This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction Data acclimates to countless shapes and sizes to complete its journey from a source to a destination. Be it a streaming job or a batch job, ETL and ELT are irreplaceable. Before designing an ETL job, choosing optimal, performant, and cost-efficient tools […].
Introduction ETL is the process that extracts the data from various data sources, transforms the collected data, and loads that data into a common data repository. Azure Data Factory […]. The post Building an ETLDataPipeline Using Azure Data Factory appeared first on Analytics Vidhya.
Continuous Integration and Continuous Delivery (CI/CD) for DataPipelines: It is a Game-Changer with AnalyticsCreator! The need for efficient and reliable datapipelines is paramount in data science and data engineering. They transform data into a consistent format for users to consume.
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom datapipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their datawarehouse for more comprehensive analysis.
The acronym ETL—Extract, Transform, Load—has long been the linchpin of modern data management, orchestrating the movement and manipulation of data across systems and databases. This methodology has been pivotal in data warehousing, setting the stage for analysis and informed decision-making.
By Santhosh Kumar Neerumalla , Niels Korschinsky & Christian Hoeboer Introduction This blogpost describes how to manage and orchestrate high volume Extract-Transform-Load (ETL) loads using a serverless process based on Code Engine. The source data is unstructured JSON, while the target is a structured, relational database.
Datapipelines automatically fetch information from various disparate sources for further consolidation and transformation into high-performing data storage. There are a number of challenges in data storage , which datapipelines can help address. The movement of data in a pipeline from one point to another.
The ETL process is defined as the movement of data from its source to destination storage (typically a DataWarehouse) for future use in reports and analyzes. The data is initially extracted from a vast array of sources before transforming and converting it to a specific format based on business requirements.
Data engineering tools are software applications or frameworks specifically designed to facilitate the process of managing, processing, and transforming large volumes of data. Essential data engineering tools for 2023 Top 10 data engineering tools to watch out for in 2023 1.
Introduction Azure data factory (ADF) is a cloud-based data ingestion and ETL (Extract, Transform, Load) tool. The data-driven workflow in ADF orchestrates and automates data movement and data transformation.
However, efficient use of ETLpipelines in ML can help make their life much easier. This article explores the importance of ETLpipelines in machine learning, a hands-on example of building ETLpipelines with a popular tool, and suggests the best ways for data engineers to enhance and sustain their pipelines.
DataOps, which focuses on automated tools throughout the ETL development cycle, responds to a huge challenge for data integration and ETL projects in general. ETL projects are increasingly based on agile processes and automated testing. extract, transform, load) projects are often devoid of automated testing.
Summary: This guide explores the top list of ETL tools, highlighting their features and use cases. It provides insights into considerations for choosing the right tool, ensuring businesses can optimize their data integration processes for better analytics and decision-making. What is ETL? What are ETL Tools?
A datawarehouse is a centralized repository designed to store and manage vast amounts of structured and semi-structured data from multiple sources, facilitating efficient reporting and analysis. Begin by determining your data volume, variety, and the performance expectations for querying and reporting.
But with the sheer amount of data continually increasing, how can a business make sense of it? Robust datapipelines. What is a DataPipeline? A datapipeline is a series of processing steps that move data from its source to its destination. The answer?
Summary: This article explores the significance of ETLData in Data Management. It highlights key components of the ETL process, best practices for efficiency, and future trends like AI integration and real-time processing, ensuring organisations can leverage their data effectively for strategic decision-making.
Summary: The ETL process, which consists of data extraction, transformation, and loading, is vital for effective data management. Following best practices and using suitable tools enhances data integrity and quality, supporting informed decision-making. Introduction The ETL process is crucial in modern data management.
In this post, we will be particularly interested in the impact that cloud computing left on the modern datawarehouse. We will explore the different options for data warehousing and how you can leverage this information to make the right decisions for your organization. Understanding the Basics What is a DataWarehouse?
Summary: This blog explains how to build efficient datapipelines, detailing each step from data collection to final delivery. Introduction Datapipelines play a pivotal role in modern data architecture by seamlessly transporting and transforming raw data into valuable insights.
In the world of AI-driven data workflows, Brij Kishore Pandey, a Principal Engineer at ADP and a respected LinkedIn influencer, is at the forefront of integrating multi-agent systems with Generative AI for ETLpipeline orchestration. ETL ProcessBasics So what exactly is ETL? What is an Agent?
In the data analytics processes, choosing the right tools is crucial for ensuring efficiency and scalability. Two popular players in this area are Alteryx Designer and Matillion ETL , both offering strong solutions for handling data workflows with Snowflake Data Cloud integration.
Summary: Selecting the right ETL platform is vital for efficient data integration. Consider your business needs, compare features, and evaluate costs to enhance data accuracy and operational efficiency. Introduction In today’s data-driven world, businesses rely heavily on ETL platforms to streamline data integration processes.
Ed explained the differences between ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) processes, highlighting the advantages of the ELT approach in modern data environments. He introduced Airflow as a robust tool for orchestrating datapipelines and DBT for data transformation within datawarehouses.
Summary: Choosing the right ETL tool is crucial for seamless data integration. Top contenders like Apache Airflow and AWS Glue offer unique features, empowering businesses with efficient workflows, high data quality, and informed decision-making capabilities. Choosing the right ETL tool is crucial for smooth data management.
DataOps, which focuses on automated tools throughout the ETL development cycle, responds to a huge challenge for data integration and ETL projects in general. ETL projects are increasingly based on agile processes and automated testing. extract, transform, load) projects are often devoid of automated testing.
