

Innovations in Analytics: Elevating Data Quality with GenAI
Towards AI
OCTOBER 31, 2024
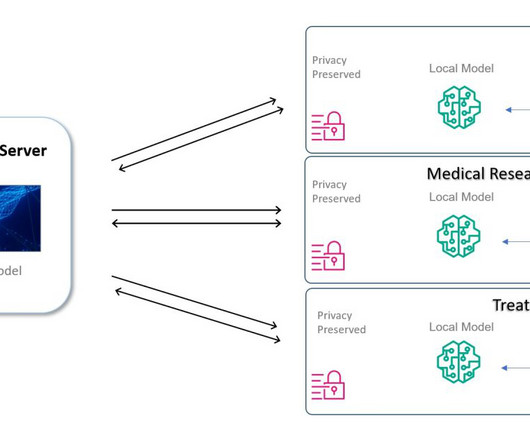
Data analytics has become a key driver of commercial success in recent years. The ability to turn large data sets into actionable insights can mean the difference between a successful campaign and missed opportunities. Flipping the paradigm: Using AI to enhance data quality What if we could change the way we think about data quality?





















Let's personalize your content