This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom datapipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their datawarehouse for more comprehensive analysis.
The blog post explains how the Internal Cloud Analytics team leveraged cloud resources like Code-Engine to improve, refine, and scale the datapipelines. Background One of the Analytics teams tasks is to load data from multiple sources and unify it into a datawarehouse.
Organizations can search for PII using methods such as keyword searches, pattern matching, data loss prevention tools, machine learning (ML), metadata analysis, data classification software, optical character recognition (OCR), document fingerprinting, and encryption.
The raw data can be fed into a database or datawarehouse. An analyst can examine the data using business intelligence tools to derive useful information. . To arrange your data and keep it raw, you need to: Make sure the datapipeline is simple so you can easily move data from point A to point B.
Better documentation with more examples , clearer explanations of the choices and tools, and a more modern look and feel. Find the latest at [link] (the old documentation will redirect here shortly). Project documentation ¶ As data science codebases live longer, code is often refactored into a package.
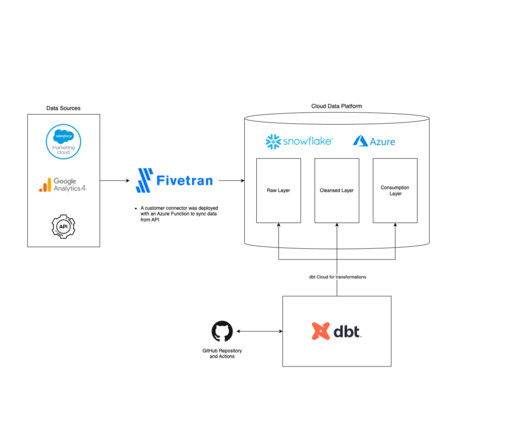
Examples of data sources and destinations include: Shopify Google Analytics Snowflake Data Cloud Oracle Salesforce Fivetran’s mission is to, “make access to data as easy as electricity” – so for the last 10 years, they have developed their platform into a leader in the cloud-based ELT market. What is Fivetran Used For?
Introduction ETL plays a crucial role in Data Management. This process enables organisations to gather data from various sources, transform it into a usable format, and load it into datawarehouses or databases for analysis. Loading The transformed data is loaded into the target destination, such as a datawarehouse.
Great Expectations GitHub | Website Great Expectations (GX) helps data teams build a shared understanding of their data through quality testing, documentation, and profiling. With Great Expectations , data teams can express what they “expect” from their data using simple assertions.
In July 2023, Matillion launched their fully SaaS platform called Data Productivity Cloud, aiming to create a future-ready, everyone-ready, and AI-ready environment that companies can easily adopt and start automating their datapipelines coding, low-coding, or even no-coding at all. Or would you even go to that directly?
It includes processes that trace and document the origin of data, models and associated metadata and pipelines for audits. How to scale AL and ML with built-in governance A fit-for-purpose data store built on an open lakehouse architecture allows you to scale AI and ML while providing built-in governance tools.
The modern data stack is a combination of various software tools used to collect, process, and store data on a well-integrated cloud-based data platform. It is known to have benefits in handling data due to its robustness, speed, and scalability. A typical modern data stack consists of the following: A datawarehouse.
Oracle – The Oracle connector, a database-type connector, enables real-time data transfer of large volumes of data from on-premises or cloud sources to the destination of choice, such as a cloud data lake or datawarehouse.
The ultimate need for vast storage spaces manifests in datawarehouses: specialized systems that aggregate data coming from numerous sources for centralized management and consistency. In this article, you’ll discover what a Snowflake datawarehouse is, its pros and cons, and how to employ it efficiently.
Salesforce Sync Out is a crucial tool that enables businesses to transfer data from their Salesforce platform to external systems like Snowflake, AWS S3, and Azure ADLS. Warehouse for loading the data (start with XSMALL or SMALL warehouses). See the Salesforce documentation for more information. Click Next.
Also Read: Top 10 Data Science tools for 2024. It is a process for moving and managing data from various sources to a central datawarehouse. This process ensures that data is accurate, consistent, and usable for analysis and reporting. This process helps organisations manage large volumes of data efficiently.