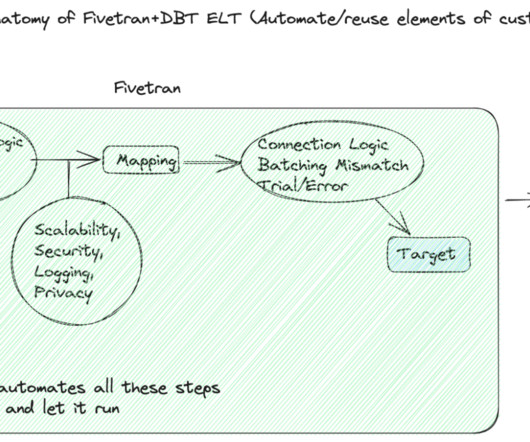
Fivetran is used by businesses to centralize data from various sources into a single, comprehensive datawarehouse. It allows organizations to easily connect their disparate data sources without having to manage any infrastructure. Building datapipelines manually is an expensive and time-consuming process.
This adaptability allows organizations to align their data integration efforts with distinct operational needs, enabling them to maximize the value of their data across diverse applications and workflows. This strategy helps organizations optimize data usage, expand into new markets, and increase revenue.
The success of any data initiative hinges on the robustness and flexibility of its big datapipeline. What is a DataPipeline? A traditional datapipeline is a structured process that begins with gathering data from various sources and loading it into a datawarehouse or data lake.
But with the sheer amount of data continually increasing, how can a business make sense of it? Robust datapipelines. What is a DataPipeline? A datapipeline is a series of processing steps that move data from its source to its destination. The answer?
Over the past few decades, the corporate data landscape has changed significantly. The shift from on-premise databases and spreadsheets to the modern era of cloud datawarehouses and AI/ LLMs has transformed what businesses can do with data. This is where Fivetran and the Modern Data Stack come in.
This data mesh strategy combined with the end consumers of your data cloud enables your business to scale effectively, securely, and reliably without sacrificing speed-to-market. What is a Cloud DataWarehouse? For example, most datawarehouse workloads peak during certain times, say during business hours.
In recent years, data engineering teams working with the Snowflake Data Cloud platform have embraced the continuous integration/continuous delivery (CI/CD) software development process to develop data products and manage ETL/ELT workloads more efficiently.
Best practices are a pivotal part of any software development, and data engineering is no exception. This ensures the datapipelines we create are robust, durable, and secure, providing the desired data to the organization effectively and consistently. What Are Matillion Jobs and Why Do They Matter?
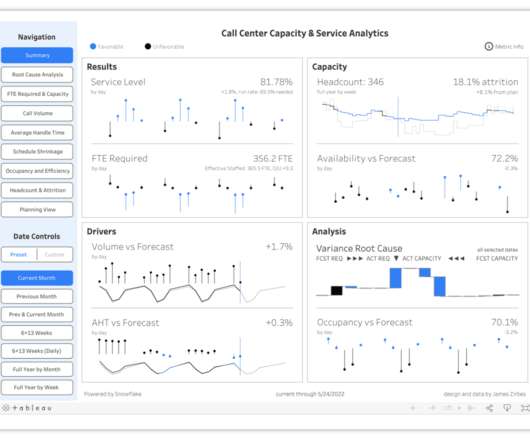
More and more businesses are looking to better leverage their outsourced call center data to make more data-driven decisions. To do this on your own, you would need to create a datawarehouse, optimize the reporting performance, and very clearly visualize the data. Another way to think of it is as Data Activation.
It is known to have benefits in handling data due to its robustness, speed, and scalability. A typical modern data stack consists of the following: A datawarehouse. Data ingestion/integration services. Reverse ETL tools. Data orchestration tools. A Note on the Shift from ETL to ELT.
In this post, you will learn about the 10 best datapipeline tools, their pros, cons, and pricing. A typical datapipeline involves the following steps or processes through which the data passes before being consumed by a downstream process, such as an ML model training process.
Cloud datawarehouses provide various advantages, including the ability to be more scalable and elastic than conventional warehouses. Can’t get to the data. All of this data might be overwhelming for engineers who struggle to pull in data sets quickly enough. Datapipeline maintenance.
Effective data governance enhances quality and security throughout the data lifecycle. What is Data Engineering? Data Engineering is designing, constructing, and managing systems that enable data collection, storage, and analysis. ETL is vital for ensuring data quality and integrity.
In July 2023, Matillion launched their fully SaaS platform called Data Productivity Cloud, aiming to create a future-ready, everyone-ready, and AI-ready environment that companies can easily adopt and start automating their datapipelines coding, low-coding, or even no-coding at all. Why Does it Matter?
For those unfamiliar with GIT or GIT practices, please refer Git for Business Users with Matillion DPC What is a Matillion Pipeline? A Matillion pipeline is a collection of jobs that extract, load, and transform (ETL/ELT) data from various sources into a target system, such as a cloud datawarehouse like Snowflake.
Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. They create datapipelines, ETL processes, and databases to facilitate smooth data flow and storage. Data Warehousing: Amazon Redshift, Google BigQuery, etc.
Understanding Fivetran Fivetran is a popular Software-as-a-Service platform that enables users to automate the movement of data and ETL processes across diverse sources to a target destination. For a longer overview, along with insights and best practices, please feel free to jump back to the previous blog.
This individual is responsible for building and maintaining the infrastructure that stores and processes data; the kinds of data can be diverse, but most commonly it will be structured and unstructured data. They’ll also work with software engineers to ensure that the data infrastructure is scalable and reliable.
The story is all too common – a business user requests some data, the data team creates/prioritizes a ticket, and said ticket is completed after some number of months (or weeks if you’re lucky) – just to have the data be wrong, and the whole process starts again. Those are scary for data teams to change.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content