This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the DataScience Blogathon. Introduction Data acclimates to countless shapes and sizes to complete its journey from a source to a destination. The post Developing an End-to-End Automated DataPipeline appeared first on Analytics Vidhya.
This article was published as a part of the DataScience Blogathon. Introduction These days companies seem to seek ways to integrate data from multiple sources to earn a competitive advantage over other businesses. The post Getting Started with DataPipeline appeared first on Analytics Vidhya.
In this sponsored post, Devika Garg, PhD, Senior Solutions Marketing Manager for Analytics at Pure Storage, believes that in the current era of data-driven transformation, IT leaders must embrace complexity by simplifying their analytics and data footprint.
This article was published as a part of the DataScience Blogathon. The post All About DataPipeline and Kafka Basics appeared first on Analytics Vidhya. Introduction on Kafka In old days, people would go to collect water from different resources available nearby based on their needs.
Also: How I Redesigned over 100 ETL into ELT DataPipelines; Where NLP is heading; Don’t Waste Time Building Your DataScience Network; Data Scientists: How to Sell Your Project and Yourself.
ChatGPT plugins can be used to extend the capabilities of ChatGPT in a variety of ways, such as: Accessing and processing external data Performing complex computations Using third-party services In this article, we’ll dive into the top 6 ChatGPT plugins tailored for datascience.
This article was published as a part of the DataScience Blogathon. Introduction In this blog, we will explore one interesting aspect of the pandas read_csv function, the Python Iterator parameter, which can be used to read relatively large input data.
ArticleVideo Book This article was published as a part of the DataScience Blogathon Introduction Apache Spark is a framework used in cluster computing environments. The post Building a DataPipeline with PySpark and AWS appeared first on Analytics Vidhya.
This article was published as a part of the DataScience Blogathon. Introduction ETL pipelines can be built from bash scripts. You will learn about how shell scripting can implement an ETL pipeline, and how ETL scripts or tasks can be scheduled using shell scripting. What is shell scripting?
Continuous Integration and Continuous Delivery (CI/CD) for DataPipelines: It is a Game-Changer with AnalyticsCreator! The need for efficient and reliable datapipelines is paramount in datascience and data engineering. They transform data into a consistent format for users to consume.
This article was published as a part of the DataScience Blogathon. Dale Carnegie” Apache Kafka is a Software Framework for storing, reading, and analyzing streaming data. The post Build a Simple Realtime DataPipeline appeared first on Analytics Vidhya. Introduction “Learning is an active process.
Introduction The demand for data to feed machine learning models, datascience research, and time-sensitive insights is higher than ever thus, processing the data becomes complex. To make these processes efficient, datapipelines are necessary. appeared first on Analytics Vidhya.
Introduction Data is fuel for the IT industry and the DataScience Project in today’s online world. IT industries rely heavily on real-time insights derived from streaming data sources. Handling and processing the streaming data is the hardest work for Data Analysis.
This article was published as a part of the DataScience Blogathon. Introduction With the development of data-driven applications, the complexity of integrating data from multiple simple decision-making sources is often considered a significant challenge.
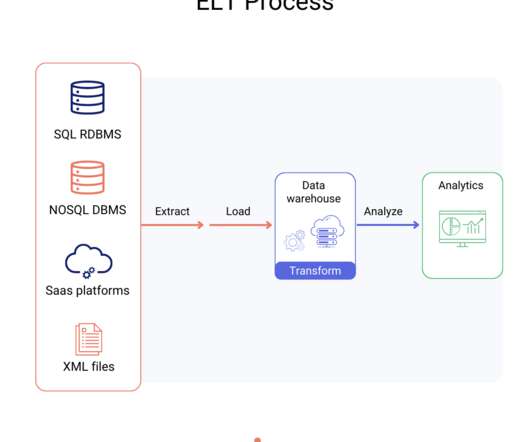
This article was published as a part of the DataScience Blogathon. Introduction ETL is the process that extracts the data from various data sources, transforms the collected data, and loads that data into a common data repository. Azure Data Factory […]. Azure Data Factory […].
While many ETL tools exist, dbt (data build tool) is emerging as a game-changer. This article dives into the core functionalities of dbt, exploring its unique strengths and how […] The post Transforming Your DataPipeline with dbt(data build tool) appeared first on Analytics Vidhya.
ArticleVideo Book This article was published as a part of the DataScience Blogathon Introduction In this article we will be discussing Binary Image Classification. The post Image Classification with TensorFlow : Developing the DataPipeline (Part 1) appeared first on Analytics Vidhya.
As the role of the data engineer continues to grow in the field of datascience, so are the many tools being developed to support wrangling all that data. Five of these tools are reviewed here (along with a few bonus tools) that you should pay attention to for your datapipeline work.
Don’t Waste Time Building Your DataScience Network; 19 DataScience Project Ideas for Beginners; How I Redesigned over 100 ETL into ELT DataPipelines; Anecdotes from 11 Role Models in Machine Learning; The Ultimate Guide To Different Word Embedding Techniques In NLP.
This article was published as a part of the DataScience Blogathon. Introduction to Apache Airflow “Apache Airflow is the most widely-adopted, open-source workflow management platform for data engineering pipelines. Most organizations today with complex datapipelines to […].
Also: How I Redesigned over 100 ETL into ELT DataPipelines; Where NLP is heading; Don’t Waste Time Building Your DataScience Network; Data Scientists: How to Sell Your Project and Yourself.
The original Cookiecutter DataScience (CCDS) was published over 8 years ago. The goal was, as the tagline states “a logical, reasonably standardized but flexible project structure for datascience.” That said, in the past 5 years, a lot has changed in datascience tooling and MLOps. Badges are delightful.