In addition, MLOps practices like building data, experting tracking, versioning, artifacts and others, also need to be part of the GenAI productization process. For example, when indexing a new version of a document, it’s important to take care of versioning in the ML pipeline. This helps cleanse the data.
Data Vault - Data Lifecycle Architecturally, let’s understand the data lifecycle in the data vault into the following layers, which play a key role in choosing the right pattern and tools to implement. Data Acquisition: Extracting data from source systems and making it accessible.
Data integration is essentially the Extract and Load portion of the Extract, Load, and Transform (ELT) process. Data ingestion involves connecting your data sources, including databases, flat files, streaming data, etc, to your datawarehouse. Snowflake provides native ways for data ingestion.
Securing AI models and their access to data While AI models need flexibility to access data across a hybrid infrastructure, they also need safeguarding from tampering (unintentional or otherwise) and, especially, protected access to data. This allows for a high degree of transparency and auditability.
Matillion’s Data Productivity Cloud is a versatile platform designed to increase the productivity of data teams. It provides a unified platform for creating and managing datapipelines that are effective for both coders and non-coders. Check out the API documentation for our sample.
These encoder-only architecture models are fast and effective for many enterprise NLP tasks, such as classifying customer feedback and extracting information from large documents. While they require task-specific labeled data for fine tuning, they also offer clients the best cost performance trade-off for non-generative use cases.
Fivetran includes features like data movement, transformations, robust security, and compatibility with third-party tools like DBT, Airflow, Atlan, and more. Its seamless integration with popular cloud datawarehouses like Snowflake can provide the scalability needed as your business grows.
dbt offers a SQL-first transformation workflow that lets teams build data transformation pipelines while following software engineering best practices like CI/CD, modularity, and documentation. Aside from migrations, Data Source is also great for data quality checks and can generate datapipelines.
Imagine you wanted to build a dbt project for your existing source datawarehouse in your migration to Snowflake. You could leverage the data source tool to profile your source, apply a template against the generated metadata, and automatically create a dbt project with models for each table!
Data can then be labeled programmatically using a data-centric AI workflow in Snorkel Flow to quickly generate high-quality training sets over complex, highly variable data. Snorkel Flow includes templates to classify and extract information from native PDFs, richly formatted documents, HTML data, conversational text, and more.
Data can then be labeled programmatically using a data-centric AI workflow in Snorkel Flow to quickly generate high-quality training sets over complex, highly variable data. Snorkel Flow includes templates to classify and extract information from native PDFs, richly formatted documents, HTML data, conversational text, and more.
It simply wasn’t practical to adopt an approach in which all of an organization’s data would be made available in one central location, for all-purpose business analytics. To speed analytics, data scientists implemented pre-processing functions to aggregate, sort, and manage the most important elements of the data.
It’s common to have terabytes of data in most datawarehouses, data quality monitoring is often challenging and cost-intensive due to dependencies on multiple tools and eventually ignored. To assign the DMF to the table, we must first add a data metric schedule to the table CUSTOMERS.
One of the easiest ways for Snowflake to achieve this is to have analytics solutions query their datawarehouse in real-time (also known as DirectQuery). For more information on composite models, check out Microsoft’s official documentation. This ensures the maximum amount of Snowflake consumption possible.
Operational Risks: Uncover operational risks such as data loss or failures in the event of an unforeseen outage or disaster. Performance Optimization: Locate and fix bottlenecks in your datapipelines so that you can get the most out of your Snowflake investment.
Datapipeline orchestration. Moving/integrating data in the cloud/data exploration and quality assessment. Similar to a datawarehouse schema, this prep tool automates the development of the recipe to match. Edge computing can be decentralized from on-premises, cellular, data centers, or the cloud.
