnected than ever before. A broken datapipeline might bring operational systems to a halt, or it could cause executive dashboards to fail, reporting inaccurate KPIs to top management. Old-school methods of managing dataquality are no longer sufficient.
Best Practices for ETL Efficiency Maximising efficiency in ETL (Extract, Transform, Load) processes is crucial for organisations seeking to harness the power of data. Implementing best practices can improve performance, reduce costs, and improve dataquality. It also makes predictions for the future of ETL processes.
Unfortunately accessing data across various locations and file types and then operationalizing that data for AI usage has traditionally been a painfully manual, time-consuming, and costly process. Ahmad Khan, Head of AI/ML Strategy at Snowflake, discusses the challenges of operationalizing ML in a recent talk.
Unfortunately accessing data across various locations and file types and then operationalizing that data for AI usage has traditionally been a painfully manual, time-consuming, and costly process. Ahmad Khan, Head of AI/ML Strategy at Snowflake, discusses the challenges of operationalizing ML in a recent talk.
An enterprise data catalog does all that a library inventory system does – namely streamlining data discovery and access across data sources – and a lot more. For example, data catalogs have evolved to deliver governance capabilities like managing dataquality and data privacy and compliance.
As companies strive to leverage AI/ML, location intelligence, and cloud analytics into their portfolio of tools, siloed mainframe data often stands in the way of forward momentum. Insufficient skills, limited budgets, and poor dataquality also present significant challenges.
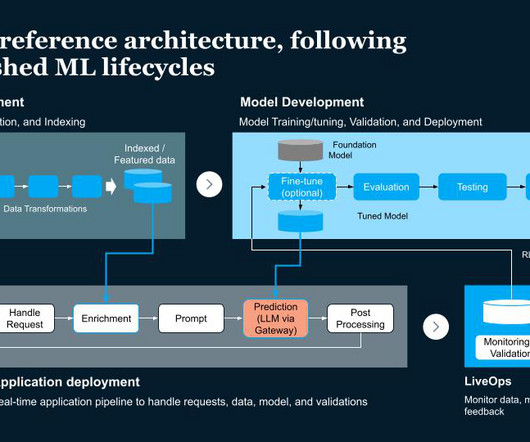
Building MLOpsPedia This demo on Github shows how to fine tune an LLM domain expert and build an ML application Read More Building Gen AI for Production The ability to successfully scale and drive adoption of a generative AI application requires a comprehensive enterprise approach. Let’s dive into the data management pipeline.
They are characterized by their enormous size, complexity, and the vast amount of data they process. These elements need to be taken into consideration when managing, streamlining and deploying LLMs in MLpipelines, hence the specialized discipline of LLMOps. Continuous monitoring of resources, data, and metrics.
To help, phData designed and implemented AI-powered datapipelines built on the Snowflake AI Data Cloud , Fivetran, and Azure to automate invoice processing. Migrations from legacy on-prem systems to cloud data platforms like Snowflake and Redshift. This is where AI truly shines.
Managing unstructured data is essential for the success of machine learning (ML) projects. Without structure, data is difficult to analyze and extracting meaningful insights and patterns is challenging. This article will discuss managing unstructured data for AI and ML projects. What is Unstructured Data?
Horizon addresses key aspects of data governance, including: Compliance Security Access Privacy Interoperability Throughout the remainder of this blog, we will dive deeper into each of the above components and take a look at the ways in which Horizon can help. We will begin with compliance.
It is really well done, but as someone who spends all my time working on data governance and privacy, that top left section of “contextual data → datapipelines” is missing something: data governance.
This includes the tools and techniques we used to streamline the ML model development and deployment processes, as well as the measures taken to monitor and maintain models in a production environment. Costs: Oftentimes, cost is the most important aspect of any ML model deployment. This includes dataquality, privacy, and compliance.
An MLOps platform enables streamlining and automating the entire ML lifecycle, from model development and training to deployment and monitoring. When it comes to scaling your MLOps operations, a high-quality, reliable and effective MLOps platform is essential for growth.
“You need to find a place to park your data. It needs to be optimized for the type of data and the format of the data you have,” he said. By optimizing every part of the datapipeline, he said, “You will, as a result, get your models to market faster.” Catch the sessions you missed!
“You need to find a place to park your data. It needs to be optimized for the type of data and the format of the data you have,” he said. By optimizing every part of the datapipeline, he said, “You will, as a result, get your models to market faster.” Catch the sessions you missed!
Today’s data management and analytics products have infused artificial intelligence (AI) and machine learning (ML) algorithms into their core capabilities. These modern tools will auto-profile the data, detect joins and overlaps, and offer recommendations. 2) Line of business is taking a more active role in data projects.
Piyush Puri: Please join me in welcoming to the stage our next speakers who are here to talk about data-centric AI at Capital One, the amazing team who may or may not have coined the term, “what’s in your wallet.” What can get less attention is the foundational element of what makes AI and ML shine. That’s data.
Piyush Puri: Please join me in welcoming to the stage our next speakers who are here to talk about data-centric AI at Capital One, the amazing team who may or may not have coined the term, “what’s in your wallet.” What can get less attention is the foundational element of what makes AI and ML shine. That’s data.
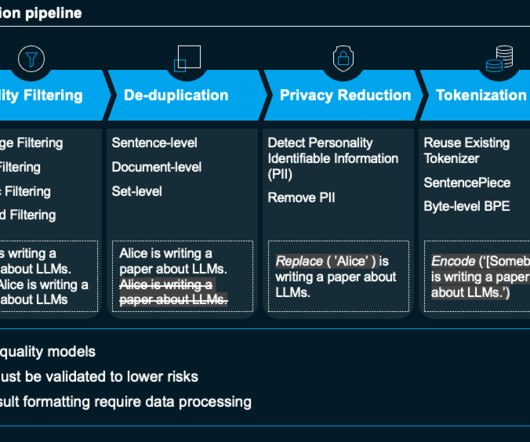
In today's data-driven world, machine learning practitioners often face a critical yet underappreciated challenge: duplicate data management. A massive amount of diverse data powers today's ML models. Audio data Similar to Image and Text data, Audio file deduplication is an interesting area to work on.
Data scientists use data-driven approaches to enable AI systems to make better predictions, optimize decision-making, and uncover hidden patterns that ultimately drive innovation and improve performance across various domains. You don’t need massive data sets because “dataquality scales better than data size.”
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content