Don’t Waste Time Building Your DataScience Network; 19 DataScience Project Ideas for Beginners; How I Redesigned over 100 ETL into ELT DataPipelines; Anecdotes from 11 Role Models in Machine Learning; The Ultimate Guide To Different Word Embedding Techniques In NLP.
This article was published as a part of the DataScience Blogathon. Introduction When creating datapipelines, Software Engineers and Data Engineers frequently work with databases using Database Management Systems like PostgreSQL.
DataScience Dojo is offering Airbyte for FREE on Azure Marketplace packaged with a pre-configured web environment enabling you to quickly start the ELT process rather than spending time setting up the environment. Manual full refresh: Re-syncs all your data to start again whenever you want.
In contemporary times, datascience has emerged as a substantial and progressively expanding domain that has an impact on virtually every sphere of human ingenuity: be it commerce, technology, healthcare, education, governance, and beyond. This piece will concentrate on the elemental constituents constituting datascience.
Summary: “DataScience in a Cloud World” highlights how cloud computing transforms DataScience by providing scalable, cost-effective solutions for big data, Machine Learning, and real-time analytics. Advancements in data processing, storage, and analysis technologies power this transformation.
These experiences facilitate professionals from ingesting data from different sources into a unified environment and pipelining the ingestion, transformation, and processing of data to developing predictive models and analyzing the data by visualization in interactive BI reports.
This very superpower is emerging today through open datascience — the use of publicly available data and tools by everyday citizens to drive social change. Just ten years ago, the idea of ordinary people leveraging datascience for humanitarian causes would have seemed like wishful thinking.
Latency While streaming promises real-time processing, it can introduce latency, particularly with large or complex data streams. To reduce delays, you may need to fine-tune your datapipeline, optimize processing algorithms, and leverage techniques like batching and caching for better responsiveness.
Datascience bootcamps are intensive short-term educational programs designed to equip individuals with the skills needed to enter or advance in the field of datascience. They cover a wide range of topics, ranging from Python, R, and statistics to machine learning and data visualization.
Accurate and secure data can help to streamline software engineering processes and lead to the creation of more powerful AI tools, but it has become a challenge to maintain the quality of the expansive volumes of data needed by the most advanced AI models. Featured image credit: Shubham Dhage/Unsplash
Introduction Databricks Lakehouse Monitoring allows you to monitor all your datapipelines – from data to features to ML models – without additional too.
This post is a bitesize walk-through of the 2021 Executive Guide to DataScience and AI — a white paper packed with up-to-date advice for any CIO or CDO looking to deliver real value through data. Automation Automating datapipelines and models ➡️ 6. Team Building the right datascience team is complex.
Are you interested in a career in datascience? The Bureau of Labor Statistics reports that there are over 105,000 data scientists in the United States. The average data scientist earns over $108,000 a year. Data Scientist. This is the best time ever to pursue this career track. Machine Learning Engineer.
Introduction Datascience is a practical subject that the experts can best explain in the field. To provide our community with a better understanding of how different elements of the subject are used in different domains, Analytics Vidhya has launched our DataHour sessions.
Modern datapipeline platform provider Matillion today announced at Snowflake Data Cloud Summit 2024 that it is bringing no-code Generative AI (GenAI) to Snowflake users with new GenAI capabilities and integrations with Snowflake Cortex AI, Snowflake ML Functions, and support for Snowpark Container Services.
This article was published as a part of the DataScience Blogathon. The post Machine learning Pipeline in Pyspark appeared first on Analytics Vidhya. Introduction In this article, we will learn about machine learning using Spark. Our previous articles discussed Spark databases, installation, and working of Spark in Python.
This article was published as a part of the DataScience Blogathon. Introduction A deep learning task typically entails analyzing an image, text, or table of data (cross-sectional and time-series) to produce a number, label, additional text, additional images, or a mix of these.
DataScience Dojo is offering Memphis broker for FREE on Azure Marketplace preconfigured with Memphis, a platform that provides a P2P architecture, scalability, storage tiering, fault-tolerance, and security to provide real-time processing for modern applications suitable for large volumes of data. Are you already feeling tired?
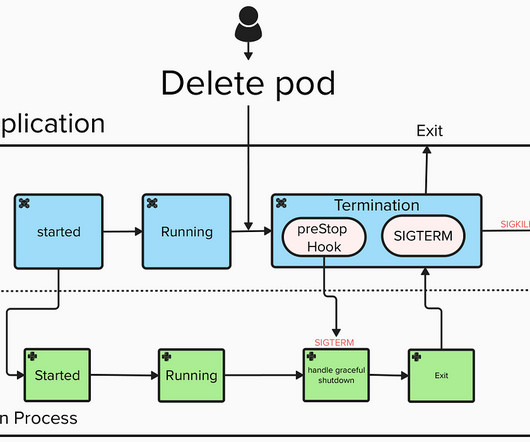
Graceful External Termination: Handling Pod Deletions in Kubernetes Data Ingestion and Streaming Jobs When running big-datapipelines in Kubernetes, especially streaming jobs, its easy to overlook how these jobs deal with termination. If not handled correctly, this can lead to locks, data issues, and a negative user experience.
Here’s what we found for both skills and platforms that are in demand for data scientist jobs. DataScience Skills and Competencies Aside from knowing particular frameworks and languages, there are various topics and competencies that any data scientist should know. Joking aside, this does infer particular skills.
Though you may encounter the terms “datascience” and “data analytics” being used interchangeably in conversations or online, they refer to two distinctly different concepts. Meanwhile, data analytics is the act of examining datasets to extract value and find answers to specific questions.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content