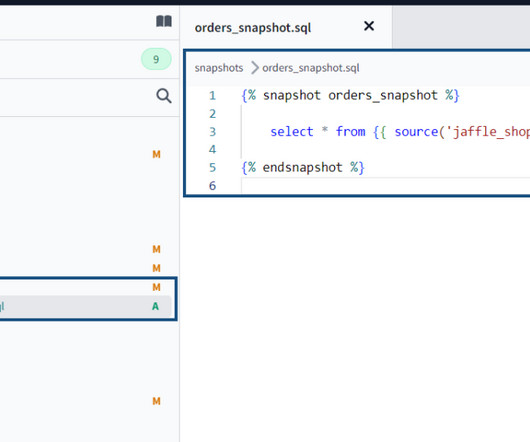
Snapshots are basic select queries that transform into tables within a datawarehouse. This will execute only given snapshots and create SCD Type-2 tables In your target datawarehouse. Conclusion dbt snapshot is an important feature that allows you to record changes within your data as it evolves.
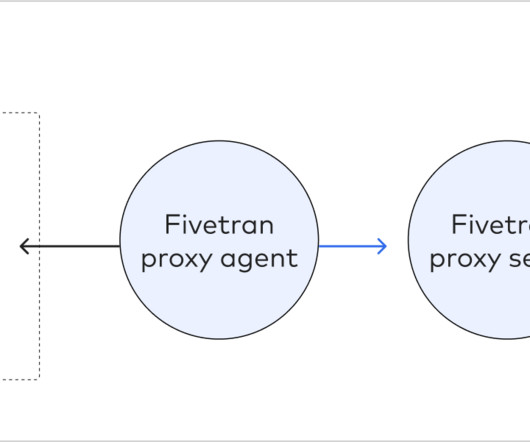
The on-premise agent is responsible for sending data to Fivetran, which is then processed and loaded into the destination. You can find more information about them in their official documentation. Speed: The agent on the source database will filter the data before sending it through the datapipeline.
There are other options you can place, and as usual, I suggest you to reference the official documentation to learn more. In case of complex datapipelines, a combination of Materialized Views, Stored Procedures, and Scheduled Queries could be a better choice than to solely rely on Scheduled Queries by itself.
Data Modeling, dbt has gradually emerged as a powerful tool that largely simplifies the process of building and handling datapipelines. dbt is an open-source command-line tool that allows data engineers to transform, test, and document the data into one single hub which follows the best practices of software engineering.
It is particularly popular among data engineers as it integrates well with modern datapipelines (e.g., Source: [link] Monte Carlo is a code-free data observability platform that focuses on data reliability across datapipelines. It integrates well with modern data engineering pipelines (e.g.,
Programming Languages: Proficiency in programming languages like Python or R is advantageous for performing advanced data analytics, implementing statistical models, and building datapipelines. BI Developer Skills Required To excel in this role, BI Developers need to possess a range of technical and soft skills.
Documentation: Keep detailed documentation of the deployed model, including its architecture, training data, and performance metrics, so that it can be understood and managed effectively. ETL usually stands for “Extract, Transform and Load,” and it refers to a process in data warehousing.
The platform’s integration with Azure services ensures a scalable and secure environment for Data Science projects. Azure Synapse Analytics Previously known as Azure SQL DataWarehouse , Azure Synapse Analytics offers a limitless analytics service that combines big data and data warehousing.
I have checked the AWS S3 bucket and Snowflake tables for a couple of days and the Datapipeline is working as expected. The scope of this article is quite big, we will exercise the core steps of data science, let's get started… Project Layout Here are the high-level steps for this project.
Structuring the dbt Project The most important aspect of any dbt project is its structural design, which organizes project files and code in a way that supports scalability for large datawarehouses. Documentation: Document coverage: It calculates the percentage of models that have descriptions attached to them.
When needed, the system can access an ODAP datawarehouse to retrieve additional information. Document management Documents are securely stored in Amazon S3, and when new documents are added, a Lambda function processes them into chunks.
With the birth of cloud datawarehouses, data applications, and generative AI , processing large volumes of data faster and cheaper is more approachable and desired than ever. First up, let’s dive into the foundation of every Modern Data Stack, a cloud-based datawarehouse.
With all this packaged into a well-governed platform, Snowflake continues to set the standard for data warehousing and beyond. Snowflake supports data sharing and collaboration across organizations without the need for complex datapipelines. Dataiku and Snowflake: A Good Combo?
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content